1. 关于 IBM Content Search Services
IBM Content Search Services 是一款 IBM 自主研发的独立的全文检索组件。就 FileNet 而言,它也是唯一的全文检索组件。但是,IBM Content Search Services 的设计不仅仅针对于 FileNet产品,它具有良好的扩展性和可嵌入性,可适用于多种 IBM 企业级产品,诸如 IBM Content Manager 等。
IBM Content Search Services 为用户提供整套的全文检索服务,它支持多种常用文档检索,支持多种编码方式,支持多达 22种语言。IBM Content Search Services 是基于开源搜索引擎 Apache Lucene 实现数据索引和检索的功能;基于UIMA 实现分词功能;基于 LanguageWare® 实现语言相关的处理;用户可以轻松的使用 Java™ 和 C++ API, 从 IBM Content Search Services 获得强大的数据索引和检索功能。
2. IBM Content Search Services 基本架构
IBM Content Search Services 支持单服务器模式,就是文本预处理与创建数据索引在同一台机器上;它也同时支持多服务器模式,将文本预处理与创建数据索引分别部署在不同的机器上。
IBM Content Search Services 文件预处理需要经过如下 5 个步骤,如图1所示:
图1: FileNet Content Search Service文档预处理过程
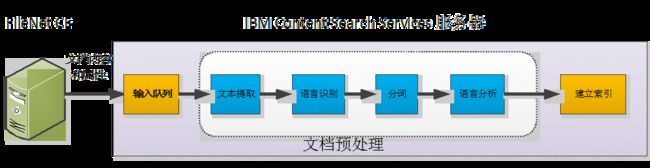
文本构造:文本构造是指将存储于信息库(可以是文件系统,也可以是数据库)中的文档调用并返回给 Content Search Services 服务器,为后面的文本处理和数据索引提供输入;
文本提取:为了创建数据索引,需要在这步从多种类型的文档中提取文本内容。可以自定义提供哪种类型的文档被提取。Content Search Services 既可以在已知文档类型、MIME类型或文档编码方式的情况下进行提取,也可以未知的情况下,自动检测出输入文档是否是二进制或者文档的编码方式;
语言识别:在这步确定所有文档的语言类型;
分词:在这步,Content Search Services 应用 UIMA 组件对提取出来的文本进行分词,将文本分成若干个 Token.
在分词过程中,许多没有实际意义的词汇将被舍弃,不能被分成Token,如英文中的“the”、“a”、“and”,汉字中的“着”、“了”、“的”,这些词几乎不会成为关键词被用户在检索过程中使用。分词产生的Token 最终将被 Lucene 组件创建成索引;
语言分析:这一步的功能由语言处理组件完成,通过对 Token 的词形、时态、词汇等方面进行分析和处理,如将 cars 处理为 car、将 drove 处理为 drive,以提高检索的查全率。
3. IBM Content Search Services 安装配置实例
