摘要 在很多的人脸识别的应用中,有大量的人脸数据每个人有两张照片,一个是身份证照片,注册用的,还有一个是定点采集的照片。已有的方法大部分是用来处理有限的宽度(类别数)和足够的深度(每个类别有足够多的图像)。当遇到身份证和定点照这种数据集的时候,已有的方法就会遇到很多麻烦。本文中,我们提出了一个大规模双样本深度学习方法(LBL),用来处理身份证照和自拍照的人脸识别问题。为了处理每个类别只有两个样本的问题,我们提出了分类-验证-分类的训练策略,逐渐的提升模型的能力。另外,和一个支配原型softmax结合起来,使得训练可以应用在大规模的数据集上。我们将LBL用在一个超过200万人的数据集上。实验表明,我们的方法能够取得最佳的表现,验证了LBL在人脸识别上的有效性。
1. 介绍
人脸识别近年来发展很大,这要归功于深度学习结构,训练的策略和大量的数据。现有的方法都是集中在处理非限制场景的人脸识别,这些数据集常常人数有限,每个人有大量的照片。在现实应用中,有很多人证比对的场景。对比非限制场景人脸识别,人证比对有几个特点:
- 异构性:证件照和自拍照采集的途径不一样,证件照一般是限制场景的采集,干净的背景,正面照,光线充足,表情自然。自拍照一般是非限制场景,监控相机等。姿态,光照,表情,遮挡各不相同。更重要的是年龄的差距,身份证照和自拍照的年龄差距有时候会10~20年,这是最大的不同。
- 双样本数据:通常,人证比对的数据集是通过授权系统采集的,授权系统只能采集两张图像,一张证件照,一张自拍照。只有两张照片,很难很好的表达类内的多样性,这对双样本数据是个很大的问题。
- 大量的类别:人证比对的数据集往往会有非常多的类别,几百万甚至上亿,如何使用有限的GPU资源来训练那么大类别的数据,也是个麻烦的问题。
在现实场景中,我们要求很低的FAR(false accept rate),比如FAR=,为了达到这个目的,需要大的内间距离和内聚的内类距离。由于只有两张图像,所以没办法获取大量的内类的多样性,所以特征的可分性也会不好。还有,类别数非常大,如何使用有限的GPU设备来挖掘可分离的特征信息,也是个大问题。比如使用softmax的话,最后一个全连接层需要N个特征向量作为参数,N是类别数,N很大的时候,直接进行训练是不可行的。
本文中我们将人证比对的深度学习问题变成Large-scale Bisample Learning (LBL) 问题。训练数据有大量的类别,每个类别只有两张图像。为了解决类别的欠表达的问题,我们提出了改进的迁移学习模型,叫做Classification-Verification-Classification (CVC)。先在公开数据集上进行训练,然后再使用对比损失或者triplet loss进行finetune,然后再使用一个新的支配原型的softmax来进行大规模的分类,最后得到最好的模型。
