MySql高级(一)
1、MySQL逻辑架构
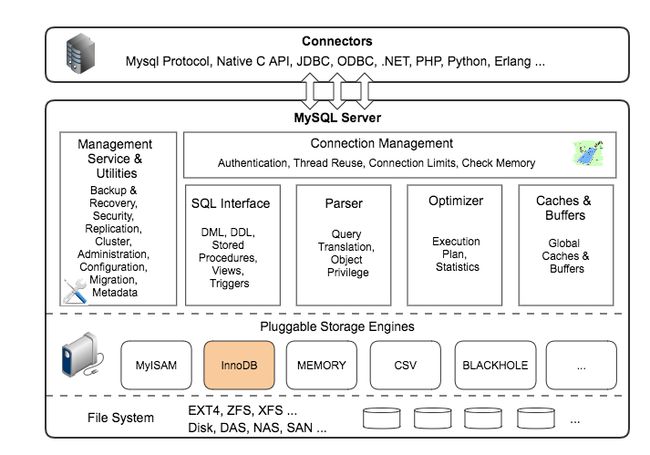
首先,mysql的查询流程大致是:
mysql客户端通过协议与mysql服务器建连接,发送查询语句,先检查查询缓存,如果命中,直接返回结果,否则进行语句解析,也就是说,在解析查询之前,服务器会先访问查询缓存(query cache)——它存储SELECT语句以及相应的查询结果集。如果某个查询结果已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可,这将大大提高系统的性能。
语法解析器和预处理:首先mysql通过关键字将SQL语句进行解析,并生成一颗对应的“解析树”。mysql解析器将使用mysql语法规则验证和解析查询;预处理器则根据一些mysql规则进一步检查解析数是否合法。
查询优化器当解析树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。。
然后,mysql默认使用的BTREE索引,并且一个大致方向是:无论怎么折腾sql,至少在目前来说,mysql最多只用到表中的一个索引。
2、存储引擎
#查看mysql存储引擎
show engines;
#查看mysql当前默认的存储引擎
show variables like '%storage_engine%';
2.1、MyISAM和InnoDB对比
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 外键 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其它行有影响,适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响 |
| 关注点 | 性能 | 事务 |
| 默认安装 | 是 | 是 |
| 默认使用 | 否 | 是 |
| 自带系统表使用 | 是 | 否 |
3、索引优化
3.1、SQL性能下降的原因
(1)索引失效
(2)关联查询太多join
(3)服务器调优及各个参数设置
3.2、SQL的加载顺序
3.2.1、手写

3.2.2、机读

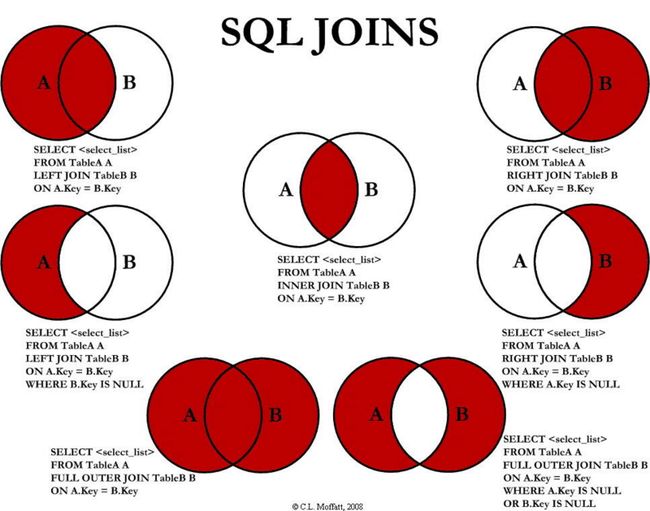
3.3、七种Join
4、SQL预热
4.1、创建表
CREATE TABLE `t_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `t_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
empno int not null,
PRIMARY KEY (`id`),
KEY `idx_dept_id` (`deptId`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO t_dept(deptName,address) VALUES('华山','华山');
INSERT INTO t_dept(deptName,address) VALUES('丐帮','洛阳');
INSERT INTO t_dept(deptName,address) VALUES('峨眉','峨眉山');
INSERT INTO t_dept(deptName,address) VALUES('武当','武当山');
INSERT INTO t_dept(deptName,address) VALUES('明教','光明顶');
INSERT INTO t_dept(deptName,address) VALUES('少林','少林寺');
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('风清扬',90,1,100001);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('岳不群',50,1,100002);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('令狐冲',24,1,100003);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('洪七公',70,2,100004);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('乔峰',35,2,100005);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('灭绝师太',70,3,100006);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('周芷若',20,3,100007);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('张三丰',100,4,100008);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('张无忌',25,5,100009);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('韦小宝',18,null,100010);4.2、预热题目
#所有门派的人员信息(A、B两表共有)
SELECT * FROM t_dept INNER JOIN t_emp ON t_dept.`id` = t_emp.`deptId`;
#列出所有用户,并显示其机构信息 (A的全集)
SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp.`deptId`=t_dept.`id`;
#列出所有门派 (B的全集)
SELECT * FROM t_dept
# 所有不入门派的人员 (A的独有)
SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp.`deptId`=t_dept.`id` WHERE t_emp.`deptId` IS NULL
#所有没人入的门派 (B的独有)
SELECT * FROM t_dept LEFT JOIN t_emp ON t_dept.`id`=t_emp.`deptId` WHERE t_emp.`deptId` IS NULL
#列出所有人员和机构的对照关系(AB全有)
#MySQL Full Join的实现 因为MySQL不支持FULL JOIN,下面是替代方法
#left join + union(可去除重复数据)+ right join
SELECT * FROM t_emp A LEFT JOIN t_dept B ON A.deptId = B.id
UNION
SELECT * FROM t_emp A RIGHT JOIN t_dept B ON A.deptId = B.id
#列出所有没入派的人员和没人入的门派(A的独有+B的独有)
SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp.`deptId`=t_dept.`id` WHERE t_emp.`deptId` IS NULL
UNION
SELECT * FROM t_dept LEFT JOIN t_emp ON t_dept.`id`=t_emp.`deptId` WHERE t_emp.`deptId` IS NULL