Apache HAWQ是目前社区比较火的一种SQL-on-Hadoop方案,由Pivotal公司开发并贡献给了Apache社区。HAWQ的技术与构架源自于业界顶尖的MPP数据库Greenplum,是传统的高性能分析型数据库与Hadoop相结合的一次尝试,其兼具了MPP架构数据库卓越的分析性能与Hadoop的可高扩展性,容错性。
本文主要描述HAWQ的基本概念,在HDP集群中的部署以及初步测试。
HAWQ架构概述
HAWQ的架构如下图所示:
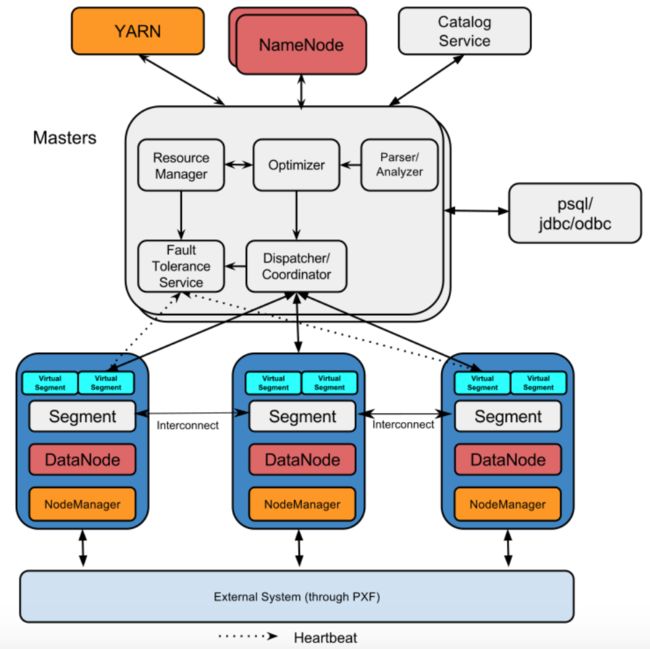
HAWQ架构是分布式系统中经典的master-slave模式,主要分为下面三个服务:
HAWQ master:HAWQ master是整个系统的入口点,负责接收和认证客户端的连接请求,处理客户端提交的SQL命令,解析并优化查询,向集群的各个Segemt节点下发查询并合理分布负载,协调从各Segemt节点返回的子查询结果,向客户端程序返回合并后的最终处理结果。HAWQ master内部由HAWQ Resource Manager,HAWQ Catalog Service,HAWQ Fault Tolerance Service,HAWQ Dispatcher等组件组成。HAWQ master还需要维护global system catalog,global system catalog是系统表的集合,其中包含了HAWQ集群的元数据信息;HAWQ master上不包含任何用户数据,所有数据都在HDFS上。
HAWQ segment:HAWQ segment是HAWQ集群的计算节点,负责大规模查询的并行处理;HAWQ segment节点本身不存储任何数据和元数据,所有需要处理的数据都存储在底层的HDFS上,segment本身只负责计算,是无状态的;HAWQ master在分派SQL请求给Segment时会附带相关的元数据信息,元数据信息里包含了需要处理的表的HDFS URL,Segment通过元数据里的HDFS URL访问SQL请求需要处理的数据。
PXF agent:PXF(HAWQ Extension Framework)是一个允许HAWQ访问外部系统数据的可扩展的框架,PXF内置了访问HDFS文件,HBase表以及Hive表的连接器(connectors),PXF还可以通过和HCatalog集成来直接访问Hive表;PXF允许用户通过开发新的连接器来访问其它并行数据存储和处理引擎。PXF agent是PXF的服务,需要部署在集群的Segment节点上。
在HAWQ集群中,master节点上需要启动HAWQ master,HDFS namenode和Yarn resourcemanager;每个slave节点上需要启动HAWQ segment,PXF agent,HDFS datanode和Yarn nodemanager。HAWQ集群的数据直接存储在HDFS上,可以集成Yarn来进行计算资源管理(HAWQ自身也提供了不依赖于Yarn的Standalone模式,Ambari部署的HAWQ默认是Standalone模式,用户可以在Ambari页面上自行切换);HAWQ也可以通过PXF查询HBase和Hive的库表。
用户通过连接master节点来与HAWQ集群交互,可以使用数据库客户端程序(psql)或者JDBC和ODBC这样的API连接HAWQ的库表。
用户通过连接HAWQ master服务与HAWQ集群交互。和大多数Hadoop组件类似,HAWQ也提供了命令行和API两种交互方式:由于HAWQ继承自Greemplum/PostgresSQL技术栈,所以天然的选择了PostgresSQL的客户端程序psql作为命令行工具去连接HAWQ库表,提交SQL查询;HAWQ支持JDBC和ODBC作为编程接口,第三方程序可以通过JDBC/OCBC方式访问HAWQ。
通过ambari安装HAWQ
Pivotal官方提供了HAWQ的发行版,即Pivotal HDB。
Hortonworks的Hadoop发行版Hortonworks Data Platform(HDP)从2.2.4.2版本开始支持集成Pivotal HDB,HDP的用户可以直接在HDP集群中利用Ambari完成HAWQ的敏捷部署和运维。HAWQ版本和HDP/ambari以及操作系统版本的对应关系如下图所示:

从上图可知,HAWQ的最新发布版是2.3.0.0,对应的HDP版本是2.6.1,ambari版本是2.5.1。而且,HAWQ直到最近的两个发布版才支持7.2以上版本的RHEL/CentOS。
设置本地源
首先需要从HAWQ官网(network.pivotal.io/products/pivotal-hdb)下载HAWQ安装包的tar.gz文件到集群的yum源上。HAWQ安装包下载完成后,按如下步骤完成HAWQ的本地源搭建:
- 在yum服务器上创建存放HAWQ安装文件的目录,解压之前下载的文件并设置权限:
[root@host-10-1-236-146 ~]# mkdir /staging
[root@host-10-1-236-146 ~]# chmod a+rx /staging
[root@host-10-1-236-146 ~]# cd /staging/
[root@host-10-1-236-146 staging]# tar xvf hdb-2.3.0.0-4600.el7.tar.gz
[root@host-10-1-236-146 staging]# cd hdb-2.3.0.0/
- 运行HAWQ安装包里的setup_repo.sh脚本(注意将脚本中的DOCUMENT_ROOT修改为当前yum服务器的实际目录,其默认为/var/www/html)完成yum源配置,生成repo文件:

- 将生成的yum repo文件拷贝到HDP集群的ambari节点的/etc/yum.repo.d/下面
- 在ambari节点上运行yum clean all && yum update测试hawq的yum源是否生效
安装HAWQ Ambari plug-in
Ambari本身不支持HAWQ的安装,ambari正常安装启动起来之后在服务添加页面是看不到HAWQ的,所以需要安装Pivotal开发的HAWQ插件。HAWQ Ambari plug-in会提供HAWQ的安装和服务管理脚本。
可以按照如下步骤安装HAWQ Ambari plug-in:
- 在ambari server上安装HAWQ Ambari plug-in的rpm包:
[root@host-10-1-241-55 ~]# yum install -y hawq-ambari-plugin
(安装完成之后,HAWQ Ambari plug-in会在ambari server上创建一个本地目录(/var/lib/hawq)来放置一些所需的脚本和模版文件)
- 通过运行HAWQ Ambari plug-in提供的python脚本(/var/lib/hawq/add-hawq.py)为Ambari server添加HAWQ的源(脚本执行时需要确保ambari-server服务正常运行):
./add-hawq.py --user admin --password admin --stack HDP-2.6 --hawqrepo http://host-10-1-236-146/hdb-2.3.0.0
(脚本的参数依次为:ambari server的admin用户名,ambari server的admin用户密码,HDP stack版本,hawq源的地址)
- 重启ambari-server
- 登陆到Ambari UI,既可在服务添加页面看到HAWQ相关的服务安装选项:

通过Ambari页面安装HAWQ
安装好HAWQ Ambari plug-in并将Pivotal HDB的本地源加入Ambari后,我们就可以通过Ambari的图形化界面进行HAWQ的安装了。
安装步骤如下:
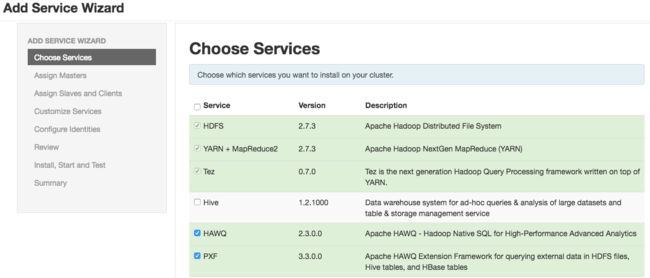
- 在Ambari的Add Service Wizard里,选择HAWQ和PXF
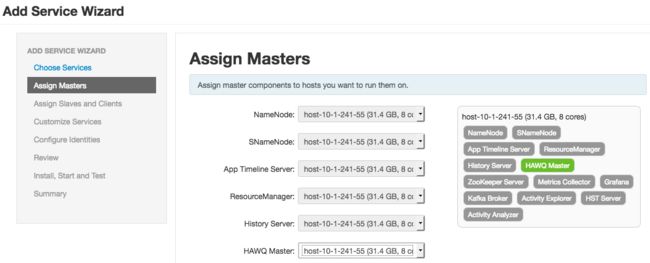
- 分配HAWQ master和HAWQ Segment,PXF Agent到集群中的机器:

- 配置HAWQ master和segment的数据存储目录,ambari默认设置为服务器本地的/data/hawq/master和/data/hawq/segment目录;
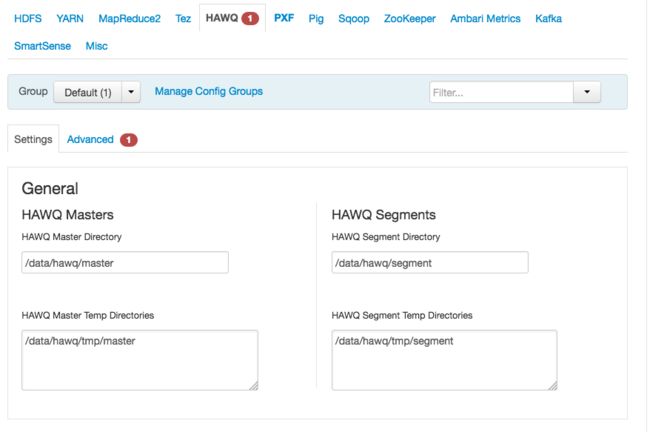
另外,需要确保hawq的启动用户(Ambari默认为gpadmin)可以访问上述数据存储目录,否则HAWQ服务将启动失败。
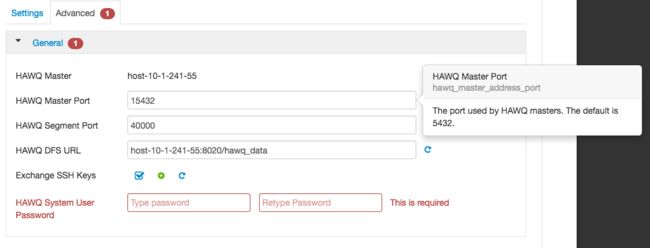
- 配置HAWQ Master服务的监听地址,Ambari默认值为5432,这个端口也是PostgresSQL的默认监听端口,所以如果HAWQ Master本地并安装启动了PostgresSQL的话,HAWQ Master就需要使用其他端口,否则会造成端口冲突。
- 选择下一步Review整个HAWQ集群的配置