CVC的最后一步使用了原型选择的策略来减小大规模分类的代价。我们发现,softmax的梯度只受很小的一个比例的类别支配,这些影响类别可以通过类别的近似很有效的识别出来。基于这个,我们创建了一个支配队列,每个类别可以记录相似的类别。通过这个队列,我们可以选出支配能力最强的类别出来预测这个类别。这个新的softmax可以只使用0.15%的类别,大大减小了计算资源的依赖。
我们在一个真实的人证比对数据集上评估我们的模型,我们在有限的计算资源上(4个TitanX)取得了state of the art的结果。另外,我们发布了1262个人的数据集作为公开的评估。
2. 相关的工作
2.1 基于深度学习的人脸识别
做人脸识别通常用的是两个方案:分类和验证。分类方案就是将每个人作为一个独立的类别进行分类,测试的时候,去掉最后的分类器,用顶层的特征作为人脸的特征表达。最常用的loss是softmax的loss。基于这个,center loss提出了学习一个类的中心来让同一类的特征更加的内聚。L2-softmax通过对特征加上一个L2的限制来提升欠表达的类别。normface对特征和权值同时进行归一化,large-margin softmax和GA-softmax通过增加类别之间的margin来让不同类别的特征更具区分性。AM-Softmax则专注于cosine距离的margin。通过这些方法,可以得到很好的特征表达,收敛也很快,泛化也很好。
另一方面,验证的方案优化的是样本之间的距离。主要方法是对比损失和triplet损失,还有一些triplet的变体,如lifted structured loss,N-pairs loss。使用验证的策略,模型的能力和一个minibatch中产生的图像对高度相关,图像对的数量又和minibatch的size相关,也和显存的大小相关。为了减小GPU显存的使用,smart sampling 在数据层就选取最优价值的样本,而不是在特征层选取。这个方法记忆了有最大loss的图像对,然后会有较大的几率选择这些图像对。
表1给出了通用的数据集和人证比对数据集之间的对比。可以看到,分布基本是相反的,人证比对数据集很宽(人数多)但是很浅(每个人的样本少),现有的方法效果并不好。

2.2 使用不充分的数据进行学习
Low-shot learning: 通过少量样本来学习新的类别的识别。通常来说小样本学习是通过迁移学习从一个适当的源领域迁移到目标领域。小样本学习和双样本学习的区别在于,小样本学习是个close set的问题,测试的数据也是从小样本数据集中来的,双样本学习则是个open set的问题,测试的数据是从来没有见过的。
Long-tail problem:这个问题表示,只有有限的类别出现的非常频繁,大部分的类别都是很少见的。深度学习模型在训练的时候,容易忽略long-tailed数据,同时忽略long-tailed类别。有一些方法,如重新采样的方法,让long-tailed的样本分布变得均匀,还有提出了range loss来平滑多的和少的类别,这个loss减少了最大的类内距离,增大了类别的中心间距。
2.3 非常多的类别分类