IBM Content Search Services 虽然具有强大的数据索引和检索能力,但是它的安装和配置并不复杂。下面我们就以 IBM Content Search Services 与 FileNet Content Platform Engine 5.2.1 集成为例,为大家介绍一个完整的 IBM Content Search Services 安装与配置实例。我们将以尽可能多的实际安装截图来描述整个过程,尽可能的让它变的简单易懂。
3.1 IBM Content Search Services 的安装
IBM Content Search Services 的安装,既可以通过图形向导的方式完成,也可以通过命令行的方式完成。IBM
Content Search Services 安装向导的图形界面十分友好 ,通过阅读安装界面的描述,用户基本上可以成功的完成安装。大致步骤为:
接受安装许可协议
指定配置数据目录
指定安装目录(下文中以 $CSS_HOME 表示这个目录)
服务器配置信息
安装前预览
安装
完成安装
值得注意的是在第 4 步服务器配置信息(见图2)。在这里,我们尽量填入一个独特的 Authentication Token Seed,而不是使用空值。这个 Seed 会生成一个 Token,这个 Token 将用于 FileNet P8 Content Platform Engine 与IBM Content Search Services 的通信,所以一个独特的 Token 可以提高通信数据传输的安全性。
图2:服务器设置页面
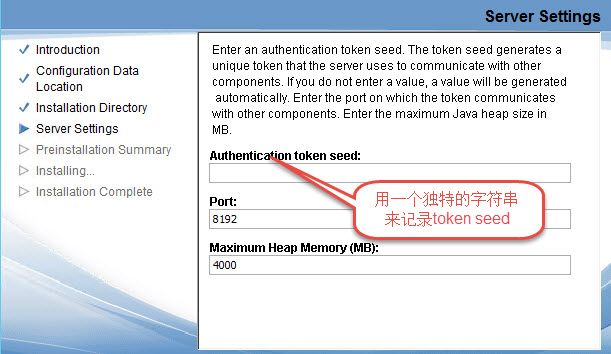
Token 会被显示在、完成安装的界面。请大家尽量记下这个 Token 后再点击完成安装按钮,这个 Token 将在后面的配置步骤中使用。
IBM Content Search Services 没有严格意义上的命令行安装方式,IBM Content Search Services的命令行安装方式等同于IBM传统的软件静默安装方式 (silent)。我们可以通过修改安装包中的 css_silent_install.txt 文件来指定安装目录和Authentication Token Seed 以及其他安装需要的信息。在完成 css_silent_install.txt的修改后,运行下面一条命令以实现 IBM Content Search Services 的安装:
x.x.x-CSS-WIN.exe -i silent -f css_silent_install.txt
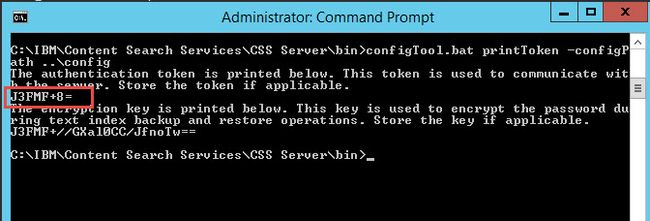
在静默方式下的安装,无法直接获得生成的 Token,用户需要在 $CSS_HOME/CSS_Server/bin 下运行如下命令来获取token的相关信息:
configTool.bat printToken -configPath ../config
Token 为图 3 中红色标注区域。
图 3. Config 文件中的 Token
安装完成之后,需要到 $CSS_HOME 下检查一下安装日志文件,我们要确保在 $CSS_HOME/css_install_log_x.x.x.log 中不含有任何错误信息。
3.2 IBM Content Search Services 的配置
