这是一个阅读笔记,主要用于记录在阅读经典的目标检测模型论文过程中,得出的总结和思考。并不详细介绍每个模型,主要总结每个模型的优缺点。其中可能存在错误的理解,仅供参考哈。
1. R-CNN(2013-11)
1.1 优点:
成功将CNN分类网络用于目标检测任务,这是第一个比较成功的基于深度网络的two-stage目标检测器。
1.2 缺点:
整条检测流水线由以下环节组成:
- 区域建议(selective search)阶段;
- 特征提取阶段(CNN网络+全连接层);
- 分类和回归阶段(SVM分类器+包围框回归)。
流水线过于复杂。每个环节都需要进行单独优化,会造成整体次优化效果。
graph TD
A[输入图像]-->B[区域建议生成]
B-->C[2000个候选区域]
C-->D[卷积层+全连接层]
D-->F[2000个候选区域特征向量]
F-->G[SVM分类]
F-->H[包围框回归]
G-->I[检测结果]
H-->I[检测结果]

- 每个区域建议框都要经过一次CNN网络,2000个建议框要进行2000次卷积特征提取,计算量巨大。

因为全连接层需要固定长度的特征向量。
1.3 参考资料
- R-CNN论文
- R-CNN演讲PPT
2. SPP-Net(2014-6)
2.1 优点:
引入了空间金字塔池化层(spatial pyramid pooling layer),加速了区域建议特征的提取速度,整张图片只需进行一次CNN前向传播,根据建议框的坐标信息结合原始图像和特征图的步长因子,就可以得到每个区域建议的特征图。
由于每张区域建议的特征图尺寸大小不一,为了得到固定长度的特征向量喂给全连接层,论文使用了空间金字塔池化层来实现。


2.2 缺点:
SPP-Net主要优化了特征提取阶段,整条检测流水线任然十分复杂。
2.3 参考资料
- SPP-Net论文
- SPP-Net演讲PPT
3. Fast R-CNN(2015-4)
3.1 优点:
优点有两个:
- 其一是简化了SPP-Net的空间金字塔池化层为ROI池化层,降低计算量;
- 其二是使用了Softmax分类层取代了SVM分类层,使得特征提取阶段,分类和回归阶段融合成了单个检测网络。该检测网络可以进行端到端训练。
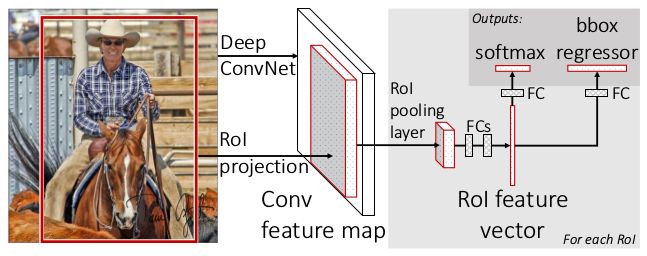
3.2 缺点:
这样,Fast R-CNN就由区域建议阶段+检测网络组成,整个检测网络结构相比于之前的R-CNN和SPP-Net来说,已经有很大进步了。此时区域建议算法成了一个瓶颈,因为区域建议算法不仅速度慢(2s/image),而且无法和检测网络进行联合优化。
3.3 参考资料
- Fast R-CNN论文
- Fast R-CNN演讲PPT
4. Faster R-CNN
4.1 优点:
提出了RPN网络,根据输入图像的卷积特征图,采用了anchor机制(特征图每个像素点位置上,密密麻麻的,不同尺度和横纵比的默认候选框),以及一个小的二分类及回归层来生成区域建议。由于RPN的速度飞快,解决了Fast R-CNN的速度瓶颈。此外,RPN网络和detection network可以进行端到端联合优化,使得Faster R-CNN的整体检测性能相比Fast R-CNN更上了个台阶。

4.2 缺点:
Faster R-CNN存在的不足主要有3点:
其一,Faster R-CNN只使用了VGG-16的最后一张卷积特征图conv5_3来生成区域建议,该特征图已经比较深/粗糙了,丢失了较多的原始图像细节(如小目标和精确的位置信息),导致了Faster R-CNN对于小目标的检测不佳。另外,由于使用了比较粗糙的特征图,Faster R-CNN的定位精度不太好。这样,当计算Precision时,在IOU阈值要求较高的检测数据集如COCO上,Faster R-CNN的Precision不高,进而影响AP值。
其二,Faster R-CNN由两个阶段构成:RPN建议生成阶段+Fast R-CNN检测阶段,进行了两次分类+回归。虽然可以进行端到端优化,但是整个检测网络的复杂度仍然很高。当然,这是所有两阶段检测网络的通病,这方面的解决方案参考YOLO系列和SSD系列等单阶段检测器。
-
其三,(这是我自己认为的缺点,网上的博客中好像都没有提到,目前还没有通过实验验证)Faster R-CNN使用了conv5_3特征图来生成3个尺度(128x128, 256x256, 512x512)和3个横纵比(1:1, 1:2, 2:1)一共9种anchor,这9种anchor的大小、形状都不相同。即RPN需要使用一组固定感受野大小(228 for VGG-16)的特征向量(512d for VGG-16,特征图中一个位置的特征向量对应于原始图像中相应位置一块固定大小的区域)来生成大大小小的区域建议框。那么就会出现三种情况:
(1)区域建议尺度和感受野相差不大

