在系统运维中,经常会遇到某个具体组件发生故障,进而导致整个应用系统瘫痪的情况,所以要及时对这些具体组件进行跟踪和预测,判断出如果发生故障,要及时给予告警。
如下为某个应用系统的拓扑关系图。
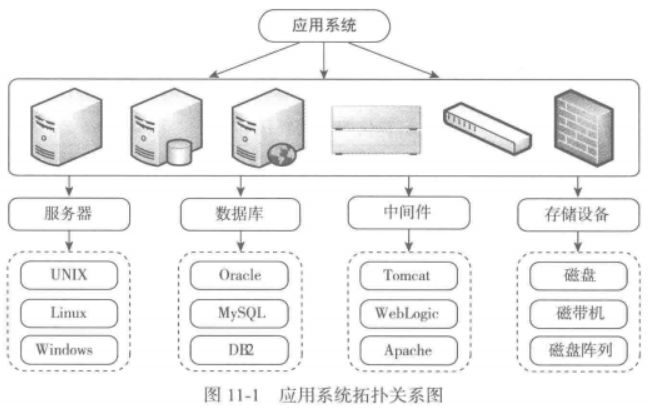
本案例的目的是通过分析历史磁盘容量相关数据,采用时间序列分析法,预测应用系统服务器磁盘已使用空间的大小,根据用户需求设定不同的预警等级,将预测值和容量值进行比较,对其结果进行预警判断,提供定制化预警的提示。
分析步骤为:
- 从数据源中选择型抽取历史数据与每天定时抽取数据。
- 对抽取的数据进行周期性分析以及数据清洗,数据变换等操作后,形成建模数据。
- 采用时间序列分析法对建模数据进行模型的构建,利用模型预测服务器磁盘已使用情况。
- 应用模型预测服务器磁盘将要使用的情况,通过预测到的磁盘使用大小与磁盘容量大小按照定制化标准进行判断。
1. 数据预处理
1.1 平稳性分析
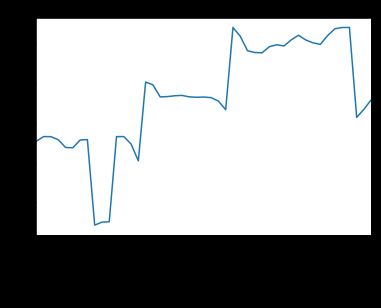
将原始的时序型数据绘图,可以观察到:磁盘的使用情况并不具有周期性,它们表现出缓慢型增长,呈现一定的趋势性,因此可以初步确认数据为非平稳性。

1.2 属性构造
原始的磁盘空间数据并不是直接可以使用的属性数据集,所以我们需要自己动手构建属性,比如

将上面两个样本的属性合并为一个样本的四个属性。代码为:
data=pd.read_excel(r"E:\PyProjects\DataSet\PyMining\Data\chapter11\demo\data\discdata.xls")
data = data[data['TARGET_ID'] == 184].copy() #只保留TARGET_ID为184的数据
# 183表示磁盘容量,而184表示磁盘已使用大小
data_group = data.groupby('COLLECTTIME') #以时间分组
def attr_trans(x): #定义属性变换函数
result = pd.Series(index = ['SYS_NAME', 'CWXT_DB:184:C:\\', 'CWXT_DB:184:D:\\','COLLECTTIME'])
result['SYS_NAME'] = x['SYS_NAME'].iloc[0]
result['COLLECTTIME'] = x['COLLECTTIME'].iloc[0]
result['CWXT_DB:184:C:\\'] = x['VALUE'].iloc[0]
result['CWXT_DB:184:D:\\'] = x['VALUE'].iloc[1]
return result
data_processed = data_group.apply(attr_trans) #逐组处理,每一天构成一组,从每一组中提取出value等
data_processed.head(10)

绘图查看下C盘和D判断已使用容量变化趋势图为:

2. 时序建模
建模流程图为:
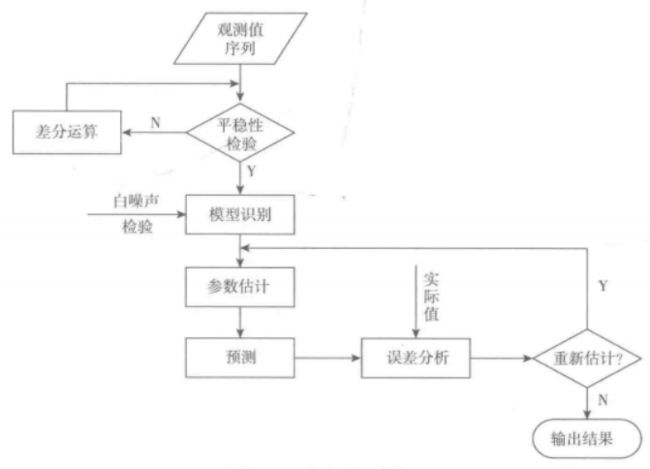
首先对观测值序列进行平稳性检验,如果不平稳,则对其进行差分处理直到差分后的数据平稳,在平稳后,对其进行白噪声检验,如果没有通过白噪声检验,就进行模型识别,识别其模型属于AR,MA,ARMA中的哪一种模型。
2.1 平稳性检测
为了确定原始数据序列中没有随机趋势或确定趋势,需要对数据进行平稳性检验,否则将会产生伪回归现象。下面采用单位根检验(ADF)的方法对时序图进行平稳性检验。
data2=data_processed.copy()
#平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
diff = 0
adf = ADF(data2['CWXT_DB:184:D:\\'])
while adf[1] > 0.05:
diff = diff + 1
adf = ADF(data2['CWXT_DB:184:D:\\'].diff(diff).dropna())
print('原始序列经过%s阶差分后归于平稳,p值为%s' %(diff, adf[1]))
结果为:原始序列经过1阶差分后归于平稳,p值为2.702061091530161e-06
2.2 白噪声检验
为了验证序列中有用的信息是否已被提取完毕,需要对序列进行白噪声检验,如果序列检验为白噪声序列,说明序列中有用的信息已经被提取完毕,剩下的全都是随机扰动,无法进行预测和使用。下面采用LB统计量的方法进行白噪声检验。
#白噪声检测
from statsmodels.stats.diagnostic import acorr_ljungbox
[[lb], [p]] = acorr_ljungbox(data2['CWXT_DB:184:D:\\'], lags = 1)
if p < 0.05:
print('原始序列为非白噪声序列,对应的p值为:%s' %p)
else:
print('原始该序列为白噪声序列,对应的p值为:%s' %p)
[[lb], [p]] = acorr_ljungbox(data2['CWXT_DB:184:D:\\'].diff().dropna(), lags = 1)
if p < 0.05:
print('一阶差分序列为非白噪声序列,对应的p值为:%s' %p)
else:
print('一阶差分该序列为白噪声序列,对应的p值为:%s' %p)
结果为:

2.3 模型识别
采用极大似然比方法进行模型的参数估计,估计各个参数的值然后针对各个不同模型,采用BIC信息准则对模型进行定阶,确定p,q参数,从而选择最优模型。
from statsmodels.tsa.arima_model import ARIMA
#定阶
pmax = int(len(xdata)/10) #一般阶数不超过length/10
qmax = int(len(xdata)/10) #一般阶数不超过length/10
bic_matrix = [] #bic矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try: #存在部分报错,所以用try来跳过报错。
tmp.append(ARIMA(xdata, (p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix) #从中可以找出最小值
p,q = bic_matrix.iloc[:,:-1].stack().argmin() #先用stack展平,然后用idxmin找出最小值位置。
print(u'BIC最小的p值和q值为:%s、%s' %(p,q))
结果是:BIC最小的p值和q值为:1、1
2.4 模型检验
模型确定后,需要检验其残差序列是否为白噪声,如果不是白噪声,说明残差中还存在有用的信息,需要修改模型或者进一步提取。
from statsmodels.tsa.arima_model import ARIMA #建立ARIMA(0,1,1)模型
arima = ARIMA(xdata, (0, 1, 1)).fit() #建立并训练模型
xdata_pred = arima.predict(typ = 'levels') #预测
pred_error = (xdata_pred - xdata).dropna() #计算残差
lagnum = 12 #残差延迟个数
from statsmodels.stats.diagnostic import acorr_ljungbox #白噪声检验
lb, p= acorr_ljungbox(pred_error, lags = lagnum)
h = (p < 0.05).sum() #p值小于0.05,认为是非白噪声。
if h > 0:
print(u'模型ARIMA(0,1,1)不符合白噪声检验')
else:
print(u'模型ARIMA(0,1,1)符合白噪声检验')
结果:模型ARIMA(0,1,1)不符合白噪声检验,说明残差序列中还有有用的信息?
2.5 误差计算
#计算误差
abs_ = (data[u'预测值'] - data[u'实际值']).abs()
mae_ = abs_.mean() # mae
rmse_ = ((abs_**2).mean())**0.5 # rmse
mape_ = (abs_/data[u'实际值']).mean() # mape
print(u'平均绝对误差为:%0.4f,\n均方根误差为:%0.4f,\n平均绝对百分误差为:%0.6f。' %(mae_, rmse_, mape_))
参考资料:
《Python数据分析和挖掘实战》张良均等