在完成了的安装之后,我们来配置一个基本的 IBM Content Search Services 应用实例。
首先介绍一下文章中提到的实例的环境信息,实例中的 Content Platform Engine 的操作系统是 Windows 2012 R2,应用服务器是 IBM WebSphere 8.5.5,数据库是 Microsoft SQL Server 2008 R2。并且 IBM Content Search Services 与 Content Platform Engine 安装在同一台机器上(这个并非必需,它们也可以安装在不同的机器上)。
3.2.1 启动 IBM Content Search Services
在开始配置之前,我们要确保 IBM Content Search Services 是可用的。我们可以在 $CSS_HOME/CSS_Server/bin 目录下手动运行 startup.sh 将其启动 , 如图4。
图4. CSS server启动

在得到启动成功的提示后,我们可以通过测试是否可以 telnet 8191 端口(8191 为安装 IBM Content Search Services 时默认的端口号)的方式,验证启动成功。
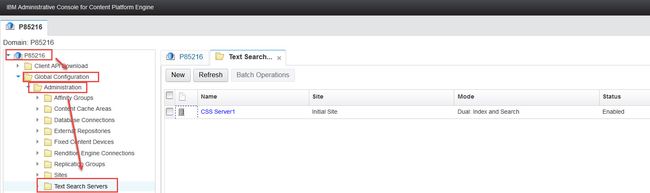
3.2.2 在CPE domain级别注册CSS server实例:
将 IBM Content Search Services 注册到 Content Platform Engine的Domain级别,我们将使用Administrative Console for Content Platform Engine 连接到 Content Engine Domain,在domain下面的全局设置->管理->Text Search Servers下面建立新的CSS server实例。如图5所示。
图5. CSS Server设置
点击新建来添加CSS server实例,输入一个自定义的名字,点击next, 如图6所示。
图6. 输入CSS Server的名字
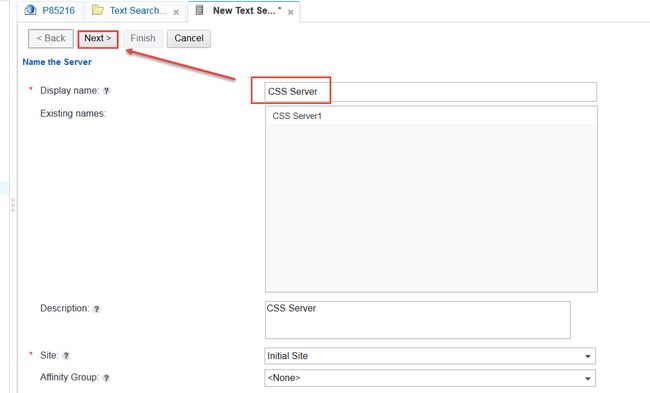
在定义服务器页面,我们可以看到如下信息, 如图7所示:
图7. 定义服务器信息

服务器状态信息反映了服务器以何种模式工作,我们这里是双工模式:既可以索引又可以搜索,状态是开启的。
服务器参数信息反映了连接的CSS服务器hostname,以及对应的端口和Token。
填写完毕后,点击 Next 并完成注册,这时我们就可以在 CPE的domain级别中,看到刚才注册建立的 Content Search Server 及其属性了。
3.2.3 在 Object Store级别建立 Index Area
完成了对 Content Search Server 的建立,下面我们为需要全文检索功能的 Object Store 建立 Index Area。首先先来理解一下什么是object store,这是CPE中一个对象存储库,这个对象存储库可以存储所有的对象,包括类(class)、文档、自定义对象等等。Index Area从字面理解就是索引区域,它主要用来就是存储CSS服务器处理的文档的索引数据。图8是一个已经建立好的Index Area。
