读取数据
pandas可以读取文本文件、json、数据库、Excel等文件
使用read_csv方法读取以逗号分隔的文本文件作为DataFrame
head、tail等方法可以浏览部分数据集,可使用dtypes方法查看各列数据类型,通过astype方法修改数据类型
import pandas as pd
bill=pd.read_csv('bill.csv')#读取账单,赋值给变量bill
bill.head(5)#读取数据前5行,可以用bill.tail(5)读取最尾部5行
描述数据集
对数据的基本统计量进行计算以便初步了解数据,可以对统计量一个个单独计算,但pandas提供了一个describe函数可以一次计算多个统计量,默认计算连续型数据的统计量,要计算离散数据的统计量需要预先修改相应字段的类型,然后传入向describe函数中传入include参数
bill.dtypes#查看数据集各字段的类型
bill['IN_NETWORK_TIME']=bill['IN_NETWORK_TIME'].astype(pd.datetime)#修改入网时间为pd.datetime类型
数据选取
选择记录
通过传入true-or-false表达式选择所有结果为true的记录,例:bill[bill['PAY_SUM']>66]
选择字段
使用drop方法,它不改变原有的DataFrame中的数据,而是返回另一个DataFrame,例:newbill=bill.drop('MONTH']
使用del方法,就地删除原始DataFrame的列,一次删除一列,例:del bill['MONTH']
通过索引可以直接选择需要的列,例:bill[['ID','IN_NETWORK_TIME','IN_NET']]
通过切片选择需要的记录和字段
使用ix方法同时选取相应的记录和字段,例:bill.ix[0:1000:5,'PAY_SUM':'IN_NET':1]
bill=bill[bill['VIPFLAG']==0]#选择所有非VIP用户
bill=bill.drop(['MONTH','VIPFLAG','PRODUCT_ID'],axis=1)#drop掉MONTH、VIPFLAG、PRODUCT_ID三个不需要的列
分组汇总数据
这是在日常分析工作中运用最多的功能之一,pandas提供了groupby方法和丰富的聚合函数来实现这种功能
利用groupby方法生成DataFrameGroupBy对象.
应用聚合函数对DataFrameGroupBY对象进行聚合,常用的pandas聚合函数包括经过优化的count sum mean median min max std等,也可使用自定义函数进行聚合,只需将函数传入agg方法即可,详见pandas文档
1. 使用groupby方法生成一个DataFrameGroupBy对象
bill.groupby('USER_STATE')#仅按’USER_STATE'进行汇总,也可同时按多列汇总,见下例
2.应用聚合函数对DataFrameGroupBY对象进行聚合
bill[['PAY_SUM','TRAFFIC_SUM','CALL_SUM']].groupby([bill['USER_STATE'],bill['IN_NET']]).mean()
生成透视表/交叉表
透视表/交叉表比汇总表可读性更高,生成的报表往往采用透视表/交叉表的形式
DataFrame提供了实例方法pivot_table来生成透视表/交叉表,pandas.pivot_table是一个能实现同样功能的顶级函数,另外pandas.crosstab是专用于生成交叉表的函数
bill.pivot_table(['PAY_SUM','TRAFFIC_SUM','CALL_SUM'],index='USER_STATE',columns='IN_NET',aggfunc='mean')
pd.crosstab(bill['IN_NET'],bill['USER_STATE'])
去重
使用drop_duplicates方法返回一个不含重复项的DataFrame,默认识别所有列,也可单独指定要区分的列
call_detail=pd.read_csv('call_detail.csv')#读取通话详单,赋值给变量call_detail
cd=call_detail[['ID','IMSI','IMEI']].drop_duplicates('ID')
连接/合并数据
进行数据分析时,数据经常来源于不同的文件,需要将这些表连接/合并起来,放在一张表中进行分析
横向连接:将不同的表按照关键字连接起来,包括内连接、外连接、左连接、右连接等,进行一对一的连接时,最好先去重数据集
pd.merge(left,right,how,on,left_on,right_on),其中how:{'inner','outer','left','right'},默认为'inner',可按多个关键字合并
纵向合并:将数张表纵向合并起来,例如将一月和二月销售数据具有相同的列,可将二者纵向合并
pd.concat(objs,axis=0,ignore_index=False),其中objs:表变量组成的列表,例:pd.concat([cd,cd])
mt=pd.merge(bill,cd,on='ID')
数据转换
原始数据需要经过转换才能符合建模需求,例如:生成新字段、重新分类、变换哑变量、去除重复数据、过滤极端\异常值、填补缺失值、变量聚类、离散化等
mt['IMEI']=mt['IMEI'].fillna(0)#将IMEI空值填为0
mt['TAC']=mt['IMEI'].map(lambda x:str(x)[:6])#对字符串操作,生成新列'TAC'
mt['Z_PAY']=(mt['PAY_SUM']-mt['PAY_SUM'].mean())/mt['PAY_SUM'].std()#对数值操作,生成新列'Z_PAY'
from datetime import datetime,timedelta
