爬二手商品信息的流程共分两步:
第一步:爬取各商品的url, 保存到数据表itemurls中。此过程采用多进程方式。
第二步:从itemurls表中读出商品url, 爬取商品的详细信息。
源代码
main.py
- 由于各类目下的商品页数相差较大,没有像爬58时使用get_page_urls()时传一个固定的页数去爬取,而是在insert_urls_by_nav()中用一个变量flag作标志位。当前页面如果没有抓到商品信息,则认为爬到了最后一页,终止整个类目的爬取。另一个好处是被网站反爬时也能及时终止爬取,避免不停抓回来无效页面
- spiderurls() 完成流程的第一步
- spideriteminfo() 完成流程的第二步
#!/usr/bin/python
# -*- coding: UTF-8 -*
# multiprocess
# a spider goes to ganji.com
# step1 get item urls and insert them into database
from multiprocessing import Pool
import time
import pymongo
import re
from bs4 import BeautifulSoup
import requests
from urlhandler_ganji import get_nav_urls, get_page_urls, get_item_urls
from mongoconn import mongoset, mongoinsert
table = mongoset('ganji', 'itemurls')
table.create_index([('itemurl', pymongo.DESCENDING)], unique=True)
tinfo = mongoset('ganji', 'iteminfo')
tinfo.create_index([('url', pymongo.DESCENDING)], unique=True)
def listtodict(urls):
datamany = []
for itemurl in urls:
data = {
'itemurl': itemurl
}
datamany.append(data)
return datamany
def insert_urls_by_nav(navurl):
flag = True
pid = 1
filteritem = 'div.layoutlist > dl > dt > a'
filtervalid = 'ul.pageLink'
while flag:
pageurl = navurl+'o{}'.format(pid)
itemurls = get_item_urls(pageurl, filteritem, filtervalid)
if itemurls:
mongoinsert(table, listtodict(itemurls))
pid += 1
#table.insert_many(listtodict(itemurls))
else:
flag = False
time.sleep(8)
### step1
def spiderurls():
pool = Pool()
url = 'http://sh.ganji.com/wu/'
urlbase = 'http://sh.ganji.com'
filternav = 'div.main-pop dt a'
navurls = ['http://sh.ganji.com/shouji/', 'http://sh.ganji.com/shoujihaoma/', 'http://sh.ganji.com/shoujipeijian/', 'http://sh.ganji.com/bijibendiannao/', 'http://sh.ganji.com/taishidiannaozhengji/', 'http://sh.ganji.com/diannaoyingjian/', 'http://sh.ganji.com/wangluoshebei/', 'http://sh.ganji.com/shumaxiangji/', 'http://sh.ganji.com/youxiji/', 'http://sh.ganji.com/xuniwupin/', 'http://sh.ganji.com/jiaju/', 'http://sh.ganji.com/jiadian/', 'http://sh.ganji.com/zixingchemaimai/', 'http://sh.ganji.com/rirongbaihuo/', 'http://sh.ganji.com/yingyouyunfu/', 'http://sh.ganji.com/fushixiaobaxuemao/', 'http://sh.ganji.com/meironghuazhuang/', 'http://sh.ganji.com/yundongqicai/', 'http://sh.ganji.com/yueqi/', 'http://sh.ganji.com/tushu/', 'http://sh.ganji.com/bangongjiaju/', 'http://sh.ganji.com/wujingongju/', 'http://sh.ganji.com/nongyongpin/', 'http://sh.ganji.com/xianzhilipin/', 'http://sh.ganji.com/shoucangpin/', 'http://sh.ganji.com/baojianpin/', 'http://sh.ganji.com/laonianyongpin/', 'http://sh.ganji.com/gou/', 'http://sh.ganji.com/qitaxiaochong/', 'http://sh.ganji.com/xiaofeika/', 'http://sh.ganji.com/menpiao/']
navurls = get_nav_urls(url, urlbase, filternav)
print(navurls)
#insert_urls_by_nav(navurls[0])
pool.map(insert_urls_by_nav, navurls)
def get_soup(url):
proxies = {'http': "207.62.234.53:8118"}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
#source = requests.get(url, proxies=proxies, headers=headers)
source = requests.get(url)
soup = BeautifulSoup(source.text, 'lxml')
return soup
def getemtext(element):
try:
text = element.get_text().strip().replace('\t', '').replace('\n', '').replace(' ','')
except:
text = ''
return text
def getmultitest(element):
text = map(getemtext, element)
info = ''
for t in text:
info = info + ' ' + t
return info
def get_target_info(url):
soup = get_soup(url)
if soup.select('div.error'):
msg = soup.select('div.error p')[0]
pattern = re.compile('删除')
if pattern.search(getemtext(msg)):
curtime = time.localtime()
data = {
'url': url,
'saletime': curtime
}
try:
tinfo.updata_one({'url': url}, {'$set', data})
except:
pass
else:
title = soup.select('h1.title-name')
pubtime = soup.select('i.pr-5')
detailinfo = soup.select('ul.det-infor > li')
category = detailinfo[0].select('a') # soup.select('ul.det-infor > li > span > a')
price = detailinfo[1].select('i') # soup.select('ul.det-infor i.fc-orange')
address = detailinfo[2].select('a')
data = {
"title": getemtext(title[0]), # .get_text(),#.get_text().decode('gbk'),
"pubtime": getemtext(pubtime[0]), #.split()[0], # .strip(u'发布'),#.get_text(),
"price": getemtext(price[0]), # .get_text(),
"category": getmultitest(category), #getemtext(category[0]) + ' ' + getemtext(category[1]),
"address": getmultitest(address),
'url': url,
'saletime': ''
}
try:
tinfo.insert_one(data)
except:
pass
###step2
def spideriteminfo():
turl = mongoset('ganji', 'itemurls')
pattern = re.compile(r'sh.ganji.com')
urls = turl.find()
for url in urls:
if pattern.search(url['itemurl']):
print(url)
get_target_info(url['itemurl'])
time.sleep(1)
if __name__ == '__main__':
###step1
###step2
优化后的urlhandler_ganji.py
- 给get_nav_urls(), get_item_urls()等函数添加了‘filter'参数,调用的时候传入要提取的元素路径, 这样爬不同的网页可以通用
#!usr/bin/env python
#_*_ coding: utf-8 _*_
#
# functions to get item urls
from bs4 import BeautifulSoup
import requests
import time
from mongoconn import mongoset, mongoinsert
def get_soup(url):
proxies = {'http': "207.62.234.53:8118"}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
#source = requests.get(url, proxies=proxies, headers=headers)
source = requests.get(url)
soup = BeautifulSoup(source.text, 'lxml')
return soup
def combineurls(url, page):
pageurls = []
for i in range(1, page+1):
pageurl = url.format(i)
pageurls.append(pageurl)
return pageurls
def get_nav_urls(url, urlbase, filter):
soup = get_soup(url)
navlist = soup.select(filter)
absurls = []
for submnu in navlist:
try:
absurl = urlbase + submnu.get('href')
except TypeError:
pass
except:
pass
if absurl not in absurls:
absurls.append(absurl)
return absurls
def get_page_urls(urlbase, suburl, pagenum=100):
# get urls with pages id
pageurls = []
for i in range(1, pagenum + 1):
pageurl = (urlbase + suburl).format(i)
pageurls.append(pageurl)
return pageurls
def listtodict(urls):
datamany = []
for itemurl in urls:
data = {
'itemurl': itemurl
}
datamany.append(data)
return datamany
def get_item_urls(url, filter, filtervalid=''):
soup = get_soup(url)
print(url)
itemurls = []
if len(soup.select(filtervalid)):
itemlist = soup.select(filter)
if len(itemlist):
for item in itemlist:
try:
itemurl = item.get('href')
except:
pass
itemurls.append(itemurl)
#time.sleep(1)
return itemurls
def getemtext(element):
return element.get_text().strip().replace('\t', '').replace('\n', '').replace(' ','')
def get_urls_by_nav(navurl):
navurls = get_page_urls(navurl)
for pageurl in navurls:
itemurls = get_item_urls(pageurl)
return itemurls
if __name__ == '__main__':
url = 'http://sh.58.com/sale.shtml'
get_nav_urls(url)
运行结果
2016-07-02 16:55:22
...
http://sh.ganji.com/dianyingpiao/o87/
http://sh.ganji.com/qitaxiaochong/o84/
http://sh.ganji.com/dianyingpiao/o88/
http://sh.ganji.com/dianyingpiao/o89/
http://sh.ganji.com/qitaxiaochong/o85/
http://sh.ganji.com/qitaxiaochong/o86/
http://sh.ganji.com/dianyingpiao/o90/
http://sh.ganji.com/qitaxiaochong/o87/
http://sh.ganji.com/qitaxiaochong/o88/
http://sh.ganji.com/qitaxiaochong/o89/
http://sh.ganji.com/qitaxiaochong/o90/
2016-07-02 16:58:18
数据表
[itemurls]

Screen Shot 2016-07-08 at 7.20.28 AM.png
[iteminfo]
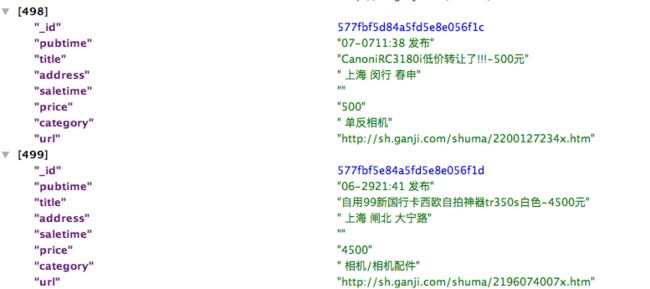
Screen Shot 2016-07-09 at 9.25.04 AM.png
总结
- 爬的过程中不停被反爬,最后把sleep时间设为8秒才顺利爬完
- 爬到5万多商品的url
- 商品信息共爬到18199个, 这是因为筛选掉了那些不是ganji商品的页面
- 接下来需要重复执行这个爬虫, 已便获取到商品的‘saletime’更新到数据表中