Extream Multi-label Learning 训练一个分类器,给一个样本标记上最相关的类别。当类别数量非常大的时候,会遇到计算上面的问题。为了解决计算的问题,有人提出了基于树的模型,还有基于嵌入的模型。
3. 大数据集双样本学习
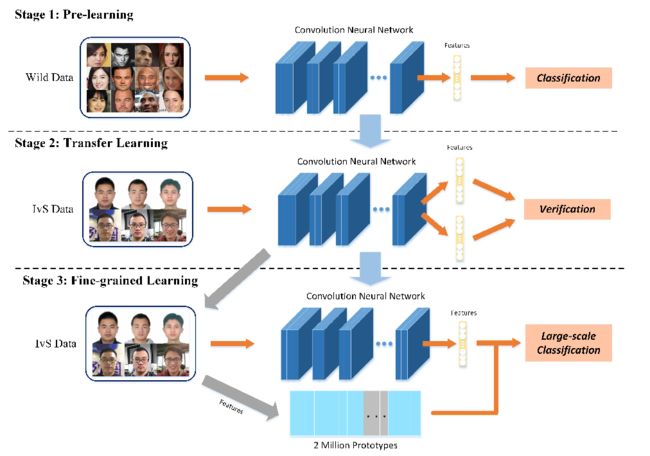
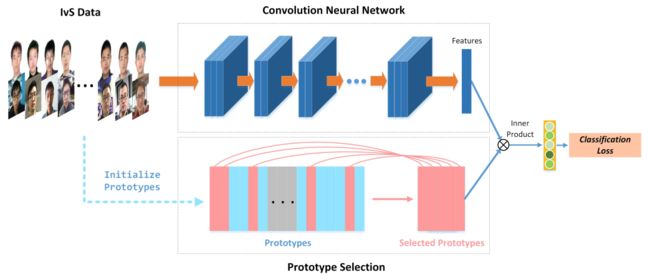
我们提出的这个方法是完整的基于大数据集双样本的深度学习的pipeline,我们会讨论分类的验证的策略,以及两者的优缺点来启发我们的方法。然后,我们展示了如何在大数据集双样本数据上训练。最后,我们开发了一个支配原型softmax来进行200万类的分类。图2,是我们的方法的概要。
3.1 问题公式化
目前有两种训练深度学习网络的策略,分类和验证。验证的策略优化的是样本之间的距离,比如对比损失和三元组损失。分类策略把每个人看作是一个独立的类别,然后训练一个多分类的模型。和验证策略相比,分类方法优化的是全局的某个人分类是否正确的问题。
首先,验证的策略提取一对特征:
其中,x是minibatch中提取的特征,M是batchsize,E是损失函数,用对比损失举个例子:
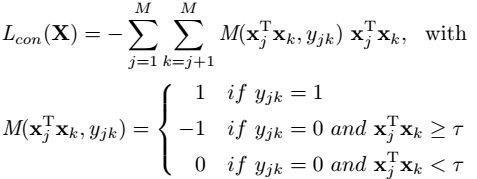
分类策略的优化策略:
其中,w是分类的权值矩阵。N是类别的数量。使用softmax举个例子:
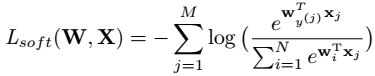
梯度的计算如下:
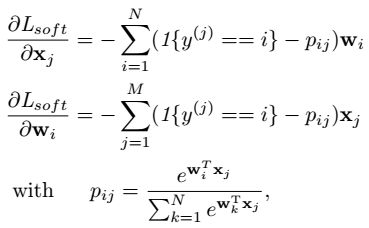
写成一个统一的式子:
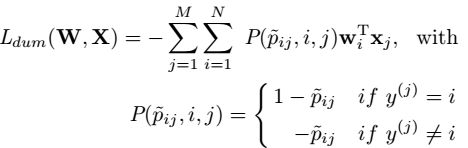
分类的损失中,实际上是使用了w中的向量来和输入的特征x组成对,对于这两个策略来说,分类策略组成了N×M个图像对,验证策略组成了M(M-1)/2个图像对,在实际的应用中,N远大于M,所以分类的策略实际上利用了更加多的图像对。但是,使用分类的策略需要大量的显存存储权值矩阵,如果有几百万类的话,计算就很困难了,而验证的策略则没有这个问题。我们认为,使用验证策略的话,采样每一个类别会更加鲁棒。
3.2 双样本学习
如果训练数据不足时,使用迁移学习的效果要比直接在数据上进行训练效果要好。所以我们使用了非限制的数据集进行预训练,然后将IvS数据集作为目标领域。使用一个CVC(分类-验证-分类)的策略进行训练,如图2,CVC有3个步骤:
1、预训练(分类):我们先在非限制的数据集上训练一个模型,使用不超过100000个人,可以使用Softmax或者A-Softmax的分类器,这个模型在非限制的数据集上表现很好,但是在IvS的数据集上表现很差。不管怎样,这个模型学到了关于人脸的基础的知识。
2、迁移学习(验证):我们去掉最后一层的全连接,然后使用对比损失或者三元组损失来进行finetune,由于之前的预训练模型,我们会在IvS上取得比较好的效果。