(2)区域建议尺度比感受野小得多

(3)区域建议尺度比感受野大得多

以上三种情况中:
第一种情况是应该算最理想的,根据该感受野来推断该区域内的区域建议是合理的,因为网络看得见目标区域(即目标被感受野区域覆盖);
第二种情况不太理想,虽然网络看得见整个目标区域,但是目标特别小,前面说了,RPN利用了conv5_3特征图,该特征图十分粗糙,已经丢失掉的原始图像中精细的位置信息,甚至有可能连整块目标信息都被卷没了;
第三种情况也不妙,因为网络只看得见飞机图中感受野区域内的信息,即网络需要仅根据飞机机身的一部分来猜测飞机的整体轮廓,针对这一点,Faster R-CNN论文中有这么一段解释:

大意是说,RPN设置的某些anchor尺寸大于了特征图的潜在感受野,但是这种情况也不是不可能的。如果只让一个人看着飞机图中的感受野区域,应该也能大致猜出飞机的大概轮廓(人是何等智能的动物啊。。。)。作者认为网络也能通过训练数据学习到这一点,即根据目标的一部分猜测整体轮廓的能力。
实际上,上面考虑的仅仅是特征图的理论感受野,网络的实际感受野更小,两者是什么关系目前也还是个谜,唯一可参考的论文有这一篇:Understanding the Effective Receptive Field in Deep Convolutional Neural Networks。
当然,某些模型认为建议区域尺寸应该和特征图感受野大小一一对应,即使用相对较浅的特征图来处理小目标,使用较深层特征图来处理大目标,这是SSD的解决方案。但是SSD忽略了一点:浅层特征图虽然保留了相对精细的内容信息,但其抽象程度不如深层特征图(可能无法很好地表示目标的语义信息);深层特征图则存在相反的问题。因此,将不同层级的特征图进行融合,使得融合后的特征图既具有深层特征图高级的语义信息,同时又保留了浅层特征图的图像细节信息。这些思想在后面的一系列论文中都有体现,慢慢看吧。
4.3 Faster R-CNN参考资料
- Faster R-CNN论文
- Faster R-CNN演讲PPT
5. YOLO(2015-6)
5.1 优点
- 单阶段目标检测器的开山之作,将整个目标检测看做回归过程,直接使用两个fc层直接预测目标类别和坐标信息。
- 基于GoogleNet,提出了一个定制的基础网络,性能好,同时计算开销小。
- YOLO的速度快的吓人,R-CNN系列经过几代人的努力(R-CNN-->SPP-Net-->Fast R-CNN-->Faster R-CNN),最新的Faster R-CNN速度终于能达到5FPS了,结果YOLO一下子将速度拉到45FPS以上。
5.2 缺点
- 模型准确率有待提高,和Fast R-CNN、Faster R-CNN相比还有差距。
- 模型采用了直接回归的方式预测包围框坐标,导致定位误差很大
YOLO模型的网络结构非常简单,没什么好讲的。具体的模型细节以及训练方式参考下面提供的论文、演讲PPT以及演讲视频。
5.3 参考资料
- YOLO论文
- YOLO演讲PPT
- YOLO_CVPR2016演讲视频
- 另一个介绍YOLO的PPT
- YOLO-tensorflow源代码
6. SSD(2015-12)
理解了Faster R-CNN中的RPN以及anchor的理念,那么理解SSD就相当容易了。
6.1 优点
- SSD相当于一个可用于多分类的RPN网络,但是SSD使用了多个层级的特征图同时进行预测:

SSD总共使用了6个层级的特征图进行预测,基本出发点是:浅层特征图保留了图像更多的细节信息,更适合用于预测小目标;深层特征图拥有更大的感受野,适合用于检测大目标。因此SSD使用了6个不同层级的特征图进行预测,试图解决目标的多尺度问题。
- 从模型性能来看,SSD达到了当时最强的Faster R-CNN的水准;但是速度却完爆Faster R-CNN,贴一张在PASCAL VOC2007测试集上的性能对比图:
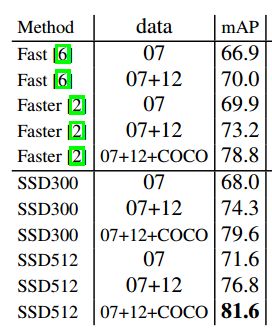
再贴一张速度对比图:

就准确率和速度的trade-off来看,SSD刚出来时是真的厉害!
6.2 缺点
- SSD虽然使用了浅层的特征图,试图改善对小目标的检测效果,但是SSD实际上对小目标的检测效果也不太好,原因是浅层特征图虽然保留了较多的图像细节,但是其语义信息较弱,导致最后的识别效果不好,这个问题后面会被FPN解决。
- 个人经验,当识别类别数变多时,SSD的效果没有Faster R-CNN好,因为SSD的分类网络太简单了。
6.3 参考资料
- SSD论文
- SSD演讲PPT
- 一份不错的SSD-tensorflow开源代码
- 一份不错的SSD-pytorch开源代码
7. HyperNet(2016-4)
7.1 优点:
HyperNet貌似是第一个尝试将多层级特征进行融合的两阶段目标检测器,前面说了Faster R-CNN仅使用了十分粗糙的conv5_3层用于生成区域建议,导致对小目标的检测效果不好,同时定位精度不够好。HyperNet将不同层级的特征图进行融合,使得融合后的特征图既具有深层特征图高级的语义信息,同时又保留了浅层特征图的图像细节信息,这是这篇论文最大的亮点。
HyperNe整体网络结构如下图所示:
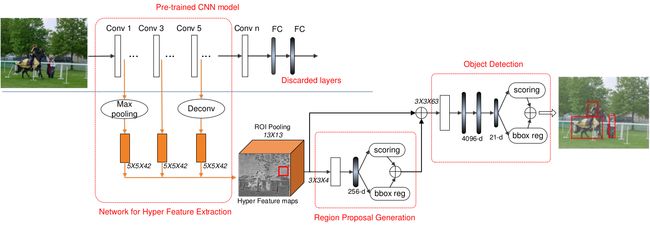
如果理解了Faster R-CNN的网络结构,HyperNet的网络结构应该很容易理解。HyperNet使用了conv3的图像分辨率进行预测,同时融合了conv1和conv5的特征图信息,融合之后的特征图称为Hyper Feature Maps。
至于区域建议生成部分,HyperNet尝试了两种结构:

这一部分中,HyperNet和RPN还是有一点区别的,主要在于ROI池化层的顺序(该部分的anchor是怎么生成的,论文中貌似没有详细说明),不过个人感觉是换汤不换药,既然RPN都开了使用深层卷积特征图和anchor来生成区域建议的先河,后面的修改就方便了。。。
7.2 缺点:
HyperNet的缺点说不上是哪儿,HyperNet的mAP值在PASCAL VOC2007测试集上是76.3%,在Faster R-CNN的基础上增加了3.1%。

但是,HyperNet的检测速度很慢,HyperNet-SP和Faster R-CNN的检测速度都是5fps,但是准确率差不多。

所以,虽然HyperNet融合多个层级的特征用于生成区域建议的思想貌似更高级,但是其效果(mAP)并没有体现的很明显。
7.3 参考资料
- HyperNet论文
8. R-FCN(2016-5)
8.1 模型动机
R-FCN提出的初衷是为了提高ResNet论文中最后附带提出的检测架构,即Faster R-CNN+ResNet-101的整体检测速度。下图是使用了ResNet-101作为Faster R-CNN的基础网络后,在PASCAL VOC2007测试集上带来的mAP提升,最高竟然达到了惊人的85.6%!

当然,85.6%的mAP值还包含了一系列的trick如box refinement,context和multi-scale testing。这些trick这里不管,我也没详细看。这里想说明的是:通过使用更好的基础网络如ResNet-101取代VGG-16,Faster R-CNN的检测性能已经相当牛逼了。但付出的代价是检测速度极剧下降:
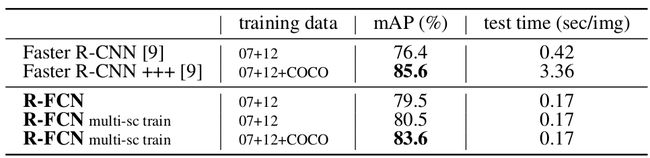
上图是R-FCN和Faster R-CNN(ResNet-101)在PASCAL VOC2007测试集上的检测准确率和速度的对比图。
论文摘要中提到,R-FCN在测试集上的检测速度比Faster R-CNN快了2.5-20倍,达到了170ms/image,大约6fps。刚看到时会感到疑惑:Faster R-CNN论文中不是提到其检测速度最慢也有5fps吗?R-FCN才6fps,是怎么比Faster R-CNN快2.5-20倍的?解释一下,这里R-FCN是和更准的Faster R-CNN(ResNet-101)比速度,而不是原始的Faster R-CNN(VGG-16)。因为原始的Faster R-CNN(VGG-16)的mAP值才73.2%,而R-FCN达到了83.6%,两者没什么好比的。
下面从网络结构上分析Faster R-CNN模型慢的主要原因:

其中,ROI Pooling层是一个分界点。ROI Pooling层之前的特征提取网络,以及RPN都是在全图上共享卷积计算的,不管anchor的数量有多少,这部分网络的计算时间基本固定。但是ROI Pooling层之后的检测网络则不一样了,每一个proposal feature map是一个个单独送到检测网络中进行计算的,如果有300个proposal,那就要进行300次分类回归计算。原始的Faster R-CNN(VGG-16)最后是两个FC层,计算量相对较小;准确率更高的Faster R-CNN(ResNet-101)最后貌似使用了10个卷积层进行分类和回归,因此计算量大增。这也是上面的表格中,Faster R-CNN(ResNet-101)为什么这么慢的原因(还有使用了多尺度预测等)。
好了,Faster R-CNN模型慢的主要原因是因为ROI Pooling层之后的检测网络不在全图上共享计算。那R-FCN的核心动力就是要消除这一部分不共享计算的检测网络。使得整个特征提取网络+RPN+检测网络的所有环节都在全图上共享计算,从而达到提速的目的。下面的表格表明了决心!

