姓名:朱小鹏 学号:16010130023
转载:
http://blog.sina.com.cn/s/blog_62a85b950101anw5.html
【嵌牛导读】:对于IP层主要讨论信息包的接收、分片数据包重装、信息包的发送和转发三个内容。IP数据报头结构如下所示,其中,选项字段是可以没有的,所以通常的IP数据报头长度为20个字节。
【嵌牛鼻子】:IP层
【嵌牛提问】:LWIP中的IP层如何进行信息包的接收、分片数据包重装、信息包的发送和转发?
【嵌牛正文】:
对于IP层主要讨论信息包的接收、分片数据包重装、信息包的发送和转发三个内容。IP数据报头结构如下所示,其中,选项字段是可以没有的,所以通常的IP数据报头长度为20个字节。
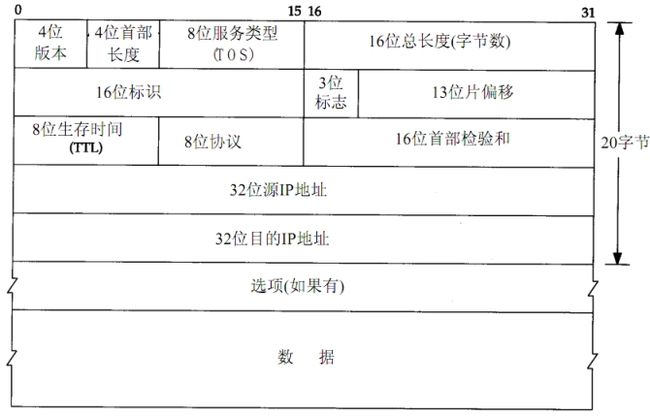
第一个字段是4bit的版本号,对于IPv4,该值为4;对于IPv6,该值为6。
接下来的4bit字段用于记录首部长度,以字为单位。所以对于不含任何选项字段的IP报头,则该长度值为5,由于该字段最大值为15,所以其能描述的最大IP报头长度为15*4=60字节。
再下来是一个8bit的服务类型字段,该字段主要用于描述该IP数据包急需的服务类型,如最小延时、最大吞吐量、最高可靠性、最小费用等。这个字段在LWIP中没啥用处。
16位的总长度字段描述了整个IP数据报,包括IP数据报头的总字节数。理论上说,IP数据包总长度最大可达65535字节,但在实际应用中,底层链路可不允许这么大的数据包出现在链路上,因为这会大大增加数据出错的可能性,所以在链路层往往会对大的IP数据包进行分片,当然这些都是后话。
接下来的16位标识字段用于标识IP层发送出去的每一份IP数据报,每发送一份报文,则该值加1。然后的3位标志和13位片偏移字段用于在IP数据包分片时使用,这里先不讨论。LWIP的较高版本才支持IP分片功能。
TTL字段描述该IP数据包最多能被转发的次数,每经过一次转发,该值会减1,当该值为0时,一个ICMP报文会被返回至源主机。
8位协议字段用来描述该IP数据包是来自于上层的哪个协议,该值为1表示为ICMP协议,该值为2表示IGMP协议,该值为6表示TCP协议,该值为17表UDP协议。
16位首部校验和只针对IP首部做校验,它并不关心其内部数据在传输过程中出错与否,对于数据的校验是上层协议负责的,如ICMP、IGMP、TCP、UDP协议都会计算它们头部以及整个数据区的长度。这里再COPY一段这个校验和是怎样生成以及在接收端是如何实验校验的。
在发送端为了计算一份数据报的IP检验和,首先把检验和字段置为0。然后,对首部中每个16 bit进行二进制反码求和(整个首部看成是由一串16 bit的字组成),结果存在检验和字段中。当接收端收到一份I P数据报后,同样对首部中每个16 bit进行二进制反码的求和。由于接收方在计算过程中包含了发送方保存在首部中的检验和字段,因此,如果首部在传输过程中没有发生任何差错,那么接收方计算的结果应该为全1。如果结果不是全1(即检验和错误),那么IP就丢弃收到的数据报。但是不生成差错报文,由上层去发现丢失的数据报并进行重传。
接下来是两个32位的IP地址,不啰嗦了。最后一个字段是任选字段,不同的协议会选择性的使用该字段,这里也不讨论。
现在来看看LWIP中是怎么样来描述这个IP数据报头的,使用的结构体叫ip_hdr:
struct ip_hdr {
PACK_STRUCT_FIELD(u16_t _v_hl_tos);//前三个字段:版本号、首部长度、服务类型
PACK_STRUCT_FIELD(u16_t _len);//总长度
PACK_STRUCT_FIELD(u16_t _id);//标识字段
PACK_STRUCT_FIELD(u16_t _offset); // 3位标志和13位片偏移字段
#define IP_RF 0x8000//
#define IP_DF 0x4000//不分组标识位掩码
#define IP_MF 0x2000//后续有分组到来标识位掩码
#define IP_OFFMASK 0x1fff//获取13位片偏移字段的掩码
