今天进入Python爬虫学习,具体学习内容为下载图片,爬取有道词典的翻译和简单的使用代理。
1、下载图片
非常简单的小脚本,在http://www.placekitten.com网上爬取猫咪的图片
代码如下
1 from urllib import request 2 3 4 def door(): 5 url = "http://www.placekitten.com" 6 req = request.Request(url) 7 response = request.urlopen(req) 8 kitten = response.read() 9 with open("cat.jpg", "wb") as p: 10 p.write(kitten) 11 12 13 def main(): 14 door() 15 16 17 if __name__ == '__main__': 18 main()
2、爬取有道词典的翻译
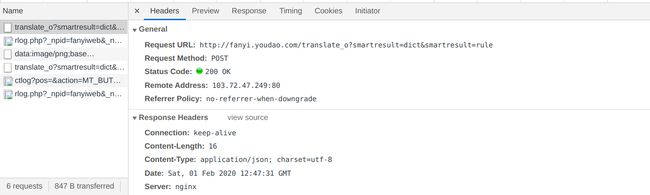
打开开发者工具,选择network,然后输入要翻译的内容,点击翻译,network中就会出现如下内容

我这里不知道为什么,点击翻译后总是出现“抱歉,请不要频繁请求服务”,同时也翻译不出东西。不过不大影响接下来的工作。点击Name下第一个“translate_o……”出现如下画面(需要注意的是,只有有道翻译是第一个,百度翻译不是,所以需要在一大堆请求中找到需要的)
得到相应的Request URL参数(千万记得去掉_o,不然是会被反爬的!!!),一直下拉找到Form Data
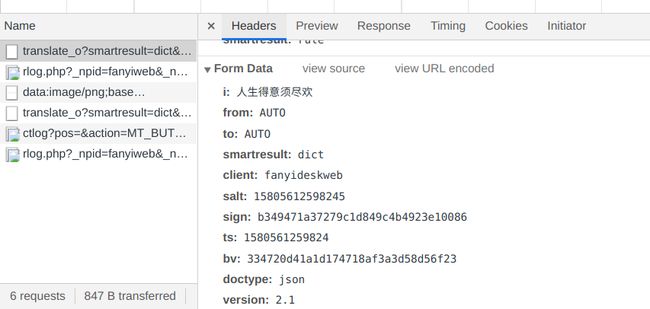
将Form Data制作成字典来请求反馈
data = { 'i': ‘人生得意须尽欢’, 'from': 'AUTO', 'to': 'AUTO', 'smartresult': 'dict', 'client': 'fanyideskweb', 'salt': '15805516827176', 'sign': '17cf93ee9a11894806209a83c480ca2b', 'ts': '1580551682717', 'bv': '334720d41a1d174718af3a3d58d56f23', 'doctype': 'json', 'version': '2.1', 'keyfrom': 'fanyi.web', 'action': 'FY_BY_CLICKBUTTION'}
如此,得到字典
在得到Request URL和Data字典后,就可以进行爬取了,代码如下
from urllib import request from urllib import parse import json import time def translation(string): url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'} data = { 'i': string, 'from': 'AUTO', 'to': 'AUTO', 'smartresult': 'dict', 'client': 'fanyideskweb', 'salt': '15805516827176', 'sign': '17cf93ee9a11894806209a83c480ca2b', 'ts': '1580551682717', 'bv': '334720d41a1d174718af3a3d58d56f23', 'doctype': 'json', 'version': '2.1', 'keyfrom': 'fanyi.web', 'action': 'FY_BY_CLICKBUTTION'} data = parse.urlencode(data).encode("utf-8") req = request.Request(url, data, headers) response = request.urlopen(req) html = response.read().decode("utf-8") prasewords(html) def prasewords(html): trans = json.loads(html) firstwords = trans['translateResult'][0][0]['src'] finaltrans = trans['translateResult'][0][0]['tgt'] output(firstwords, finaltrans) def output(firstwords, finaltrans): print("您输入的是:%s" % firstwords) print("翻译结果是:%s" % finaltrans) def main(): while True: print("") string = input("请输入要翻译的内容(输入quit或q或exit均可退出程序):") if string == 'quit' or string == 'q' or string == 'exit': break translation(string) time.sleep(3) if __name__ == '__main__': main()
需要注意的是,有时需要加入headers,请求头中写入User-Agent(用户代理,在浏览器的地址栏输入 about://version),否则默认User-Agent是Python自己的,访问会被拒绝。
3、简单的使用代理
这一步需要到网络上取搜索能用的免费ip代理地址(https://www.xicidaili.com/,当然,如果花钱买更好,
既稳定又快速),我尝试了不下50个,才勉强找到一个可用的。
首先找到一个可以查看自己IP地址的网页,抓取网页源代码,检查是否正常显示自己的IP地址。可以正常显示,进入下一步。不可以正常爬去网页源代码,更换网址或者加入请求头等操作直到可以正常显示。其次利用代码代理IP,再次抓取源码,检查IP是否被更换。代码如下
1 import urllib.request 2 3 4 def proxyip(): 5 # 可以正常显示我的IP地址的网站 6 url = "http://www.ccw.cc/ip/" 7 # 使用代理IP的操作 8 proxy_support = urllib.request.ProxyHandler( 9 {'http': '58.212.43.145:9999'}) 10 opener = urllib.request.build_opener(proxy_support) 11 urllib.request.install_opener(opener) 12 # 更换IP后抓取源码 13 req = urllib.request.Request(url) 14 response = urllib.request.urlopen(req) 15 # 读取并打印源码 16 html = response.read().decode("utf-8") 17 print(html) 18 19 20 if __name__ == '__main__': 21 proxyip()
可以看到,IP地址已经被更换
![]()
PS.