图8. 建立好的Index Area信息
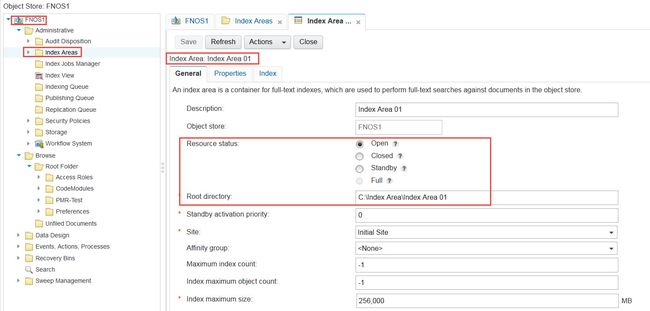
Index Area的属性中,我们可以看到他的状态是开启的,而且有一个物理空间用来存储索引相关的信息。
3.2.4 IBM Content Search Services的启用
完成了Index Area的建立后,我们要在object store本身以及class级别定义内容搜索(Content Base Retrieval)。我们这里以Document Class为例。
首先在object store级别,我们要启用IBM CSS,入图9所示
图9. 在Object Store启用IBM Content Search Service
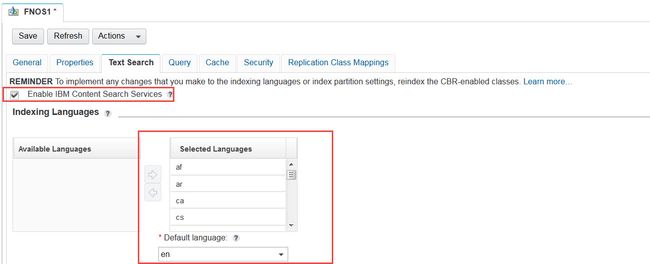
从上图可以看出产品是支持多语言的,我设置的默认语言是英文。
完成上面的配置后,我们要在object store的class上开启CBR (Content Base Retrieval),我们这里以Document Class为例,如图10。
图10. Class开启CBR
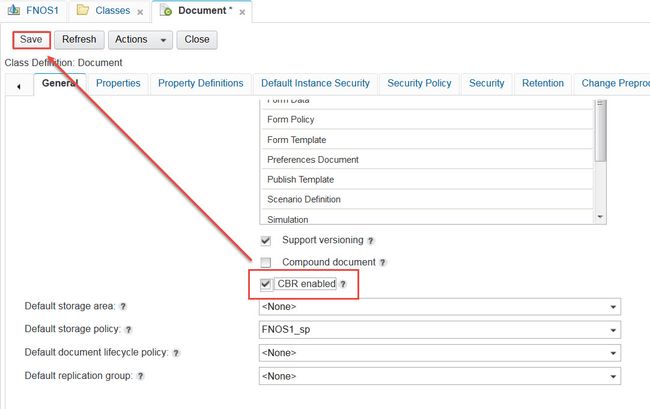
这样我们就在object store级别和class级别开启了CBR。
3.2.5 IBM Content Search Services的验证
最后我们将验证CSS服务器是否已经正常配置并工作。我们创建一个文件test CBR.txt,并输入如下内容:
test 1:
search Jason
test 2:
www.ibm.com
然后把文档上传到P8的Jason文件夹,如图11所示。
图11. 添加文档到文件夹
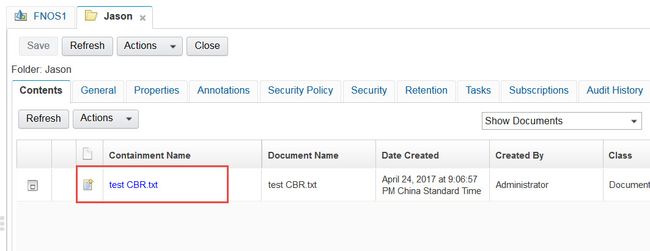
接下来我们稍等片刻,就可以去验证这个文档是否被正常的索引,而且我们可以通过搜索来查看是否内容搜索已经正常工作,请参考下面的文档:
https://www.ibm.com/support/knowledgecenter/SSNW2F_5.2.1/com.ibm.p8.ce.admin.tasks.doc/cbr/csscbr_query_running.htm
结果如下图12。
图12. ACCE中查询结果

我们可以看到我们通过搜索关键字“Jason”可以返回这个文档,这就验证了CSS server已经正常工作了。
除了使用 FileNet Enterprise Manager 来进行全文检索外,我们还可以使用 FileNet Workpalce XT 来进行功能更为强大的全文检索,更多关于FileNet Workplace XT的内容,请查看IBM的info center,这里不再赘述。附一张XT中内容搜索文档成功的截图,见图13。
图13. Workplace XT中的关键字搜索 (CBR)
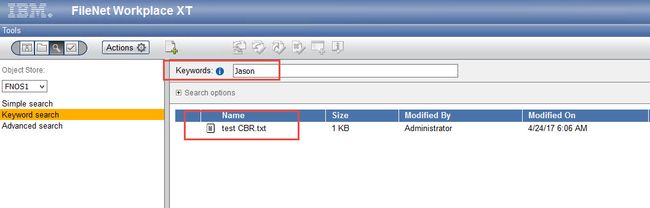
通过上面的结果, 我们得到了预期的搜索结果,因此可以证明 IBM Content Search Services 安装配置已经成功完成。
希望本篇文章对您在FileNet中配置CSS有帮助。