HashMap工作原理概述
数组和链表作为两个基本数据结构各有其优劣。数组作为顺序存储结构,优点是查找方便时间复杂度为O(1),但是数组在进行频繁插入和删除操作时需要移动大量元素.而链表虽然在插入和删除操作相比于数组性能好得多,但是在进行查找操作时需要遍历元素。因此为了取长补短,java提出HashMap这一数据结构。HashMap的数据结构如下图所示。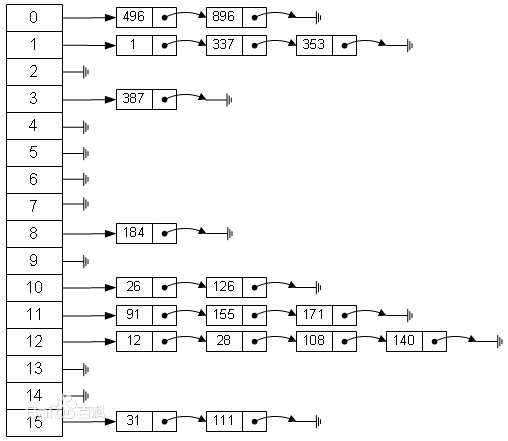
HashMap其实也是一个数组,只不过每个元素存储的是每个链表的头结点。每个链表中每个元素是一个键值对Entry
Hash冲突
哈希查找作为一种查找方法,其原理是通过建立key和存储位置之间的映射y = f(key),使得每个key对应一个存储位置。在元素查找时,通过f(key)来查找。但是由于存在不同的key可能得到的存储位置相同,这就是hash冲突了。而HashMap的构造哈希映射的方法是取余数法:f(key) = key mod p (p<=m) m为哈希表表长。
hash函数
HashMap解决哈希冲突的方法是将key的哈希值对数组长度求余的结果作为元素数组index,将index相同的元素通过头插法的方式插入到同一个链表里。HashMap中会通过hash()函数来对hash值进行处理,然后再通过将哈希值对数组长度取余来得到该元素在数组中的位置。那么就有几个问题:
1.hash()的作用是什么?可以看出hash函数是对hash值和hash值的右移7位的结果以及hash值右移4位的结果进行异或处理。其实这个函数是对hash值进行扰动,这样得到的结果在indexfor函数中与length-1进行与操作时,可以增加其不确定性,减少哈希冲突的可能性。比如说hashmap的长度位16,那么length-1就是1111,如果直接拿没有经过处理的hash值和1111进行与操作,其实就是对hash值的后四位进行处理,如果两个key的hash值后四位相同那么最终的结果就相同,就会造成hash冲突。而经过hash函数的扰动之后,hash值后四位相同的可能性就降低了,从而哈希冲突的可能性也就降低了。
2.为什么&操作可以进行取余?
能够这样操作的前提是length是2的次幂。这也是为什么在Hashmap初始化和扩容时都要求长度为2的次幂。比如当length为16时,length-1为1111,hash值&1111的结果就是去hash值的后四位,那么为什么后四位就是余数呢?hash值/16相当于hash>>4得到的是hash和16的商,因此右移过去的四位就是余数。
static int hash(int h) {
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
HashMap 构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY) {
initialCapacity = MAXIMUM_CAPACITY;
} else if (initialCapacity < DEFAULT_INITIAL_CAPACITY) {
initialCapacity = DEFAULT_INITIAL_CAPACITY;
}
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Android-Note: We always use the default load factor of 0.75f.
// This might appear wrong but it's just awkward design. We always call
// inflateTable() when table == EMPTY_TABLE. That method will take "threshold"
// to mean "capacity" and then replace it with the real threshold (i.e, multiplied with
// the load factor).
threshold = initialCapacity;
init();
}
HashMap构造函数有两个参数,分别是负载因子loadFactor和初始容量initialCapacity.那么这两个参数有什么意义呢?