3、细粒度的学习(分类):我们搭建了一个200万类别的分类网络,我们使用了一个新的基于支配原型的softmax方法,每次只用一部分的类别来参与分类,这种新的softmax的方法可以有效使用在大型的数据集上,进一步的提升能力。
CVC的关键在于知识的迁移需要流畅,我们发现在第一个步骤之后,大规模的分类已经开始收敛了,但是,loss下降的很慢,容易陷入到糟糕的局部最小中,考虑到验证损失对于数据的分布的鲁棒性比较好,我们使用了验证的损失来桥接两个分类,这样能给后面的分类一个好的初始值,从而取得更好的结果。
为了在最后一个步骤上进行分类,我们需要构建一个分类层,包括每一个类别的原型,原型是指类别的代理,优化后的特征会和属于同一类的原型接近。我们尝试了两种原型,ID原型和平均原型。我们使用第二步之后的模型提取ID图片和spot图片的特征,然后使用ID图片的特征和特征的平均值来作为该类别的权值向量。使用哪一种原型比较好,经过我们的实验,需要根据损失函数来定。
3.3 大规模分类
3.3.1 随机原型Softmax
使用一个初始化好的网络和原型,我们可以在IvS的数据集上进行分类,当类别为200万的时候,计算量是很大的,这个原型占用了大约4G的GPU显存,这样会使模型的深度受限,另外,训练这样的分类层也是非常耗时间的,因为参数太多了。
为了减少分类的花费,如图3所示,我们每次选取一个比例的原型参与到分类中,在一个minibatch中,所有的原型W可以划分为M个正样本原型,其余的都是负样本原型,所有的正样本原型都可以在minibatch中找到同一个类别的样本,组成一个正样本对,负样本模型和任意的样本组成负样本对。由于M远小于N-M,所以没有必要把所有的W都放到显存里,基于这个方法,我们提出了一个朴素的方法,叫做随机原型Softmax(Random Prototype Softmax),在一个minibatch中,我们会创建一个临时的原型矩阵,由正样本原型和负样本原型组成,总数量为其中,负样本原型随机选取,然后再将拷贝到显存中,然后训练和更新。再替换原来的原型矩阵。算法流程如下:

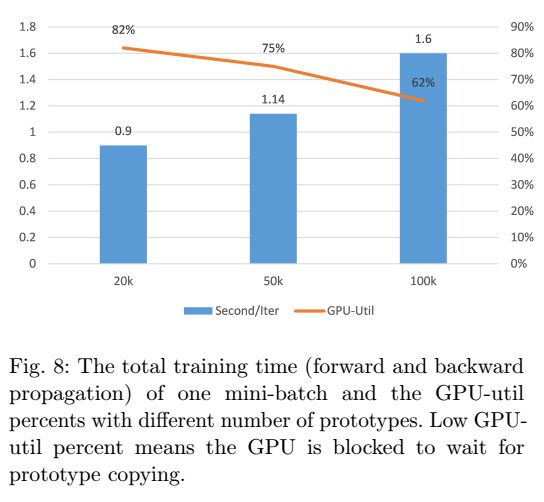
超参数非常重要,越大的话,有更多的负样本对参与,可以提供更加丰富的类间的差别的信息,效果也更好,但是太大的话,耗时也大,因为需要每次都进行内存到显存的拷贝,在我们的实验中,我们选取了一个经验值100000,兼顾了模型的能力和训练速度。
3.3.2 支配原型Softmax
尽管RP-Softmax的效果不错,由于选负样本时是盲选的,所以还是不够的。在这里,我们会展示,选取样本时,质量比数量更重要。我们会表明,只有很少部分的负样本原型能够贡献出比较大的梯度。从上面的公式中,我们可以看到,对于负样本原型来说,反向传播时,梯度的贡献主要取决于,范数为,通常我们会把w归一化,所以,范数就是,这个值可以用来度量w对训练过程的影响程度,我们定义一个负样本原型的能量值:
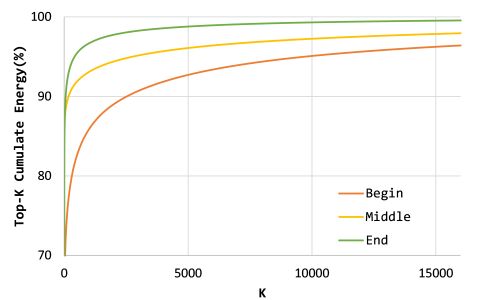
其中,指的是第j个训练样本属于类别i的概率,这里要注意,由于全是负样本原型,所以训练样本是不属于任何一个类别的。为了分析这个能量是不是集中于少数的一些原型中,我们进一步定义了top-K的累计能量:
一个小的K,大的top-K累计能量,表示了能量是非常集中的,可以从下面的图中看出,top-5000包含了92.71%的能力。随着训练的进行,能量越来越集中,在middle和End的时候,分别达到了96.09%和98.79%,这个结果表明了很少一部分的原型就可以贡献绝大部分的梯度,我们称这种原型为支配原型。
在实际的实现中,我们如何在计算每个原型的概率之前就能知道哪些是支配原型呢?我们通过计算和ID照片的相似度来确定,我们认为,如果两个ID照片的特征很接近,那么他们的原型和特征很容易组成困难的样本对,基于这个,我们提出了Dominant Prototype Softmax(DP-softmax) ,基本的思想就是从一个支配队列中选择一些原型然后通过softmax的预测来更新这个队列。细节如下:
队列初始化:对于每一个类别i,我们定义k近邻类别作为top-K的类别,在训练之前,我们通过ID的特征为每个类别构建了一个最近邻估计图,然后我们为每个类别创建一个支配队列以及候选集。其中通过来初始化,其中的成员按照和i的特征的距离进行排序,设置成。
原型选择:训练开始时,对于每一个minibatch,我们需要选择原型,首先,我们选择正样本原型,然后,对于每一个训练样本x,我们选择对应的类别的支配队列中的全部原型,第三,我们去掉和正样本原型重复的原型,再随机的选取负样本模型,直到数量足够为止。下面的算法步骤为DP-Softmax的算法流程:

队列更新:每个训练迭代之后,我们可以通过预测的softmax的概率来更新支配队列。对于一个特征xj,最高的激活类别h提供了最有价值的信息,第一,如果h=yj,那么预测的类别是对的,不需要更新。第二,h≠yj,但是h属于,预测是错误的,但是仍然在支配队列里面,我们不需要更新,第三,h≠yj,并且h不属于,但是h属于,这个表示类别的最近邻值已经变了,我们把h放入队列中,把队列中最不相似的那个类别出列,最后,h≠yj,并且h不属于和,这个表明h和yj开始的时候,特征很不相似,现在变得相似了。这个可能是由于标注错误或者是图像质量太差,这样的情况下,我们不更新,因为这个是个噪声数据。如图5:

原型的选取和队列的更新都是实时完成的,相比RP-Softmax,DP-Softmax显著提高了原型的质量,减少了原型的数量,训练更快,效果更好。
4. 实验
4.1 数据集
Ms-Celeb-1M: 这个数据集就不说了,大家都熟悉的。
CASIA-IvS: 这个训练集CASIA-IvS-Train 包含2578178 个人,每个人两张照片,一张身份证照,一张自拍照,测试集CASIA-IvS-Test 有4000个人,8000张图,和训练集不重复,测试的时候,随机组合负样本对,总共是1600万负样本对。如下图:

Public-IvS: 这个数据集是公开的,所有的图像都是网络上收集的,数据集中有1262个人,5507张图像,每个人一张身份证照,1~10张自拍照,如下图:

4.2 实验设置
预处理:我们通过FaceBox检测人脸,使用一个6层的CNN来检测5个特征点,所有的人脸经过相似变换,crop成120x120大小的RGB图像。
CNN结构:实验中所有的CNN模型都是相同的结构,一个64层的残差网络,4个残差block,最后通过平均池化得到512维的特征。初始学习率是0.001,训练收敛之后除以10。使用了4个TitanX进行训练,batchsize设置成塞满所有的GPU,验证的时候是66,分类的时候是50。
训练设置:CVC中有三个步骤,预训练的时候用的是Ms-Celeb-1M,从头训练,使用A-Softmax,第二个步骤,在CASIA-IvS-Train 上使用三元组进行finetune,三元组通过npair batch的方式组成,在线的难样本挖掘,anchor的交换。第三步,使用DP-Softmax进一步finetune,分类层通过ID的原型初始化,softmax提供了概率的计算,梯度由A-Softmax提供,支配队列和候选集分别是100和300。
评估设置:对于每一张图像,我们提取原图和镜像的特征,然后拼接在一起,使用余弦距离计算相似度,使用ROC曲线进行评估。
4.3 双样本训练
4.3.1 CVC
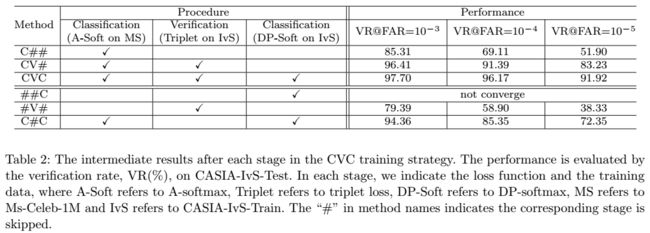
表2显示了CVC训练的有效性:
4.3.2 原型创建
有两种方式创建原型,这取决于使用什么样的损失函数,如下表,从表中可以看出,使用softmax的时候,ID原型的效果较好,而使用A-Softmax的时候,两者接近。当使用softmax的时候,我们发现avg的原型和收敛之后的权值很接近,无法提供多少loss,而使用ID原型的时候,能够提供的loss变大,训练的结果变好。而使用A-Softmax的时候,margin本身已经能够提供足够的loss,因此两者效果相当。因此后面我们都是使用的ID原型,只有在没有ID照片的时候,才使用avg的原型。
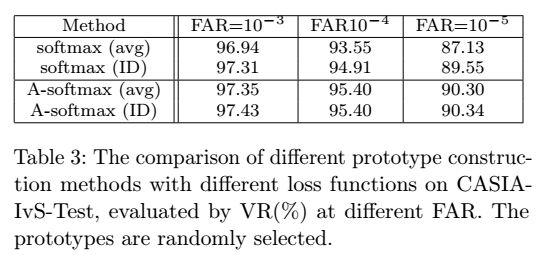
4.4 有效的大规模分类
4.4.1 随机原型Softmax
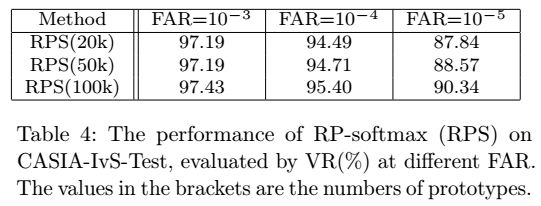
使用RP-Softmax的时候,我们尝试了改变了每次迭代中类别的数量。类别数越多,效果越好。但是时间上也会越慢。如图8。
4.4.2 支配原型Softmax
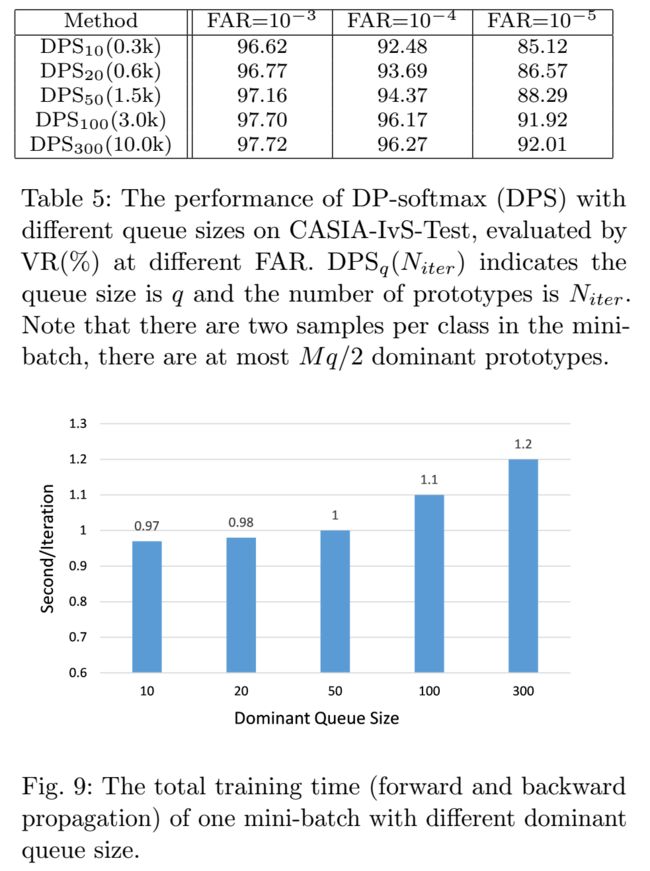
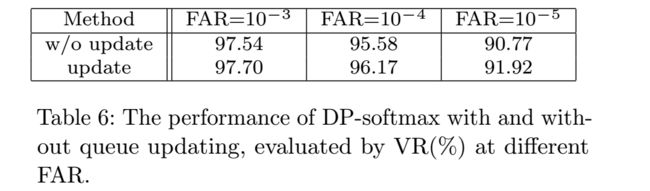
