MapReduce编程模型:
input (输入)→splitting(将文件拆开)→mapping(按照分隔符将单词分开)→shuffling(归并符合规则相同的单词)→reducing(根据不同的需求取出不同的结果)→finalize(最总结果)

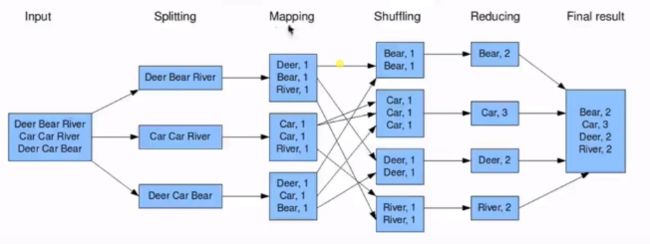
执行步骤:1.准备map处理的输入数据
2.mapper处理
3.shuffle
4.reduce处理
5.结果输出
基础知识:
public class Mapper
public Mapper(){}
}
KEYIN:map任务读数据的key类型,offset,是每行数据起始位置的偏移量,Long型
VALUEIN:map任务读数据的value类型,就是一行行字符串,string型
KEYOUT:map方法自定义实现输出的key的类型,string
VALUEOUT:map方法自定义实现输出的value的类型,integer
但是long,string,integer是Java里的数据类型,
Hadoop自定义数据类型:序列化和反序列化
Long→LongWritable
String→Text
Integer→IntWriteable
public class xxx extends Reducer
前两个“Text,IntWritable”是接收的map输出内容的类型,后面是输出内容类型
利用driver将map和reducer联系起来:


当你的out无法输出时,可能是因为文件权限不够(没有写),这是需要添加一行代码

当你运行一遍后output文件夹就已经存在了,再次运行的话就会报路径已经存在的错,这时可以通过代码判断如果输出路径已经存在的话,则先删除路径:
FileSystem fileSystem = FileSystem.get(new URL(str :"hdfs://192.168.199.233:8020"),configuration,user:"hadoop"/*给权限*/);
Path outputpath = new Path(pathString:"路径");
if(fileSystem.exists(outputpath) ){
fileSystem.delete(outputpath,recursive:true);
}
当文件中存在大小写不同的单词,你想归并它时,可以利用 word.toLowerCase
例如Word 1 word 1,输出会变为word 2
![]()