1.影响扩容:
在构造函数中阈值threshold会被赋值为initialCapacity。每次进行put操作时,如果size>threshold,就会进行扩容操作,将原来数组大小变成原来的两倍,并重新计算hash值放置元素位置。而扩容操作是个非常耗性能的操作,因此需要根据业务需求来合理设置initialCapacity和loadFactor。
2.影响查找效率:
数组的查找效率高但是删除和插入的效率低,而链表的删除和插入效率高但是查找效率低,Hashmap采用数组+链表来保证查找效率和插入删除的效率。但是如果负载因子太大,可能导致某个链表长度太长影响查找效率,而负载因子太小会导致扩容情况的出现。(JDK1.8中对于单个链表元素个数大于8时,自动转为红黑树,提高查找效率)。
HashMap 的put和扩容
public V put(K key, V value) {
//如果当前table为空,初始化table.
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
// 获得扰动处理后的hash值
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
// 取余数得到数组位置
int i = indexFor(hash, table.length);
//遍历链表,如果已经存在则替换并返回旧值。
for (HashMapEntry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//如果没找到,添加元素节点。
addEntry(hash, key, value, i);
return null;
}
先来看看inflateTable如何进行初始化。
private void inflateTable(int toSize) {
//保证数组大小是不小于toSize的2次幂数,具体算法分析待定。
int capacity = roundUpToPowerOf2(toSize);
//阈值为capacity * loadFactor,因此真正起作用的阈值是在这里被赋值的,而不是构造函数中的。
float thresholdFloat = capacity * loadFactor;
if (thresholdFloat > MAXIMUM_CAPACITY + 1) {
thresholdFloat = MAXIMUM_CAPACITY + 1;
}
threshold = (int) thresholdFloat;
//table是HashMapEntry数组
table = new HashMapEntry[capacity];
}
接着HashMap允许key为null的元素插入。
private V putForNullKey(V value) {
//可以看出key为null的元素是存储在table[0]的位置上。
for (HashMapEntry e = table[0]; e != null; e = e.next) {
//如果已经存在key为null的元素,就替换掉原来的值。table[0]只会存储一个key为null的元素,发生冲突就替换。
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//如果不存在就添加进来,hash值为0.
addEntry(0, null, value, 0);
return null;
}
如果当前元素个数>=阈值threshold而且链表头节点已经有该key的元素,则扩容。
如果扩容会将数组容量变成原来的两倍,并且重新计算hash值和在数组中的索引位置。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMapEntry e = table[bucketIndex];
//头插法
table[bucketIndex] = new HashMapEntry<>(hash, key, value, e);
size++;
}
为什么插入是头插法呢,可以看HashMapEntry的构造函数
HashMapEntry(int h, K k, V v, HashMapEntry n) {
value = v;
//将next指针指向n,而此时n是头节点。
next = n;
key = k;
hash = h;
}
接下来看扩容是怎么实现的。
void resize(int newCapacity) {
HashMapEntry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//new一个新的容量的数组
HashMapEntry[] newTable = new HashMapEntry[newCapacity];
//
transfer(newTable);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
// 扩容之后需要重新放置元素,把旧的元素拷贝到新的数组中去。
void transfer(HashMapEntry[] newTable) {
int newCapacity = newTable.length;
for (HashMapEntry e : table) {
//使用头插法插入元素
while(null != e) {
//保存下一个旧元素地址。
HashMapEntry next = e.next;
int i = indexFor(e.hash, newCapacity);
//旧元素的next指针指向当前头结点。
e.next = newTable[i];
//当前头结点再指向旧元素,实现头插法
newTable[i] = e;
e = next;
}
}
}
HashMap的遍历方式及性能差异
HashMap有两种常用遍历方式:
- EntrySet循环遍历:
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
- KeySet循环遍历:
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}
两种遍历方式的区别在于:EntrySet返回的是所有Entry节点集合,KeySet返回的是所有Key的集合,在性能上没有差别。性能有差别的地方在于获取value值。EntrySet
方式只需要遍历一次就可以获得value值,但是HashMap.get(key)需要再遍历一遍。