其具体做法是提出了位置敏感得分映射position-sensitive score map和position-sensitive ROI Pooling。
8.2 论文中不容易理解的几个地方
-
图像分类中的平移不变性和目标检测中的平移可变性
图像分类中的平移不变性相对好理解一些,想想ImageNet分类数据集中,一张分类图像中一般仅包含一个目标,而且该目标又不是铺满整张图像的,如果将该目标在图像中平移一下、或者左右/上下翻转一下,分类网络还是会自信满满地将图像给正确分类出来。这是我理解的分类网络的平移不变性特征。
但是目标检测任务就不一样了,除了要正确找出图像中有哪些目标,还要准确定位每个目标的包围框,如果本来一个目标被某个候选框很好地框住,但这个目标在候选框中进行了一定的平移,两种情况下得到的检测效果就完全不同了,显然平移之后,检测效果就变差了。换句话说,目标检测网络对图像中每个目标的位置(x, y, w, h)信息是很在意/敏感的,一个优秀的目标检测网络应该具有对图像中目标的位置信息敏感的能力。以前面的例子为例,如果目标进行了平移,则目标检测网络应该给平移后的候选框打个差评。
-
position-sensitive score map和position-sensitive ROI Pooling
来看R-FCN的网络结构图:

前面说了,R-FCN的核心动力就是要消除ROI Pooling层之后的不共享计算的检测网络。使得整个特征提取网络+RPN+检测网络的所有环节都在全图上共享计算,为了达到这个目的,R-FCN将Faster R-CNN(ResNet-101)中用于检测网络部分的卷积层全部放到了ROI Pooling层之前。
上图中,feature maps部分是ResNet-101的conv5之前的卷积层,即3+4+23个瓶颈块,feature maps输出的特征图相对于输入图像的下采样步长是16,这个所有的Faster R-CNN版本都一样。而RPN部分的分支结构也和Faster R-CNN一致。
区别就在于图中五颜六色那一块特征图是啥?就是position-sensitive score map。feature maps一方面通过RPN生成proposal,另一方面继续进行ResNet-101的conv5部分的卷积层操作,不过conv5部分所有卷积测步长都是1,中间再接一个1x1卷积将conv5部分的输出通道数由2048d降到1024d。最后通过一个卷积层得到position-sensitive score map。position-sensitive score map的分辨率和feature maps保持一致。
position-sensitive score map的通道数是KxKx(C+1),其中C表示目标的类别数,PASCAL VOC是20类,COCO是80类,+1表示背景。而KxK则对应了position-sensitive ROI Pooling中的KxK个方块。
position-sensitive ROI Pooling的池化方式有点特别,如下图所示:
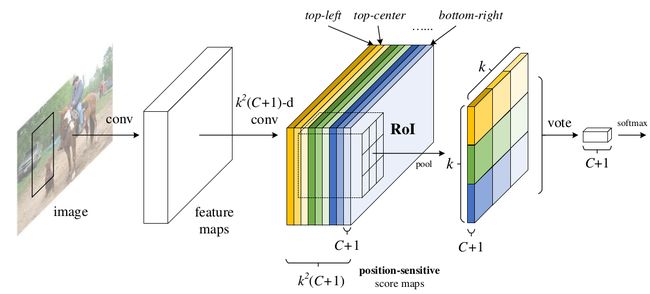
假设图中的ROI区域表示一个候选框,position-sensitive ROI Pooling层将该ROI区域划分成KxK个网格区域,然后对这KxK个区域分别进行平均池化,其中。。。
算了,R-FCN描述起来太麻烦了。。。直接参考下面这两篇博文吧:
- 详解R-FCN;
- 解答关于R-FCN的所有疑惑(原创)。
9. PVANet(2016-11)
9.1 概述
在PVANet出来之前,目标检测领域已经分为了两阶段(two-stage)检测器和单阶段(one-stage)检测器两大阵营了:
- 两阶段检测器以Faster R-CNN、R-FCN等为代表,典型结构是先使用RPN生成候选框,再对候选框进行分类+回归。特点是准确率高但速度很低,一般低于10FPS。
- 单阶段检测器以YOLO、SSD为代表,YOLO采用回归的思路,直接使用fc层输出目标类别和包围框;SSD相当于一个多分类RPN,但是使用了多层级的特征进行预测。特点是速度很快,都超过了20FPS以上,但是准确率比两阶段检测器如Faster R-CNN(ResNet-101)和R-FCN稍微差一些。
- 个人感觉在目标类别增多的情况下,单阶段检测器的表现会进一步被两阶段检测器甩开。因为分类层太简单了。
PVANet的出现则改善了两阶段检测器速度慢的毛病。要说明的是,PVANet的总体检测思路完全是继承Faster R-CNN的,即特征提取网络+RPN+检测网络。但PVANet对每一部分都进行了优化/提速,结果PVANet在保持两阶段检测器高准确率的前提下,其检测速度直接超过了20FPS,达到了实时的检测速度。直接贴上PVANet在PASCAL VOC2007测试集上的表现:

再贴上到2016-11为止,即PVANet出来时,几个主流的目标检测网络在PASCAL VOC2012测试集上的表现:

对比结果很明显,PVANet、Faster R-CNN(ResNet-101)和R-FCN在PASCAL VOC2007测试集上的准确率相差不大,但是PVANet的速度完爆Faster R-CNN(ResNet-101)和R-FCN。速度直接和当时最强的单阶段检测器SSD512相媲美,但准确率更胜一筹。
前面说了,两阶段检测器典型地由三部分组成:特征提取网络+RPN+检测网络,下面分别介绍PVANet在这3部分上的改进。
9.2 特征提取网络--PVANet
Faster R-CNN最初提出时,特征提取网络使用了ZF和VGG-16,但后面更强大的ResNet出来之后,使用了ResNet-101作为特征提取网络(在ResNet论文中有提到)。类似地,后面出现的R-FCN同样使用ResNet-101。
而这篇论文中提出了一个轻量化的特征提取网络,即PVANet。对,在论文中PVANet主要指的是目标检测网络中的特征提取网络。PVANet新颖的网络结构是这篇论文最大的亮点。PVANet主要使用了以下高科技:
- modified C.ReLU层
要了解modified C.ReLU层,得先了解C.ReLU层。可参考这篇博文:CReLU激活函数。
简单地说,C.ReLU层是一种特别的ReLU层。原论文的作者在做实验时发现,CNN网络的前几层中,网络倾向于同时捕获正负相位的信息,但标准的ReLU会抹掉其中的负响应。 这造成负响应相关信息的丢失。为了捕捉完整的信息,C.ReLU层是这样做的:
即将ReLU层的输入特征进行取反,然后和原始特征在通道维度进行concate。再进行ReLU操作,也就是说,C.ReLU层输出的特征通道数量是标准的ReLU层的2倍。但这样做捕捉了更多的特征信息。使得CNN分类网络的准确率会有一点提升。但是C.ReLU层只适用于浅层部分,层数加深后,该现象逐渐消失了。
可能说的不太对,想详细了解还是看C.ReLU层的论文吧。
原始的C.ReLU层之前,两个相反的输入特征是共享bias的,而modified C.ReLU层使两个相反的输入特征不共享bias。这就是modified C.ReLU层。通过在CIFAR-10上的实验,使用相同的CNN网络,本文提出的modified C.ReLU层达到的准确率比C.ReLU层稍微好一点点。
- 残差网络中的shortcut connection
如下图所示:
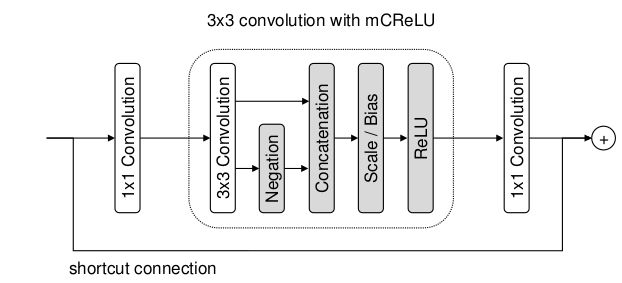
我们知道,ResNet网络中提出的shortcut connection,也就是瓶颈块可以大大改善深度网络的训练,所以PVANet中的绝大部分层都使用了shortcut connection,这算是借鉴了ResNet的精华。上图中,中间部分就是modified C.ReLU层。
- Inception模块
PVANet网络的前几层使用了modified C.ReLU层,后面几层则使用了Inception模块。为什么使用Inception模块而不是单纯地继续使用ResNet的瓶颈块结构将网络不断加深呢?下图是加了shortcut connection的Inception模块:
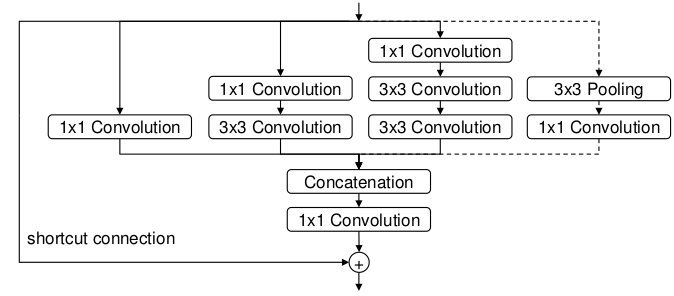
第一,Inception模块的计算成本是相当小的。这和PVANet致力于降低网络的计算成本目标一致。
第二,对于目标检测任务来说,使用Inception模块作为特征提取层其实是有天然优势的。很多目标检测论文不是都提到吗,图像中存在大大小小的目标,检测大目标需要感受野较大的深层特征,检测小目标则需要感受野较小的浅层特征。看一下上图中Inception模块的结构:从左到右,每一个分支扩大的感受野是不同且逐渐增大的。将其进行concate之后,经过很多层的Inception模块,深层的输出特征图中,有一些通道的特征图保留了相对较小的感受野,这些通道的特征使用用于检测小目标。而另一些通道的特征图感受野很大,适合用于检测大目标,随着网络层数的加深,那些用于检测小目标的,较小的感受野的特征图也拥有了较强的语义信息。简直完美!
- BN是必不可少的
BN层的加入进一步加快网络的训练。
- 多层级特征融合
自从2016年开始,多层级特征融合这一思想就开始被目标检测网络广泛采用,前面提到的HyperNet就是一个例子。多层级特征融合的思想最早应该是在2014-11,用于语义分割的FCN论文中被提出的吧。所以,虽然使用了Inception模块能在一定程度上解决目标尺度问题,PVANet还是进一步使用了多层级特征融合的策略。
好了,下面贴上PVANet特征提取网络的层参数:
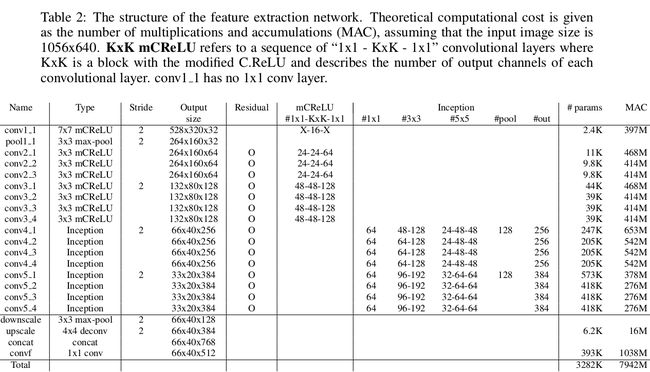
整个PVANet特征提取网络首先使用了一个7x7的大卷积层,2倍步长。然后使用一个3x3,步长为2的池化层。
接下来就是使用有shortcut connection+modified C.ReLU的卷积层了。即conv2_x和conv3_x部分。
再接下来是使用shortcut connection+Inception模块的卷积层了,即conv4_x和conv5_x部分。
算一算PVANet特征提取网络有多少个卷积层:7个shortcut connection+modified C.ReLU的卷积层;8个shortcut connection+Inception模块的卷积层。加上第1层7x7大卷积层。
1+7x3+8x4=54
一共有54层卷积!虽然没有ResNet-101那么深,但是PVANet同时汲取了ResNet和Inception网络的核心优点。加上BN层和modified C.ReLU的使用,PVANet在ImageNet分类数据集上的表现并不差:

甚至比GoogleNet和VGG-16还好一些。重点是PVANet的计算成本相当的低(注意到PVANet在网络深层的特征图通道一直保持的较小)!
下面来看一下由PVANet构成的目标检测网络的整体结构:

注意和上面PVANet的层参数表格对比,就能很清晰地理解PVANet了。由于PVANet最后一个Inception模块输出的特征图是输入图像的1/32。PVANet采用了多层特征融合的思路,将conv5_4的特征图进行2倍上采样,将分辨率是输入图像1/8的conv3_4特征图进行2倍采样,再和分辨率是输入图像1/16的conv4_4特征图进行concate,在进行一次1x1x512的卷积,得到了分辨率是输入图像1/16的特征图。这和原始的Faster R-CNN使用VGG-16的conv5_3输出的特征图在大小和通道数上面是一致的。
9.3 RPN
这篇论文中的RPN和原始的Faster R-CNN论文中的RPN有些不同:
- 仅使用了512个通道的特征图中的前128个通道来送入RPN网络。
因为作者发现,仅仅使用特征图中的前128个通道用于生成区域建议,就能得到相当的准确率了。而且RPN的第一个卷积层由3X3X512变成了3X3X384。这样做进一步降低了RPN部分的计算成本。
- 使用了6个scale和7个aspect ratio
感谢Inception模块和多层级特征融合,送入RPN的特征图对小目标的检测能力应该明显由于原始的Faster R-CNN,因此作者大胆地使用了多达6个尺度和7个横纵比的anchor,即特征图每个点会预测42个anchor:
6个尺度:32, 48, 80, 144, 256, 512
7个横纵比:0.333, 0.5, 0.667, 1.0, 1.5, 2.0, 3.0
作为对比,原始的Faster R-CNN仅使用了3个尺度:(128, 256, 512),以及3个横纵比:(0.5, 1.0, 2.0)。
使用更丰富的anchor不仅能提高准确率,同时增加的计算成本相当小。
9.4 检测网络
检测网络使用了6X6的ROI池化层。而且池化时使用了特征图全部的512个通道的信息。仅使用200个proposal。应该是使用了更丰富的anchor,使得RPN生成的建议框质量相当好,仅使用200个proposal就能达到98.8%的召回率。作为对比,使用300个proposal能达到99.2%的召回率。仅相差0.4%。
但别忘了,经典Faster R-CNN架构中检测网络的计算成本与RPN的proposal数量成正比的。为了提速,作者仅适用了200个proposal。再贴上PVANet在PASCAL VOC2007测试集上的表现:

表中可以看出,仅仅使用50个proposal,PVANet都能达到83.2%的mAP值,此时的速度达到了惊人了37.3FPS!
全连接层的布置和原始Faster R-CNN一致,即4096X4096x(21+21X4)。但是,可以进一步将全连接层进行压缩(文中展示了truncated SVD,即上表中的PVANet+compressed),在基本不损失准确率的情况下大幅度提高检测速度。
9.5 总结
PVANet通过使用一系列技巧,使得Faster R-CNN式的两阶段检测器的检测速度能够媲美单阶段检测器,同时保留的两阶段检测器准确率方面的优势。
- 特征提取网络方面。结合了ResNet的shortcut connection、Inception模块、modified C.ReLU层、BN层、多层级特征融合等一系列高级模块和技巧,共同构成了一个超级轻量化但性能优良的PVANet特征提取网络。
- RPN方面。仅使用了特征提取网络输出的特征图的前128个通道用于生成区域建议。进一步降低了RPN的计算成本。使用了更加丰富的anchor,有效提高了网络的准确率。
- 检测网络方面。由于RPN生成的区域建议质量很高,PVANet仅使用了200个proposal用于目标检测。进一步降低检测网络的计算成本。
但是,作者在论文中并没有给出PVANet在难度更大的COCO数据集上的准确率。要是在COCO上面也能得到很高的mAP的话,那PVANet就真的很牛逼了。不过作者在github上开源了代码:pva-faster-rcnn。
代码是在Python/caffe版的Faster R-CNN源代码上面改的。
9.6 参考资料
- PVANet论文
10. YOLO_v2(2016-12)
10.1 YOLO_v2在YOLO基础上的改进
YOLO_v2在YOLO的基础上进行改进,首先还是先贴上YOLO的网络结构图:

下面的表格说明了从YOLO升级到YOLO_v2,作者做了哪些改进:
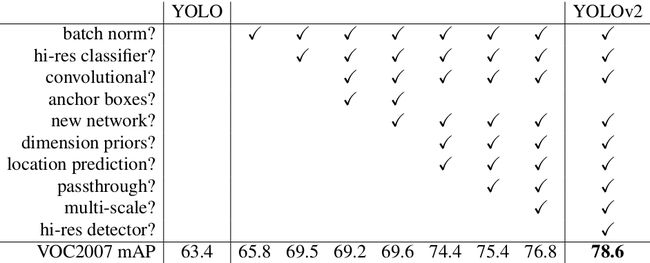
下面按照从上到下的顺序依次总结每一个改进措施:
- 在所有卷积层中加入BN层(batch norm?)
BN层不用多说了,不仅能显著加快网络训练的收敛速度,还是防止过拟合,一般使用BN就不用dropout了。使用BN还能使网络收敛到一个更好的局部最优。
从表中可看出,仅仅加了BN之后,YOLO的mAP值提高了2.4个百分点。
- 在高分辨率的图像上进行ImageNet预训练(hi-res classifier?)
目标检测网络中的特征提取网络通常需要在ImageNet分类数据集上进行预训练。YOLO特征提取网络首先在ImageNet上预训练,此时使用的输入图像分辨率是224x224的。但在目标检测数据集上面fine-tune时,网络的输入图像分辨率增大到了448x448。作者认为,从224到448的调整会导致网络卷积核需要额外的适应新的图像分辨率,有可能会增大fine-tune的难度。干嘛不在ImageNet上预训练时就直接上输入图像分辨率设置成448X448呢?
这样做的效果十分明显,在BN基础上,YOLO的mAP值进一步上涨3.7个百分点,mAP值达到了69.5%。
- 使用anchor机制,并将预测层由fc层改为卷积层(convolutional?+new network?+ dimension priors?)
作者参考了Faster R-CNN中RPN使用的anchor机制,由于anchor机制在做位置回归时是预测一个相对偏移量offset,属于间接回归。而YOLO使用了全连接层直接预测目标包围框的h/w,属于直接回归。由于目标尺度变化问题,作者意识到,采用直接回归的训练难度应该会比采用anchor的间接回归大。因此作者尝试了anchor机制。
既然使用了anchor,那预测层由全连接层改为了卷积层,形式应该和SSD类似。
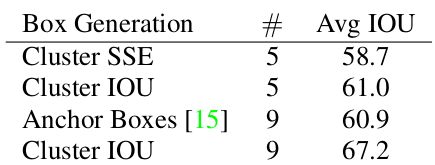
但是,Faster R-CNN和SSD中的anchor尺度和横纵比是人工设置的,是一个超参数。YOLO通过对目标检测训练集中的anchor进行K-means聚类,根据数据集的目标包围框的形状尺度统计信息来设计更加合理的anchor:

如上图所示,随着K值增大,anchor与ground truth包围框的IOU值越来越优。为了权衡模型复杂度,作者选择K=5这个点的聚类结果,右图是聚类出来的anchor形状,可以看到,数据集中的目标包围框更多的是高瘦型的,矮胖型包围框相对较少。
而且,K=5时,得到的anchor质量和Faster R-CNN使用9个anchor的效果差不多:
通过采用anchor机制,YOLO的mAP值反而稍微下降了一点点,从69.5%降到69.2。但是,召回率从81%升到了88%。因此作者认为anchor是有效的,且YOLO的mAP肯定有提升的空间。
作者将网络的输入分辨率由448改为了416,而且抽掉中间的一个最大池化层。这样,整个特征提取网络的总步长变成32,输出的特征图大小为13x13(奇数网格数量)。这样设计的一个目的是,特征图的中心正好对应原始输入图像的中心,因为一些很大的目标的几何中心一般都落在输入图像中心附件,生成13x13的奇数尺寸特征图的话,特征图中心网格处的anchor可以更好地捕捉大目标。
- 修改位置回归公式+使用两个特征图进行预测(location prediction?+passthrough?)
作者在使用K-means得到5种anchor之后,在坐标回归,即预测(x, y, w, h)时采用了RPN的回归公式,但是发现这种回归方式在网络训练早期很不稳定,因为(x, y)的偏移量的假设范围太大,可布满整张图片。因此,作者使用原始YOLO中(x, y)的回归方式。而(w, h)的偏移方式采用了RPN中的公式。这样,网络训练过程改善很多。
另外,作者注意到SSD使用了多层级的特征图进行预测,确实,由于分辨率更高的特征图保留了更多的图像细节,在预测小目标上面效果更好些。因此作者同时使用了13x13预测层的上一个层级,即26x26x512大小的特征图进行预测。而且将26x26x512改成了13x13x2048,这样就可以和最后一层的13x13x512的特征图在通道上进行concate,看上去就像是使用一个尺寸的特征图进行预测一样。
包围框坐标预测公式的修改,加上26x26x512的预测层的加入,使得YOLO的mAP值在之前的基础上提升了5%+1%左右。达到了75.4%。
- 多尺度训练(multi-scale?+hi-res detector?)
经过以上改进,YOLO去掉了fc层,整个检测网络由卷积层+池化层组成,特征提取网络的最大步长是32。
前面的改进都将输入图像的分辨率固定在416x416。但是YOLO的网络结构原则上是可以处理任意分辨率的输入图像的。作者注意到了这一点。于是YOLO在训练时,总共尝试了以下这些图像分辨率:
288x288, 320x320, 352x352, ... , 608x608
考虑到特征提取网络32的总步长,YOLO在训练时,每隔32个像素设置一个图像分辨率,最低288,最高608。
YOLO每训练10个batch,就从上面的分辨率中随机选择一个新的分辨率继续进行训练。注意,是在相同的网络结构中进行不同输入分辨率图像的训练哈!而不是像SSD那样,300和512的分辨率使用了不同的网络。
这样训练完成后,YOLO检测网络拥有了对各种分辨率图像进行检测适应能力。测试时如何选择输入图像分辨率就看用户对速度和准确率的需求了,多种配置,任君选择!
多尺度训练后的YOLO在PASCAL VOC2007测试集上的效果如下表:

可以看到,小分辨率图像速度快,准确率相对差些。大分辨率图像则相反。当使用544X544的大分辨率时,YOLO能以40FPS的速度达到78.6%的mAP值。
上面这一系列对YOLO的改进方案加在一起,就是本文的YOLO_v2网络啦。
YOLO_v2在多尺度训练和多尺度测试这点上的改进很有创意!
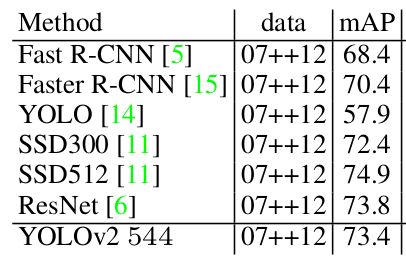
另外贴上YOLO_v2在PASCAL VOC2012测试集上的mAP值:
还有YOLO_v2在COCO2015测试集上的准确率:

我们知道,原始的YOLO虽然速度超快,但是准确率比SSD以及Faster R-CNN系列竞争对手还是要差一截的。
但从以上表格可以看出,YOLO进化成YOLO_v2之后,在保持速度优势的前提下,准确率快要赶上SSD和Faster R-CNN系列了(严格来说YOLO_v2的准确率还是要弱一点点。。。而且都没有拿R-FCN以及PVANET出来作对比)。
10.2 一个新的特征提取网络:Darknet-19
别的目标检测模型基本都是直接使用成名的图像分类网络如VGG-Net、Inception系列以及ResNer-101等作为特征提取网络。但是YOLO作者貌似对这些基础网络都不太满意。
在原始的YOLO模型中,作者参考了GoogleNet,提出了一个定制的基础网络,这个网络没有单独的代号。
这次的YOLO_v2中,作者参考VGG-16,又提出了一个基础网络,这次就有响亮的代号了——Darknet-19。
19表示该网络有19个卷积层,下面是Darknet-19的网络层参数:

其实仔细一看,Darknet-19和VGG-16十分相似,不过在每个3x3卷积层中间插入了1x1卷积,这里的1x1卷积不仅能增加网络深度,同时还能通过减小特征通道的数量,大大地降低计算成本。
对比一下:
- YOLO定制网络的计算成本是8.52 billion浮点运算,在ImageNet上的top-5准确率是88.0%;
- VGG-16的计算成本是30.69 billion浮点运算,在ImageNet上的top-5准确率是90.0%;
- Darknet-19的计算成本是5.58 billion浮点运算,在ImageNet上的top-5准确率是93.3%;
结论:Darknet-19是一个更加优秀的基础网络,同时计算成本是YOLO定制网络的65%,是VGG-16的18%。
作者用Darknet-19替换掉了原始的YOLO定制网络,作为新一代YOLO_v2的基础网络。
但是作者在论文中没有给出使用Darknet-19的YOLO_v2在PASCAL VOC和COCO数据集上的表现。
10.3 总结
论文还有一部分关于YOLO-9000的内容,貌似是采用特殊的训练方式,将YOLO_v2在COCO目标检测数据集和ImageNet图像分类数据集中一起训练,使模型能同时检测超过9000类目标,这里不关注。
总的来说,这篇论文有以下贡献:
- 在原始的YOLO模型基础上,提出了一系列的改进tricks,在保证YOLO速度优势的同时,使得YOLO进化成了YOLO_v2,准确率基本快赶上SSD和Faster R-CNN系列了。
- YOLO_v2通过新颖的多尺度训练和多尺度预测方案,使得训练好的YOLO_v2模型能检测不同分辨率的输入图像,速度和模型准确率之间的trade-off由使用者自己决定。
- 提出了一个性能更好、同时计算成本更小的基础网络——Darknet-19。
10.4 参考资料
- YOLO论文
- YOLO演讲PPT
- YOLO_CVPR2016演讲视频
- 另一个介绍YOLO的PPT
- YOLO_v2论文