PACK_STRUCT_FIELD(u16_t _ttl_proto);// TTL字段和协议字段
PACK_STRUCT_FIELD(u16_t _chksum);//首部校验和字段
PACK_STRUCT_FIELD(struct ip_addr src);//源IP地址
PACK_STRUCT_FIELD(struct ip_addr dest);//目的IP地址
} PACK_STRUCT_STRUCT;
注意结构体声明的时候定义了几个宏定义:IP_RF、IP_DF、IP_MF、IP_OFFMASK,它们是在求与分组相关两个字段时要用到的掩码,也可以在结构体的外面进行定义,无影响。
前面讲过,从以太网底层进来的数据包经过ethernet_input函数分发给IP模块或者ARP模块,分发给IP模块是通过调用ip_input函数完成的,当然在递交前,ethernet_input需要将数据包去掉以太网头。现在来看看数据包传递给ip_input后,该函数进行了哪些方面的工作。这里我们先不涉及其内部关于DHCP协议的相关处理。
第一件事是检查IP头部的版本号,如果该值不为4,则立即丢弃该数据包。更高版本的LWIP协议栈可以支持IPv6,但这里我们只讨论IPv4。接下来函数检查IP数据报头是否只保存于一个pbuf中,如果不是 ,也直接丢弃该IP包,这是因为LWIP不允许IP数据包头被分装在不同的pbuf里面。同时,函数检查IP报头中的总长度字段是否大于递交上来的数据包总长度,如果是,则说明存在传输错误,直接丢弃数据包。
然后是对IP数据报头做校验,该工作是函数inet_chksum完成的,如果校验不通过则直接丢弃数据包。inet_chksum函数在后续有需要时会详细讲解。
接着,需要在这里对数据包进行截断操作,按照IP包头记录的总长度字段截取数据包,因为经过ethernet_input传递上来的数据包只被去除了以太网数据包头部,而对于可能存在的以太网填充字段和一定存在的以太网校验字段(最后一字节)没做处理,我们在这里对它们进行截断,得到完整无冗余的IP数据包。
然后,函数检测IP数据包中的目的IP地址是否与本机的相符,本机的IP地址是保存在netif结构体变量中的,一个系统可能有着多个网卡设备,这就意味着它有多个netif结构体变量分别用于描述这些网卡设备,也意味着本机有着多个IP地址,这些netif结构体是被连接在netif_list链表上的。ip_input函数会遍历netif_list链表上的netif结构以找到匹配的IP地址,并记录该netif结构体变量,也即记录该网卡。从这点看来,在ARP部分内容中,对于某个接收到的ARP请求包,也应该按照这种方式进行遍历后再给出ARP相应更好,而源代码并没有这样做,当然,这只是个人意见。当遍历完成后,如果依旧没有得到与匹配的netif结构体变量,这说明该数据包不是给本机的,此时需要对数据包进行转发或者丢弃工作,这是通过宏定义IP_FORWARD来完成的,这里注意不要对广播数据包进行转发。
再接下来,根据目标IP地址判断数据包是否为广播或多播IP数据包,LWIP不对这些类型的数据包进行相应。
再接下来的工作可以说是ip_input函数中最复杂最难理解的部分,这就是IP分片数据包的重装,ip_input函数通过数据包的3位标志和13位片偏移字段判断发给自己的该IP包是不是分片包,如果是,则需要将该分片包暂存,等到接收完所有分片包后,统一将整个数据包递交给上层应用程序。这是万言难尽得过程,先在这里打住,我们在以后的内容里面细细讨论。如果是分片包,且不是最后一片,则函数到这里就返回了。
终于,能到达这一步的数据包必然是未分片的或经过分片完整重装后的数据包。此时,ip_input函数根据IP数据包头内部的协议字段判断该数据包应该被递交给哪个上层协议,并调用相应的函数递交数据包。是UDP协议,则调用udp_input函数;是TCP协议,则调用tcp_input函数;是ICMP协议,则调用icmp_input函数;是IGMP协议,则调用igmp_input函数;如果都不是,则调用函数icmp_dest_unreach返回一个协议不可达ICMP数据包给源主机,同时删除数据包。
写完收工!