
关注小编的公众号,后台回复“进群”,一起来交流学习吧!

今天给大家介绍的文章标题是:《FAT-DeepFFM: Field Attentive Deep Field-aware Factorization Machine》
文章下载地址是:https://arxiv.org/abs/1905.06336
从本系列的第一篇开始,咱们已经陆续介绍过FM模型、FFM模型、DeepFM模型、NFM模型和AFM模型。今天给大家介绍的是FM家族中的另一个新朋友FAT-DeepFFM(全称是Field Attentive Deep Field- aware Factorization Machine),是由新浪微博的张俊林老师提出的哟,一起来学习下。
1、背景
点击率预估是计算广告以及推荐系统中非常重要的工作,学者们也提出了许多有效的模型来做CTR预估任务。如LR、树模型、贝叶斯模型、FM模型、FFM模型,以及深度学习模型如DeepFM、Wide & Deep模型等等。
同时,CTR模型中也经常借鉴其他领域的一些常用方法,如计算机视觉和自然语言处理中常用的方法,最为常见的是Attention机制。使用Attention机制可以从众多的特征中选择出比较重要的特征,并过滤掉一些无关特征。将注意力机制和深度学习CTR预估模型相结合,如AFM模型已经被学者们提出,AFM模型结构如下:
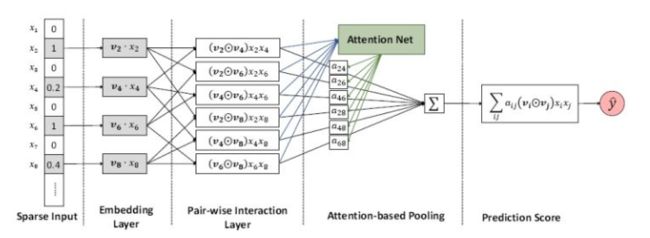
可以看到,上面的AFM模型,是在特征进行交叉之后,再对交叉特征进行权重计算,但本文认为,在特征进行交叉之前,对特征的重要性进行一个计算也十分重要。当特征为n个时,交叉后计算重要性的权重个数为n的平方,但是交叉前计算特征重要性的话,只需要计算n个权重。这么做的话在特征比较多的时候,对计算资源的节省是十分明显的。
好了,接下来,咱们就一步步来看看俊林老师提出的模型吧。
2、DeepFFM模型
在介绍FAT-DeepFFM之前,先介绍DeepFFM模型长什么样子,因为这个模型对大家来说应该也相当陌生。
2.1 FM模型
FM模型对每一个特征赋予一个k维的向量,并通过对应向量的内积来当作特征交叉的权重,其预估公式如下:
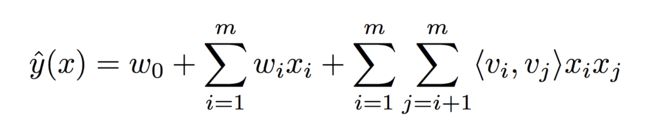
2.2 FFM模型
相较于FM模型,FFM模型提出了Field的概念,假设有n个域的话,每一个特征都对应了n-1个k维的向量,其预估公式如下:
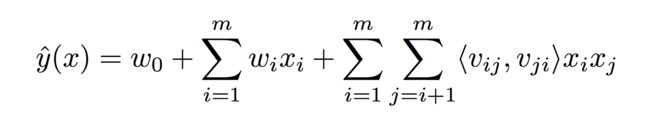
2.3 DeepFFM模型
FM和深度神经网络相结合,我们已经有了DeepFM模型,很自然的,FFM和深度神经网络相结合,就有了DeepFFM模型,其模型结构如下图所示:
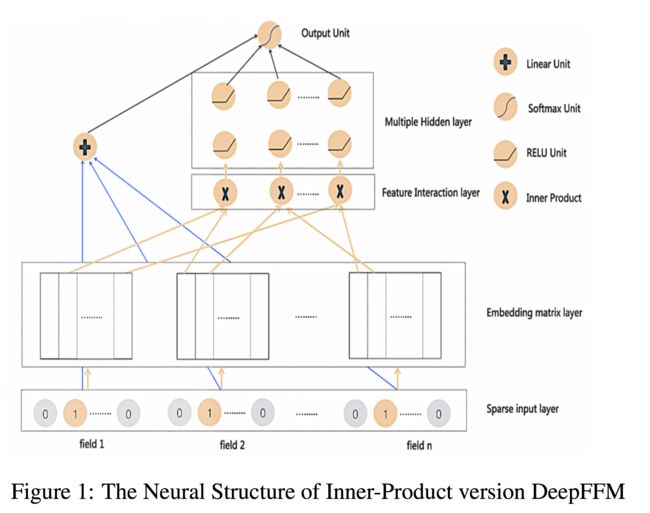
如图所示,我们的特征首先被转换成一堆one-hot encoding,每一个one-hot encoding可以看作一个field,如性别、周几等等。