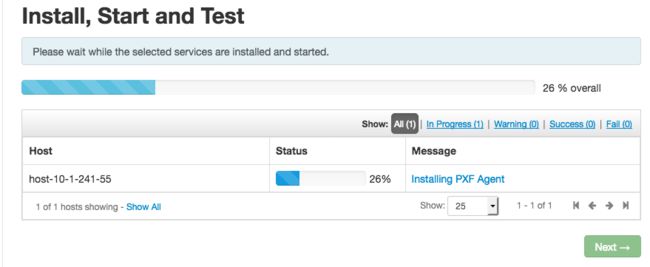
- 点击Deploy部署HAWQ集群
- 如果HAWQ的部署过程中出现类似于下图的错误,说明集群中缺少HAWQ所需的依赖;需要管理员在集群中的每台机器上手动安装下图中Ambari错误提示中缺少的三个rpm包:libsasl,protobuf,thrift;需要注意的是,手动安装的上述三个rpm包的版本和适配的操作系统版本需要和HAWQ版本以及当前集群的操作系统一致。

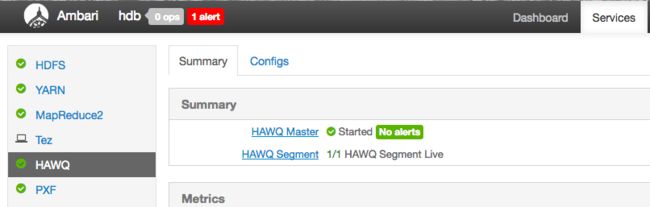
- 部署完成之后,在Ambari页面查看HAWQ各个组件的状态
- 如果在HAWQ启动和后续的使用过程中,出现和HDFS有关的问题,可能需要调整HDFS的参数,具体可以参考Pivotal官网的在线文档(Procedure部分的第9小节):hdb.docs.pivotal.io/212/hdb/install/install-ambari.html
- 由于HAWQ自身没有像HDFS或者Yarn那样提供用于服务监控和配置管理的图形用户界面(Web UI),所以用户需要通过Ambari完成HAWQ的服务管理,服务监控以及配置管理相关任务的图形化操作。
- 如果在RHEL/CentOS 7.2的环境上部署HAWQ,会遇到从gpadmin用户logout之后re-login,就无法访问HAWQ的情况(无法执行HAWQ管理命令,也无法用psql提交sql):

HAWQ master的日志(/data/hawq/master/pg_log/hawq-xxx.csv)报错如下:

导致这个问题的原因是,RHEL/CentOS 7.2的systemd会在用户退出登陆后默认清除信号量(semaphores),这会影响与HAWQ的交互。解决办法是:停止HAWQ集群,以root身份修改systemd的配置,关闭RemoveIPC选项并重启systemd-logind,然后重新拉起HAWQ集群:

(参考:Re: problem on AMD FX-8350)
测试HAWQ
HAWQ在HDP集群中安装启动完成后,我们就可以开始使用HAWQ进行数据分析了。
设置HAWQ运行环境
Ambari会为HAWQ集群创建一个名为gpadmin(HAWQ的技术架构和源代码出于Greenplum,所以很多配置项的命令都以gp开头~)的服务账户,HAWQ相关服务由该用户身份启动,所以用户执行HAWQ的管理命令(如hawq,hawq_ctl等)或者提交SQL也需要gpadmin的用户身份。
在HAWQ集群上设置HAWQ运行环境需要如下工作:
- 登录到HAWQ集群中任何一个节点并切换到到gpadmin用户
- Source HAWQ的环境变量设置脚本:/usr/local/hawq/greenplum_path.sh
- 如果部署HAWQ集群时没有使用HAWQ master的默认端口(5432),则需要增加一个指向HAWQ master实际配置的端口的环境变量:PGPORT

