前言
随着小步快跑、快速迭代的开发模式被越来越多的企业认同和采用,应用的发布、升级频率变得越来越频繁。进入云原生时代后,越来越多的应用被容器化,如何方便地对容器类应用进行平稳的发布和升级受到了广泛关注。
使用 Kubernetes 的 RollingUpdate 可以方便地实现滚动发布,但这种方式只会检查 pod 本身的状态,缺乏对服务整体 SLA 的感知。一种更科学的方式是将发布与监控指标联动起来。当指标出现异常时,能及时地停止发布或进行回滚。本文将以运行在 kubernetes 中的微服务应用 podinfo 为例介绍如何实现发布与监控的联动。
监控方法简介
现代系统中,我们面对的监控数据呈现出了爆炸性的增长趋势。从监控维度上看,包括宿主机、编排工具、容器、应用等。同时,每个维度又包含成百上千个可监控的指标。面对如此丰富的数据,如何及时地发现问题,如何快速地定位系统的性能瓶颈,变得越来越困难。本章介绍的 USE 方法和 RED 方法将为系统的可观测性提供良好的指导。
USE 方法
USE 方法以系统使用的资源作为观测对象,提出了一套快速定位系统性能瓶颈的方法论。对于每一类资源,它建议关注如下指标:
- Utilization - 资源的使用情况,通常以一个时间段的百分比表示,如最近一分钟内存的平均使用率是 90%。很高的使用率往往是系统性能瓶颈的标志。
- Saturation - 资源的超载程度,得不到资源的任务通常会被放入队列,因此可用队列长度或排队时间来度量,如 CPUs 的运行时队列长度平均是 4。
- Errors - 错误事件的个数,如网卡在数据包传输过程发生了 50 次冲突。当错误持续发生从而导致性能下降时需要特别关注。
基于上述指标并结合 USE 提供的策略,我们能快速定位常见的性能问题。
RED 方法
RED 方法是 Weaveworks 的工程师基于 Google 的“四个黄金指标”并结合自己的实践经验,提出了一套适合于微服务场景的应用监控方法论。它从更上层、以更贴近终端用户的视角对系统进行观测。它为每个微服务定义了如下三个关键的度量指标:
- (Request) Rate - 每秒处理的请求数量。
- (Request) Errors - 每秒失败的请求数量。
- (Request) Duration - 请求处理时间的分布。
上述指标能让我们清楚地感知微服务应用的运行状况,并能帮助衡量终端用户的体验问题。
小结
RED 方法和 USE 方法包含了最基本、最有用的监控指标,帮助我们从两方面理解一个系统 - 工作负载的外部视图,以及系统资源对工作负载的反应。这些指标共同构成了系统可观测性的基础。
监控指标分析
根据上一章的理论,这里将监控对象按逻辑划分成资源和应用两大类,下面分别介绍如何采集和计算它们的关键监控指标。
资源指标
由于应用运行在容器中,这里重点关注容器级别的资源状况,包括 CPU、内存等。Kubelet 内置的 cAdvisor 采集了当前主机上容器级别的监控指标,结合 Prometheus 的服务发现功能可以轻松获取集群中所有容器的监控信息。下面以 CPU 和内存为例,介绍如何计算 USE 方法中提到的某些指标。
CPU Utilization
sum(
rate(
container_cpu_usage_seconds_total{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}[1m]
)
) /
sum(
container_spec_cpu_quota{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}/100000
)
CPU Saturation
sum(
container_cpu_load_average_10s{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}
) /
sum(
container_spec_cpu_quota{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}
)
Memory Utilization
sum(
rate(
container_memory_rss{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}[1m]
)
) /
sum(
container_spec_memory_limit_bytes{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}
)
Memory Errors
rate(
container_memory_failures_total{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}[1m]
)
应用指标
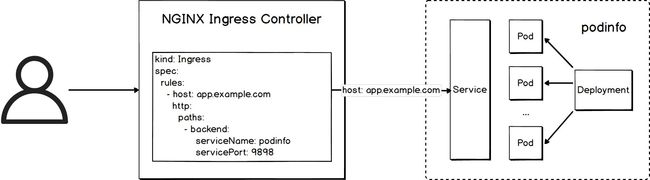
将 NGINX Ingress Controller 的开关controller.metrics.enabled打开,便可以通过 Promtheus 轻松地获取服务请求相关的各类指标。
helm upgrade -i nginx-ingress stable/nginx-ingress \
--namespace ingress-nginx \
--set controller.stats.enabled=true \
--set controller.metrics.enabled=true
下面介绍如何计算 RED 方法中提到的三个关键指标。
Rate
sum(
rate(
nginx_ingress_controller_requests{
namespace="...",
ingress="podinfo"
}[1m]
)
)
Errors
sum(
rate(
nginx_ingress_controller_requests{
namespace="...",
ingress="podinfo",
status=~"5.*"
}[1m]
)
)
Duration
histogram_quantile(0.99,
sum(
rate(
nginx_ingress_controller_request_duration_seconds_bucket{
namespace="...",
ingress="podinfo"
}[1m]
)
) by (le)
)
发布与监控联动
监控指标准备好后,下一步就是如何利用这些指标来影响发布过程,实现更科学和安全的发布。
Flagger 简介
Flagger 是一款开源的,用于自动执行金丝雀发布、蓝绿发布、A/B 测试的工具。它实现了一个控制循环,利用 Istio、Linkerd、App Mesh、NGINX、Gloo 等产品的路由功能,调整发往不同版本间的流量。更重要的是,它能基于 Prometheus 中的监控指标进行金丝雀分析,并根据结果终止或继续金丝雀发布,实现了发布与监控指标的联动。
NGINX 金丝雀发布
本文开头提到的微服务应用 podinfo 使用 NGINX Ingress Controller 作为流量入口,这里将介绍如何通过 Flagger 实现自动金丝雀发布。
配置步骤
Flagger 的安装非常简单,具体步骤可参考文档 Flagger Install on Kubernetes。Flagger 安装好后,需要为 podinfo 的金丝雀发布创建一个自定义资源对象 Canary,如下:
...