mt['U_duration']=map(lambda x:x.days/30.,datetime(2014,11,1)-pd.to_datetime(mt['IN_NETWORK_TIME']))#时间函数生成新列
mt['USER_STATE']=mt['USER_STATE'].replace([2,3,4,5,6,7],2)#用替换值的方式合并不同分类水平,也可用于填补空值
mt['TRAFFIC_SUM'][mt['TRAFFIC_SUM']>2000]=2000#盖帽法处理极端值,会产生警告信息
new_mt=mt.join(pd.get_dummies(mt['USER_STATE'],prefix='U_S'))#生成哑变量
new_mt.describe(include='all').T
数据探索
除了describe计算基本统计量外,还需要探索目标变量和自变量以及自变量之间的关系,以决定哪些变量入选模型,这种数据探索往往结合图形来说明
常用的绘图包包括matplotlib、seaborn等
churn=pd.read_csv('telecom_churn.csv') 读取已经整理好的数据
仅对部分分类变量进行了指定
churn['gender']=churn['gender'].astype('category')
churn['edu_class']=churn['edu_class'].astype('category')
churn['feton']=churn['feton'].astype('category')
churn.describe(include='all')
import math
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from scipy import stats,integrate
import statsmodels.api as sm
sns.distplot(churn['duration'],fit=stats.norm)
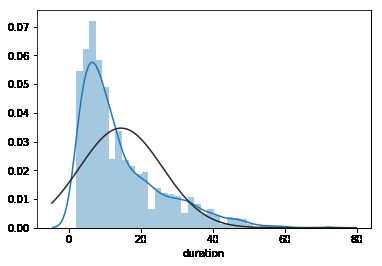
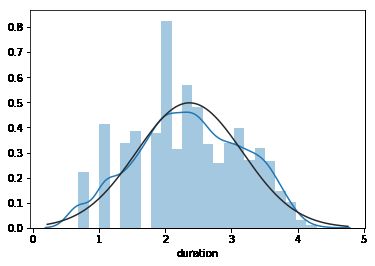
sns.distplot(np.log(churn['duration']),kde=True,fit=stats.norm)
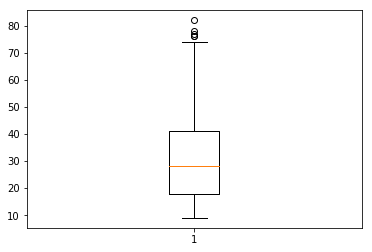
plt.boxplot(churn['AGE'])
sns.barplot(x='edu_class',y='churn',data=churn)

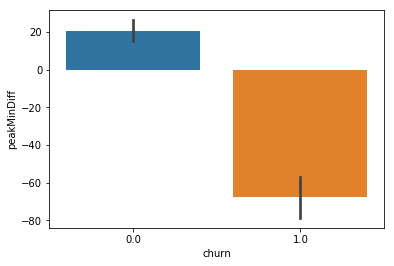
sns.barplot(x='churn', y='peakMinDiff',hue=None,data=churn)
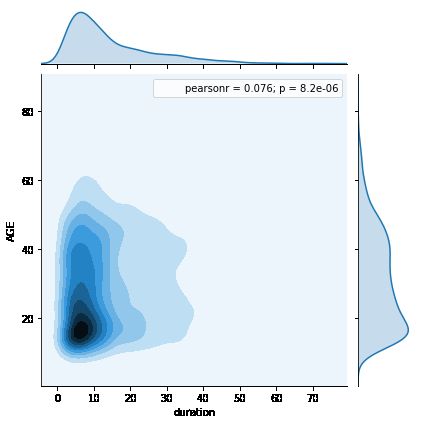
sns.jointplot(x='duration', y='AGE', data=churn,kind='kde')
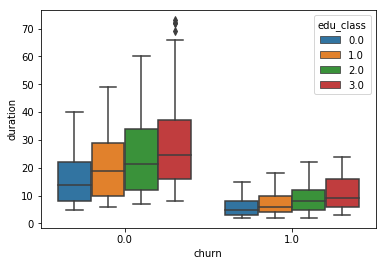
sns.boxplot(x='churn', y='duration',hue='edu_class',data=churn)
筛选变量
筛选变量时可以应用专业知识,选取与目标字段相关性较高的字段用于建模,也可通过分析现有数据,用统计量辅助选择
为了增强模型稳定性,自变量之间最好相互独立,可运用统计方法选择要排除的变量或进行变量聚类
corrmatrix=churn.corr(method='spearman')
spearman相关系数矩阵,可选pearson相关系数,目前仅支持这两种,函数自动排除category类型
corrmatrix[np.abs(corrmatrix)>0.5]
选取相关系数绝对值大于0.5的变量,仅为了方便查看
为了增强模型稳定,根据上述相关性矩阵,除'posTrend','planChange','nrProm','curPlan'几个变量
sampler = np.random.randint(0,len(churn),size=50)
随机数列表
clustertable=churn[['AGE','peakMinAv','peakMinDiff','incomeCode','duration']]
选取连续型变量
sns.clustermap(clustertable.iloc[sampler].T, col_cluster=False, row_cluster=True)
抽样并进行变量聚类

连续型变量往往是模型不稳定的原因,同时模型解释时也更困难,可通过离散化变换为分类变量
churn['duration_bins']=pd.qcut(churn.duration,14)
将duration字段切分为数量(大致)相等的14段
churn['churn'].astype('int64').groupby(churn['duration_bins']).agg(['count','mean']).T
bins = [0,4,8,12,22,73]
churn['duration_bins'] = pd.cut(churn['duration'],bins,labels=False)
churn['churn'].astype('int64').groupby(churn['duration_bins']).agg(['mean','count'])
根据卡方值选择与目标关联较大的分类变量
计算卡方值需要应用到sklearn模块,但该模块当前版本不支持pandas的category类型变量,会出现警告信息,可忽略该警告或将变量转换为int类型
import sklearn.feature_selection as feature_selection