还是想说一下本文的特征和field定义,比如有两个域,性别和周几,那么特征数量是2+7=9,当然你也可以认为是3 + 8=11,两个域各加一个未知选项嘛。
接下来在Embedding matrix layer,每一个特征将会得到一个对应的Embedding Matrix,简称EM,如对于第I个特征:
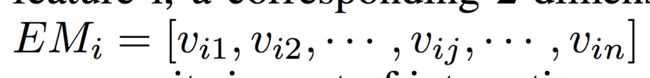
假设有n个域,每个特征对应的EM的大小为k * n,整个EM层的大小为k * n * n (这里每个特征对应n个k维向量,而非n-1个,但实际参与计算和更新的只有n-1个)。
接下来,有两种方式得到DNN部分的输入,分别是计算内积和哈达玛积:
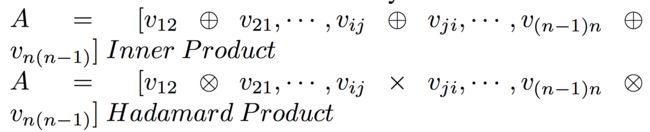
哈达玛积的计算公式如下(文中这里感觉写错了,圆圈中间应该是乘号而非加号):
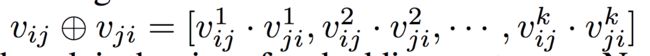
可以看到,如果使用内积的话,输入DNN的维度是n(n-1)/2的,如果使用哈达玛积的话,输入DNN的维度应该是kn(n-1)/2。随后经过多层神经网络:
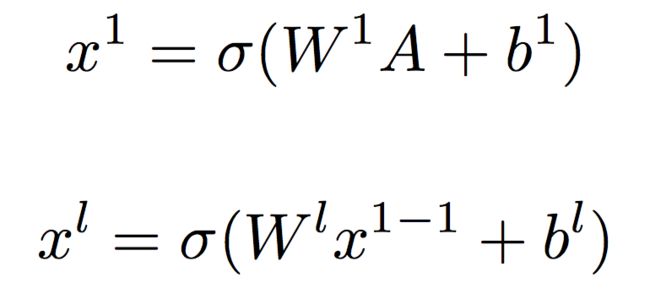
而最终DeepFFM的输出为:
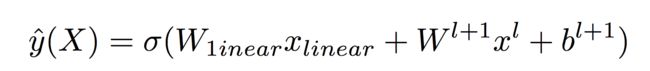
至此DeepFFM就介绍完了,和DeepFM有点不一样,DeepFM保留了FM中的一次项、二次项(特征交叉项),但DeepFFM中,只计算了一次项,二次项没有保留,也许是出于计算时间的考虑吧。
3、FAT-DeepFFM模型
好了,接下来介绍FAT-DeepFFM模型,与大多数模型借鉴的自然语言处理中的注意力机制不同,这里引入的注意力机制来源于图像领域的SENet,一起来看一下。
FAT-DeepFFM模型的整体的结构如下:
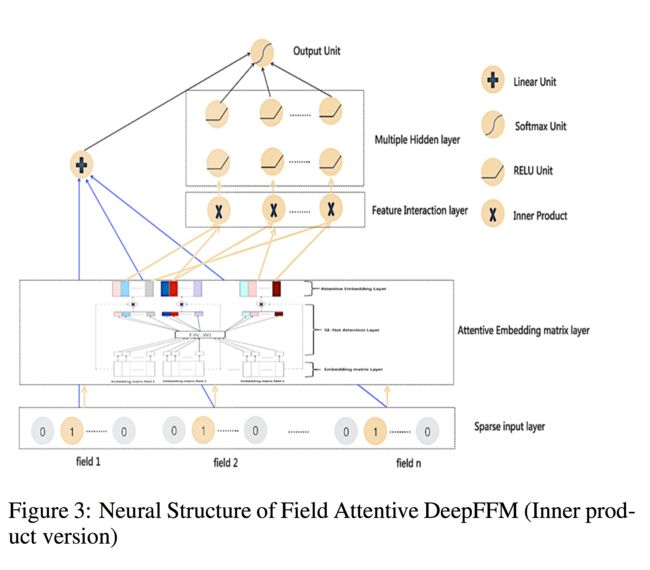
而注意力机制发挥作用的部分是:
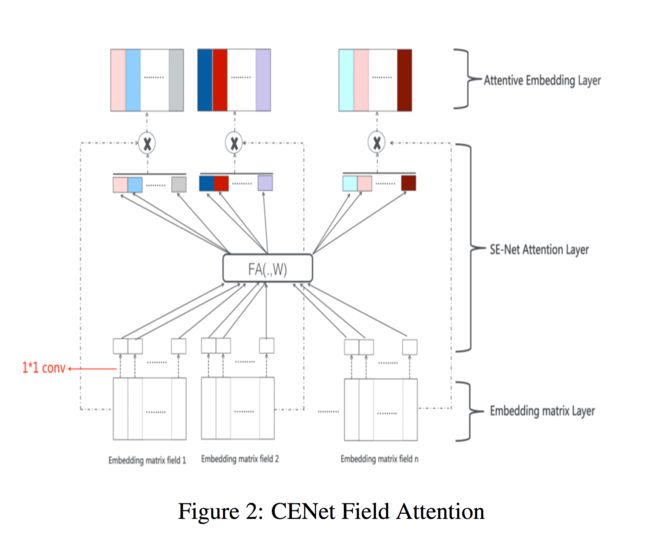
论文中提出的Attention机制称为CENet Field Attention,全称为Compose-Excitation network (CENet) attention mechanism。接下来,咱们就来一步步解读这个Attention过程。
3.1 CENet Field Attention
这里Attention的过程分为两个阶段,分别称作Compose阶段和Excitation阶段。
Compose阶段
在Compose阶段,需要把每一个向量压缩成一维的值,每一个特征对应的Embedding Matrix是k * n,压缩之后变为一个n维的向量,如下图所示:
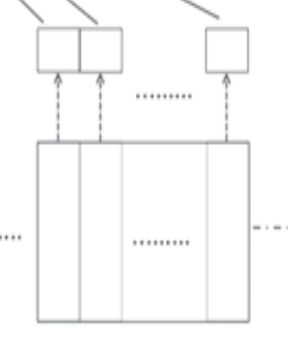
假设当前是第i个特征,对应的特征矩阵是EMi,EMi中的列向量分别是vi1,vi2,...,vin其压缩后对应的向量是zi。
对于SENet来说,直接对每一列使用max pooling来得到值,具体的,对于zi中的第f个值,通过下面的式子得到:

在本文中,对这种方式进行了一定的修改,使用1维卷积:

这里的卷积核是1 * 1的。有关1维卷积以及1*1卷积核,这里我一开始理解有误,认为论文里写的是错误的,不过经指正这里应该是没错的,感兴趣的小伙伴可以看下1维卷积、1*1卷积以及1*1卷积和全连接的区别。待我总结归来,一定将经验分享给大家。
Excitation阶段
经过Compose阶段,每个特征对应的Embedding Matrix,都得到了一个对应的n维压缩向量,例如特征i对应的n维压缩向量计作DVi,那么在Excitation阶段,我们首先对DV进行横向拼接:
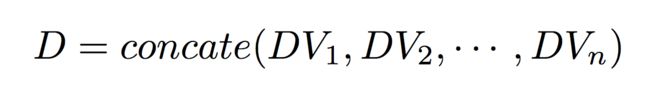
这里D是n * n维的向量,接下来将D输入到两层全连接网络中:

从上图可以看出,经过全连接网络之后输出的S仍然是n * n维的向量,S便是我们想要得到的attention score。
利用attention score就可以对我们Embedding Matrix进行加权了,例如第i个特征:

到了这一步,剩下的就跟DeepFFM里面所讲的一致啦,这里就不细讲啦。
4、实验及总结
论文在两个数据集上进行了实验,结果如下:
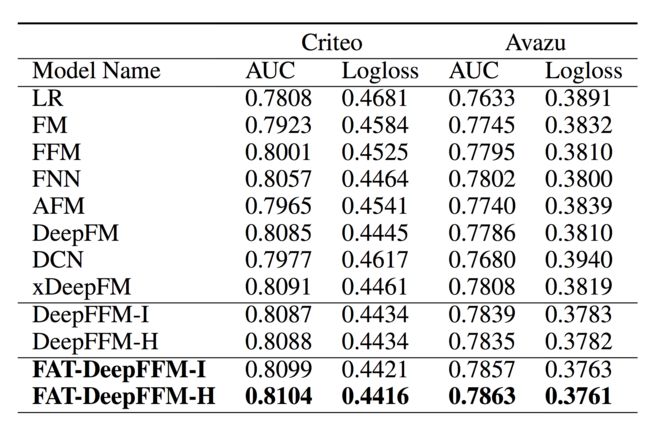
可以发现,FAT-DeepFFM的效果好于其他对比模型,同时,使用哈达玛积的时候效果会比使用内积效果更好。
这篇论文应该放出来有一段时间了,俊林老师也在知乎上介绍了这个思路,今天看了一下其主要创新点还是在于attention的计算吧,借鉴了图像领域的思路,还是值得尝试一下的。