- 可以上述设置HAWQ环境变量的相关命令写入gpadmin用户的~/.bashrc中,这样每当用户切换到gpadmin时候就会自动完成环境变量的设置
HAWQ运行环境设置好后可以进行简单的环境测试,如:
- 执行HAWQ的管理命令,查看HAWQ集群状态
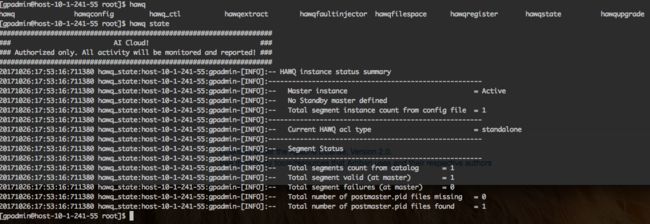
- 通过psql连接HAWQ库:
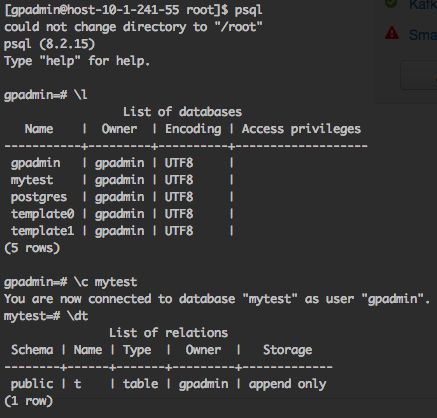
导入测试数据
Pivotal官方提供了用于测试HAWQ的开源项目:GitHub - pivotalsoftware/hawq-samples,其展示了一个典型的零售业的OLAP场景。hawq-samples里包含了描述零售数据和零售数据的维度信息的数据压缩文件,用于创建事实表,维度表和pxf外部表的SQL脚本,用于批量加载测试数据到HDFS的shell脚本等。
按照如下步骤在HAWQ里导入hawq-samples的数据并建立OLAP模型:
- 从github下载hawq-samples并checkout到对应分支,然后将表示HAWQ工作目录的环境变量(HAWQGSBASE)指向hawq-samples的文件目录:

hawq-samples的目录结构说明如下:
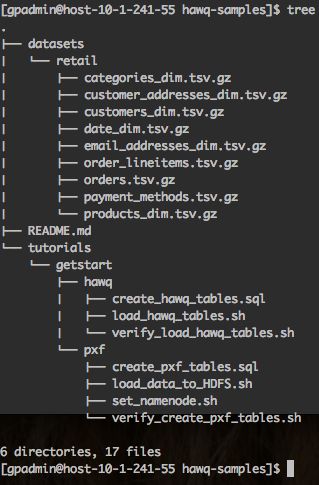
datasets/retail/ :Retail demo的数据集文件(.tsv.gz格式)
tutorials/getstart/hawq/:创建HAWQ表的SQL和Shell脚本
tutorials/getstart/pxf/:创建PXF外部表的SQL和Shell脚本
- 为Retail demo创建一个HAWQ库和一个HAWQ schema(HAWQ schema是HAWQ库的一个namespace,包含了一组表,数据类型,函数和操作符,一个HAWQ库可以包含多个schema),创建的HAWQ为hawqgsdb,schema为retail_demo:

- 创建事实表,通过执行hawq-samples提供的create_hawq_tables.sql脚本在hawqgsdb.retail_demo下面创建两张事实表:orders_hawq代表零售订单的详细内容,orders_lineitems_hawq代表订单条目的详细内容
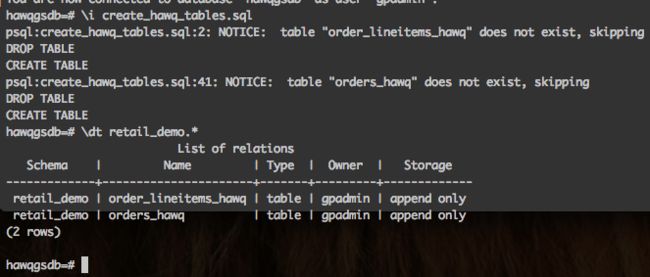
- 加载事实表的数据到HAWQ,通过执行hawq-samples提供的load_hawq_tables.sh脚本将retail demo的数据加载到HAWQ的表中,load_hawq_tables.sh脚本使用zcat命令解压缩.tsv,gz格式的数据文件,调用SQL命令copy加载解压后的csv文件到hawqgsdb.retail_demo的两张事实表中
- 验证事实表,执行hawq-samples提供的verify_load_hawq_tables.sh脚本对hawqgsdb.retail_demo的两张事实表进行count操作,验证数据已经加载
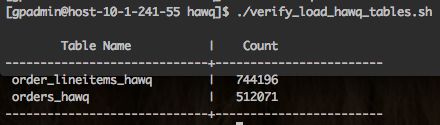
- 加载维度数据到HDFS,执行hawq-samples提供的load_data_to_HDFS.sh脚本加载维度数据到HDFS中(需要确保gpadmin具有sudo权限)
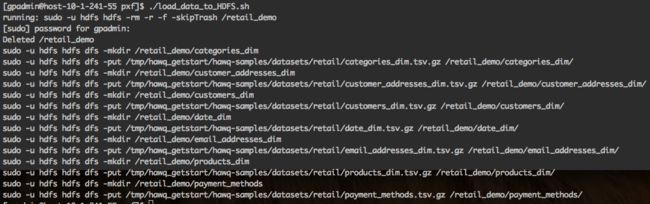
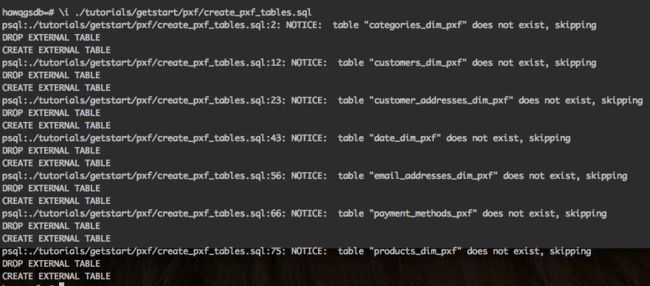
- 创建维度表,执行hawq-samples提供的create_pxf_tables.sql脚本在hawqgsdb.retail_demo下面创建维度表;由于维度数据已经加载在HDFS上,所以只需要通过pxf创建HAWQ的外部表来关联HDFS上的维度数据,而无需再次加载数据到HAWQ的内部表中
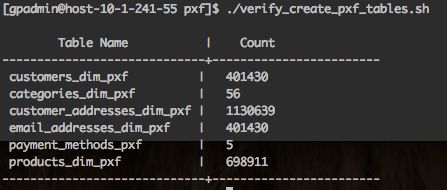
- 验证维度表,执行hawq-samples提供的verify_create_pxf_tables.sh脚本对hawqgsdb.retail_demo的所有维度表进行count操作,验证维度表已经建立成功
执行SQL查询
在hawq-samples中,retail demo数据存储在HAWQ内部表中,维度数据存储在HDFS外部源中,用户需要同时使用HAWQ内部和PXF外部表来关联和查询retail demo数据。在生产环境中,同时使用内部表和外部数据源的情况也是比较常见的。
以下是一个简单的SQL查询,同时使用了存储在HAWQ内部描述订单数据的事实表orders_hawq和存储在HDFS上描述客户信息的维度表customers_dim_pxf,确定购买了礼券的所有用户的姓名和email地址,同时统计购买的订单总额:
SELECT substring(retail_demo.orders_hawq.customer_email_address for 37) AS email_address, last_name,sum(retail_demo.orders_hawq.total_paid_amount::float8) AS gift_cert_total FROM retail_demo.customers_dim_pxf, retail_demo.orders_hawq WHERE retail_demo.orders_hawq.payment_method_code='GiftCertificate' AND retail_demo.orders_hawq.customer_id=retail_demo.customers_dim_pxf.customer_id GROUP BY retail_demo.orders_hawq.customer_email_address, last_name ORDER BY last_name limit 10;
在psql中执行上述SQL查询,结果如下:

结论
Apache HAWQ作为一款原生的SQL-on-Hadoop引擎,兼具了MPP数据库强大的分析性能和Hadoop的高可扩展性;在HDP集群里可以通过Ambari进行快速部署和集中管理,为HDP集群提供高性能分析能力。Apache HAWQ目前尚处于Apache的孵化阶段,在生产环境下的部署还比较少,缺乏生产环境的严苛校验,其稳定性,查询性能以及容错性尚待进一步的测试和优化。但是,作为Hortonworks阵营里唯一可用的原生SQL-on-Hadoop引擎,其发展还是可以期待一下的,未来期待它能够替代Cloudera Impala :-)