churn['gender']=churn['gender'].astype('int')
churn['edu_class']=churn['edu_class'].astype('int')
churn['feton']=churn['feton'].astype('int')
feature_selection.chi2(churn[['gender','edu_class','feton','prom','posPlanChange',
'duration_bins','curPlan','call_10086']],churn['churn'])
选取部分字段进行卡方检验
根据结果显示,'prom'、'posPlanChange'、'curPlan'字段可以考虑排除
建模¶
根据数据分析结果选取建模所需字段,同时抽取一定数量的记录作为建模数据
将建模数据划分为训练集和测试集
选择模型进行建模
#根据模型不同,对自变量类型的要求也不同,为了示例,本模型仅引入'AGE'这一个连续型变量
model_data=churn[['subscriberID','churn','gender','edu_class','feton','duration_bins']]
model_data=churn[['subscriberID','churn','gender','edu_class','feton','duration_bins','call_10086','AGE']]
第二可选方案
target = model_data['churn']#选取目标变量
data=model_data.ix[:,'gender':]#选取自变量
import sklearn.cross_validation as cross_validation
train_data,test_data,train_target,test_target=cross_validation.train_test_split(data,target,test_size=0.4,
train_size=0.6
,random_state=12345)#划分训练集和测试集
选择决策树进行建模
import sklearn.tree as tree
clf=tree.DecisionTreeClassifier(criterion='entropy', max_depth=8, min_samples_split=5)#当前支持计算信息增益和GINI
clf.fit(train_data,train_target)#使用训练数据建模
#查看模型预测结果
train_est=clf.predict(train_data)#用模型预测训练集的结果
train_est_p=clf.predict_proba(train_data)[:,1]#用模型预测训练集的概率
test_est=clf.predict(test_data)#用模型预测测试集的结果
test_est_p=clf.predict_proba(test_data)[:,1]#用模型预测测试集的概率
pd.DataFrame({'test_target':test_target,'test_est':test_est,'test_est_p':test_est_p}).T#查看测试集预测结果与真实结果对比
模型评估
import sklearn.metrics as metrics
print (metrics.confusion_matrix(test_target, test_est,labels=[0,1]))#混淆矩阵
print (metrics.classification_report(test_target, test_est))#计算评估指标
print (pd.DataFrame(zip(data.columns,clf.feature_importances_)))#变量重要性指标
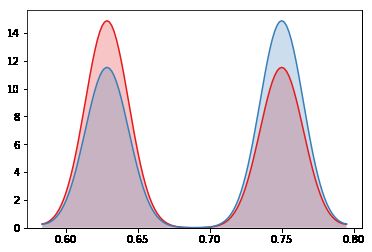
red, blue = sns.color_palette("Set1",2)
sns.kdeplot(test_est_p[test_target==1], shade=True, color=red)
sns.kdeplot(test_est_p[test_target==0], shade=True, color=blue)
fpr_test, tpr_test, th_test = metrics.roc_curve(test_target, test_est_p)
fpr_train, tpr_train, th_train = metrics.roc_curve(train_target, train_est_p)
plt.figure(figsize=[6,6])
plt.plot(fpr_test, tpr_test, color=blue)
plt.plot(fpr_train, tpr_train, color=red)
plt.title('ROC curve')

tree.export_graphviz(clf,out_file='tree.dot')#查看树结构
模型保存/读取
import pickle as pickle
model_file = open(r'clf.model', 'wb')
pickle.dump(clf, model_file)
model_file.close()
model_load_file = open(r'clf.model', 'rb')
model_load = pickle.load(model_load_file)
model_load_file.close()
test_est_load = model_load.predict(test_data)
pd.crosstab(test_est_load,test_est)