kind: Canary
spec:
provider: nginx
# deployment reference
targetRef:
apiVersion: apps/v1
kind: Deployment
name: podinfo
# ingress reference
ingressRef:
apiVersion: extensions/v1beta1
kind: Ingress
name: podinfo
# the maximum time in seconds for the canary deployment
# to make progress before it is rollback (default 600s)
progressDeadlineSeconds: 60
service:
# container port
port: 9898
canaryAnalysis:
# schedule interval (default 60s)
interval: 10s
# max number of failed metric checks before rollback
threshold: 10
# max traffic percentage routed to canary
# percentage (0-100)
maxWeight: 50
# canary increment step
# percentage (0-100)
stepWeight: 5
# NGINX Prometheus checks
metrics:
# Error
- name: request-success-rate
# minimum req success rate (non 5xx responses)
# percentage (0-100)
threshold: 99
interval: 1m
# Duration
- name: "latency"
threshold: 0.5
query: |
histogram_quantile(0.99,
sum(
rate(
http_request_duration_seconds_bucket{
kubernetes_namespace="test",
kubernetes_pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}[1m]
)
) by (le)
)
# CPU Utilization
- name: "cpu-utilization"
threshold: 0.8
query: |
sum(
rate(
container_cpu_usage_seconds_total{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}[1m]
)
) /
sum(
container_spec_cpu_quota{
container_name="podinfo",
pod_name=~"podinfo-[0-9a-zA-Z]+(-[0-9a-zA-Z]+)"
}/100000
)
...
其中,spec.canaryAnalysis配置了金丝雀发布的具体策略,包括检查频率、失败阈值、增量步长等。这里需要重点关注spec.canaryAnalysis.metrics部分,它指定了金丝雀分析引用的监控数据,这里包含了 RED 方法中的 Error、Duration,以及 USE 方法中的 CPU Utilization。
流程分析
完成上述配置后,当我们更改 Deployment 中 PodTemplateSpec 的任意字段便会触发金丝雀发布。
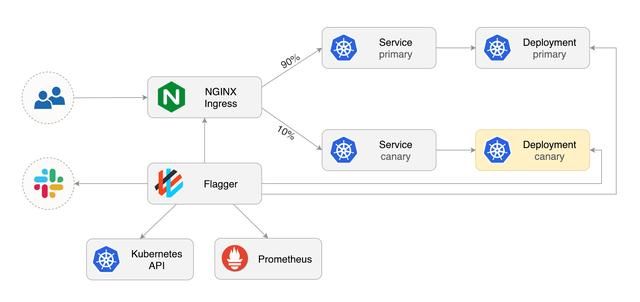
主要流程如下:
- 为新版本创建一系列的金丝雀对象,包括Ingress/podinfo-canary、Service/podinfo-canary、Deployment/podinfo。
- 将Ingress/podinfo-canary的metadata.annotations.nginx.ingress.kubernetes.io/canary设置为 true,将metadata.annotations.nginx.ingress.kubernetes.io/canary-weight的初始值设置为spec.canaryAnalysis.stepWeight,让 NGINX Ingress Controller 将一部分流量转发至金丝雀版本。
- 分析spec.canaryAnalysis.metrics中指定的监控指标。
- 如果各项指标均未达失败阈值,则继续提升metadata.annotations.nginx.ingress.kubernetes.io/canary-weight,让 NGINX Ingress Controller 将更多的流量发往金丝雀版本。
- 如果失败次数达到了指定的阈值spec.canaryAnalysis.threshold,或者金丝雀发布时间超过了约定的时间spec.progressDeadlineSeconds,则进行回滚。
- 当金丝雀版本的流量达到了约定的比例spec.canaryAnalysis.maxWeight,同时各项指标均未达失败阈值,则对原版本进行升级。
- 将Ingress/podinfo-canary的metadata.annotations.nginx.ingress.kubernetes.io/canary设置为 false,同时将metadata.annotations.nginx.ingress.kubernetes.io/canary-weight设置为 0,让 NGINX Ingress Controller 不再将流量发往金丝雀版本 。
- 将金丝雀版本的应用缩容至 0。
总结
本文完整地介绍了 Kubernetes 应用发布与监控指标联动的实现方案。除了监控指标,日志也是反映系统运行状况的重要依据。后面我们将持续关注如何基于日志分析的结果来控制和影响发布过程。
参考资料
- Monitoring and Observability with USE and RED
- NGINX Canary Deployments
阅读原文
本文为云栖社区原创内容,未经允许不得转载。