对于支配原型来说,队列的尺寸q是很重要的一个超参数,我们使用了不同q值,发现q=100,原型数量为3000时,performance迅速达到饱和,对比q=300,原型数量为10000,perfermance并没有提升多少,但是训练时间增大了许多。
我们同样也考虑了队列的更新,对比了队列的更新和不更新的情况:
4.5 对比试验
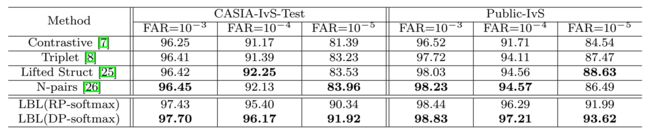
为了对比其他的算法,我们选择了对比损失,三元组损失,Lifted Struct和N-pairs的方法,模型都是在Ms-Celeb-1M 预训练,在CASIA-IvS-Train 上finetune,使用对比损失,每个minibatch中,两两配对,负样本采用难样本挖掘进行过滤。使用三元组损失,使用了npair batch的方法构建三元组,并且使用了anchor交换来创建最多的三元组,使用在线难样本挖掘来去除容易的三元组。对于N-pairs, 使用N-pair-mc损失来优化正样本对。对于Lifted Struct我们直接使用了发布的代码。可以看到,最大的提升在FAR=的时候。
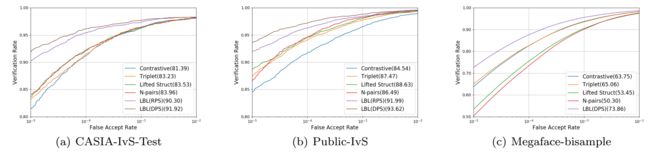
下图是不同的方法的ROC曲线:
4.6 在Megface双样本数据集上的模拟试验
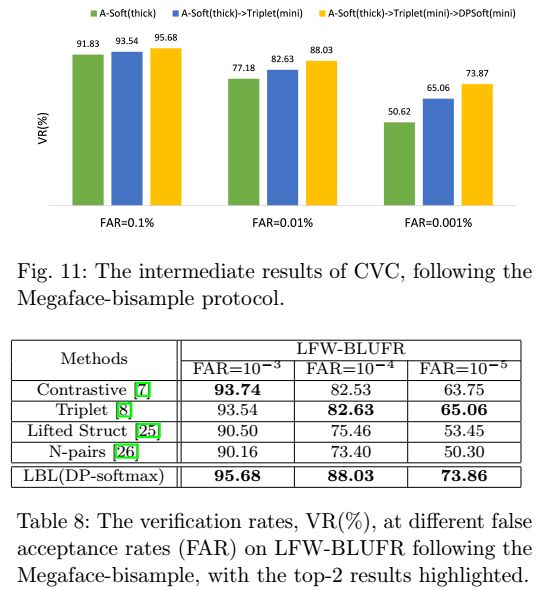
为了让我们的工作更加的可复现,我们在公开的MF2的数据集上模拟了一个双样本的数据集。MF2数据集有657559个人 ,我把MF2分为两个子集,MF2-thick和MF2-mini,MF2-thick数据集中,每个人有超过15个样本,用来模拟预训练数据集,MF2-mini数据集中每个人只有两个样本,用来模拟双样本数据集。总的来说,MF2-thick模拟Ms-Celeb-1M ,MF2-mini模拟CASIA-IvS-Train ,LFW-BLUFR 模拟CASIA-IvS-Test,其中 MF2-thick有46000个人,平均每个人有34.8个样本, MF2-mini有649790个人,每个人两个样本。
在实验中,由于没有ID的照片,我们使用平均原型来初始化分类层,通过实验,我们发现每一个步骤对模型的能力都有提升,见下图和下表。
5 总结
这篇文章提出了一种在身份证自拍照数据集上进行训练的大规模的双样本学习的方法,我们提出了一种CVC,分类-验证-分类的训练策略,首先从预训练的模型中将知识迁移过来,然后再使用大规模的双样本数据集进行验证和分类,提升模型的能力。我们还提出了一种支配原型Softmax,DP-Softmax来进行2百万类的分类,用在CVC的最后一个步骤。DP-Softmax智能的选取每个minibatch中的支配原型,提升了模型的能力,降低了训练的时间。实际的实验表明,提出的LBL(双样本学习)的方法能够有效的提高模型的能力,使用DP-Softmax只需要用到0.15%的类别数量,另外,我们还发布了Public-IvS 数据集。
本文可以任意转载,转载时请注明作者及原文地址。