强烈推荐autopep8这个插件,用pycharm写代码没有autopep8简直就是地狱!代码会无时无刻不报PEP8警告,虽然不是错误,但密密麻麻的波浪线简直是要逼死强迫症!autopep8可以解决大多数格式问题。
简单叙述一下安装教程
1、直接用pycharm安装,全图形化操作
打开File—>Setting—>Project:xxx—>Project Interpreter

点击+号,输入autopep8,耐心等待
直到出现
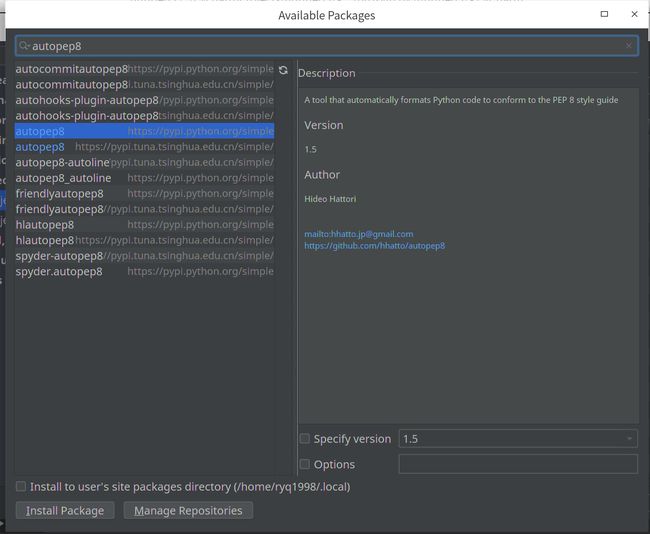
点击Install Package,一路等待安装成功。
2、使用pip安装
打开终端,输入(sudo)pip install autopep8,同样耐心等待安装成功
3、配置autopep8
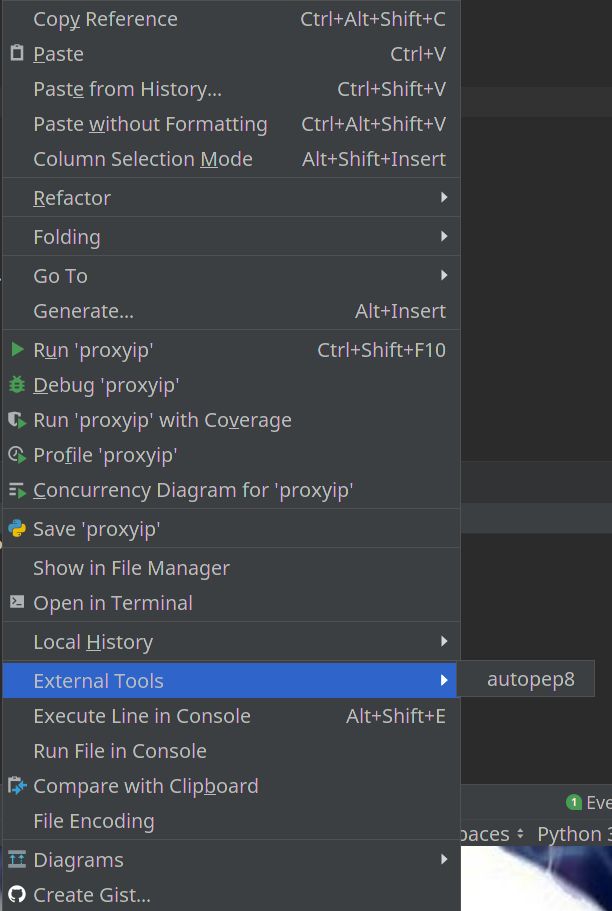
打开setting—>tools—>External Tools,点击加号,出现如下配置界面
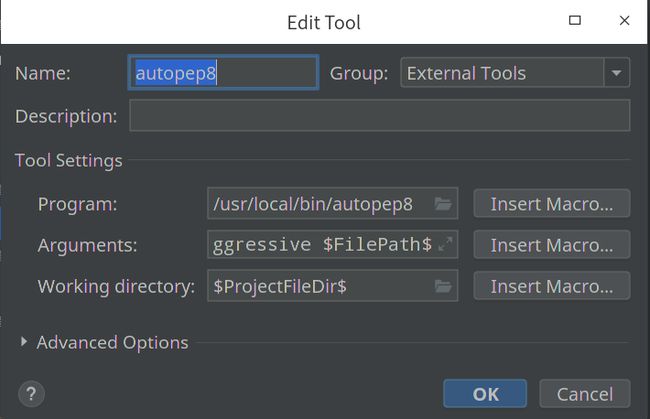
Name输入配置名称(随便输)。重点是Tools Settings的三个配置,Program输入autopep8所在位置,Arguments输入--in-place --aggressive --aggressive $FilePath$,Work directory输入$ProjectFileDir$,最后点击ok,配置成功!
4、使用方法
在代码界面右击,找到External Tools,点击相应的配置名称,代码就不会报烦人的PEP8警告啦!