认证授权:
在开始调用任何API之前需要先进行认证授权,具体的说明请参考:
http://ai.baidu.com/docs#/Auth/top
获取Access Token
向授权服务地址https://aip.baidubce.com/oauth/2.0/token发送请求(推荐使用POST),并在URL中带上以下参数:
grant_type:?必须参数,固定为client_credentials;
client_id:?必须参数,应用的API Key;
client_secret:?必须参数,应用的Secret Key;
例如:
https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=Va5yQRHlA4Fq5eR3LT0vuXV4&client_secret=0rDSjzQ20XUj5itV6WRtznPQSzr5pVw2&
具体代码如下:
# -*- coding: utf-8 -*-
#!/usr/bin/env python
import urllib
import json
#client_id 为官网获取的AK, client_secret 为官网获取的SK
client_id =【百度云应用的AK】
client_secret =【百度云应用的SK】
#获取token
def get_token():
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + client_id + '&client_secret=' + client_secret
request = urllib.request.Request(host)
request.add_header('Content-Type', 'application/json; charset=UTF-8')
response = urllib.request.urlopen(request)
token_content = response.read()
if token_content:
token_info = json.loads(token_content)
token_key = token_info['access_token']
return token_key
对话情绪识别
对话情绪识别的详细介绍请看:http://ai.baidu.com/tech/nlp/emotion_detection
接口描述
针对用户日常沟通文本背后所蕴含情绪的一种直观检测,可自动识别出当前会话者所表现出的一级和二级细分情绪类别及其置信度,针对正面和负面的情绪,还可给出参考回复话术。帮助企业更全面地把握产品服务质量、监控客户服务质量。在自动监控中如果发现有负面情绪出现,可以及时介入人工处理,帮助在有限的人工客服条件下,降低客户流失。
请求说明
HTTP方法:?POST
请求URL:?https://aip.baidubce.com/rpc/2.0/nlp/v1/emotion
URL参数:
access_token:?通过API Key和Secret Key获取的access_token,参考“Access Token获取”
Header如下:
Content-Typeapplication/json
Body请求示例:
{
"scene":"talk",
"text": "本来今天高高兴兴"
}
现在body整体文本内容可以支持GBK和UTF-8两种格式的编码了。
1、GBK支持:默认按GBK进行编码,输入内容为GBK编码,输出内容为GBK编码,否则会接口报错编码错误
2、UTF-8支持:若文本需要使用UTF-8编码,请在url参数中添加charset=UTF-8 (大小写敏感) 例如 https://aip.baidubce.com/rpc/2.0/nlp/v1/lexer?charset=UTF-8&access_token=24.f9ba9c5241b67688bb4adbed8bc91dec.2592000.1485570332.282335-8574074
请求参数

返回说明
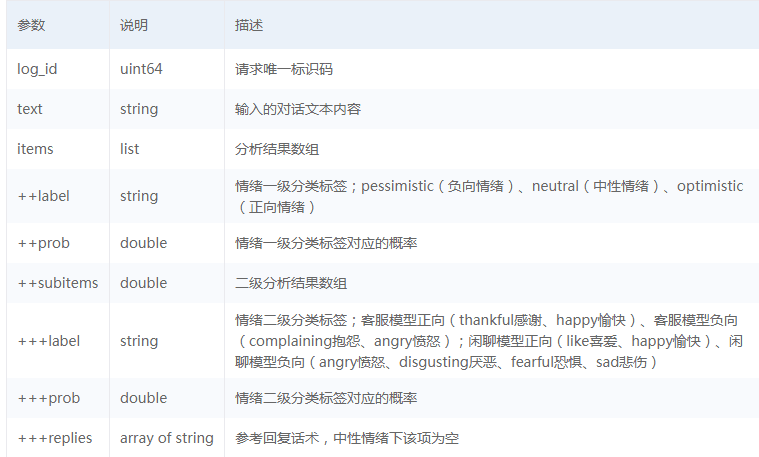
我用Python3写的调用函数如下:
def get_emotion(content):
token=get_token()
url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/emotion'
params = dict()
params['scene'] = 'talk'
params['text'] = content
params = json.dumps(params).encode('utf-8')
access_token = token
url = url + "?access_token=" + access_token
url = url + "&charset=UTF-8" # 此处指定输入文本为UTF-8编码,返回编码也为UTF-8
request = urllib.request.Request(url=url, data=params)
request.add_header('Content-Type', 'application/json')
response = urllib.request.urlopen(request)
content = response.read()
if content:
content=content.decode('utf-8')
data = json.loads(content)
return data
else:
return ''
执行:print (get_emotion('本来今天高高兴兴'))
结果如下:
{'log_id': 8567920447474187651, 'text': '本来今天高高兴兴', 'items': [{'subitems': [{'prob': 0.501008, 'label': 'happy'}], 'replies': ['笑一笑十年少'], 'prob': 0.501008, 'label': 'optimistic'}, {'subitems': [], 'replies': [], 'prob': 0.49872, 'label': 'neutral'}, {'subitems': [], 'replies': [], 'prob': 0.000272128, 'label': 'pessimistic'}]}
对话扩展:
有一个好玩的点子就是将返回的推荐Replies再发回去,是不是就能让Ai自己和自己聊天了。说干就干,Python代码如下:
def get_reply(data):
item=data['items'][0]
return item['prob'],item['label'],item['replies']
#聊天机器人,startcontent开始内容,talktimes聊多少句
def talk_bot(startcontent,talktimes):
content=startcontent
print (content)
for i in range(talktimes):
content=get_emotion(content)
prob,label,replies=get_reply(content)
print (i,prob,label,replies)
if len(replies)==0:
return
else:
content=replies
执行:
talk_bot('今天真开心啊',5)
今天真开心啊
0 0.998117 optimistic ['笑得真可爱']
1 0.998332 optimistic ['眼光不错']
2 0.979875 optimistic ['感觉自己棒棒哒']
3 0.932955 optimistic ['谢谢,我很开心']
4 0.999511 optimistic ['开心笑一笑']
talk_bot('你真漂亮啊',5)
你真漂亮啊
0 0.989602 optimistic ['感觉自己棒棒哒']
1 0.932955 optimistic ['谢谢,我很开心']
2 0.999511 optimistic ['笑得真可爱']
3 0.998332 optimistic ['感觉自己棒棒哒']
4 0.932955 optimistic ['谢谢,我很开心']
建议:
现在的参考回复话术,中性情绪下该项为空。不知道是否能在中性情绪下也返回一些建议的回复内容,这样的话便于统一处理。