作者信息

最近,国防科技大学的一个研究小组提出了一种利用阵列相机去除前景遮挡成像的新方法
作为国内外第一个基于深度学习的去遮挡成像工作,作者提出了掩模嵌入的方法来解决训练数据不足的问题,并建立了仿真和实测数据集,对该领域的算法进行了评价。
背景
透视前景遮挡对于许多计算机视觉应用都是有利的,例如监视中的检测和跟踪。但是由于前景遮挡,某些光线无法照射到传统单视图相机(例如,数字单镜头反光)的传感器上。因此遮挡物后面的物体无法被完全观察到并可靠地重建。
近年来,由于相机阵列可以记录光场(LF)并为大量视点提供丰富的角度信息,因此它们得到了飞速发展。不同视点之间的补充信息有利于遮挡表面的重建,因为在某些视图中遮挡的背景对象可以通过其他视图看到。如图1所示,光场去遮挡(LFDeOcc)旨在使用相机阵列捕获的子孔径图像(SAI)消除前景遮挡。
已经有人提出了有关LF DeOcc的开拓性工作。使用重新聚焦方法。但是由于混合了来自遮挡物的光线和背景,因此该方法无法恢复遮挡物的干净表面。实际上,正确地选择仅属于被遮挡对象的像素是重要但具有挑战性的。为此,现有方法通常建立不同的模型来处理LFDeOcc问题。由于现实世界中场景的高度复杂,这些带有手工特征提取和立体匹配技术的方法无法获得令人满意的性能。
近年来,深度学习已成功用于不同的LF任务,例如深度估计,图像超分辨率,视图合成和LF内在函数。这些网络在许多领域都实现了最先进的性能。但是,据我们所知,由于一些问题,尚未将深度学习用于LF-DeOcc。
介绍
在本文中,作者计了一种新颖有效的范式,并提出了第一个深度学习网络(即DeOccNet)来处理LF-DeOcc问题。具体来说,我们总结了基于深度学习的LF-DeOcc中的三个主要挑战,并使用我们提出的范例为这些挑战提供了解决方案。
第一个挑战是,与LF深度估计网络和LF超分辨率网络相比,LF-DeOcc网络应使用来自被遮挡表面的尽可能多的信息,同时保持更大的接收场来覆盖不同类型和规模的遮挡。我们通过采用编码器-解码器网络对LF结构进行编码来应对这一挑战。我们将所有SAI沿通道维度连接起来,以充分利用被遮挡表面的信息。此外,我们使用残差的无空间金字塔金字塔(ASPP)模块提取多尺度特征并扩大接收场。
第二个挑战是,与单个图像修复网络相比,LF-DeOcc网络必须学习场景结构以自动识别,标记和删除前景遮挡。我们通过将无遮挡的中心视图SAI设置为地面真实性来应对这一挑战,并以端到端的方式训练我们的DeOccNet。这样,我们的网络就可以通过视差识别出背景中的遮挡,并自动删除前景遮挡。
第三个挑战是,LF-DeOcc网络面临训练数据不足的问题,因为无法使用前景可移动的大型LF数据集。而且,测试场景也不足以进行性能评估。我们通过提出一种将不同的遮挡掩模嵌入现有LF图像的数据合成方法来应对这一挑战。使用这种方法,生成了1000多个LF来训练我们的网络。此外,我们还开发了几种合成的和实际的LF用于性能评估。实验结果证明了我们的范例的有效性。与其他最先进的方法相比,我们的DeOccNet在合成和真实场景上均具有出色的性能。

图1:使用渲染场景Syn01的LF-DeOcc的图示。 (a)现场配置。 具有5×5块的黄色框代表摄像机阵列。(b)被遮挡的中央视景图像。 (c)我们的DeOccNet的结果。 (d)无咬合的地面真相。
相关工作
单幅图像修复
单一图像修复方法旨在使用邻域信息和全局先验来填充图像中的孔。单幅图像修复的主要挑战在于为缺失区域合成视觉逼真的和语义上合理的像素。
光场去遮挡
LF-DeOcc是一个活跃的研究主题,已经进行了数十年的研究。[18]提出了一种重新聚焦的方法,即通过将每个SAI扭曲特定值,然后将扭曲的SAI沿角度尺寸平均。
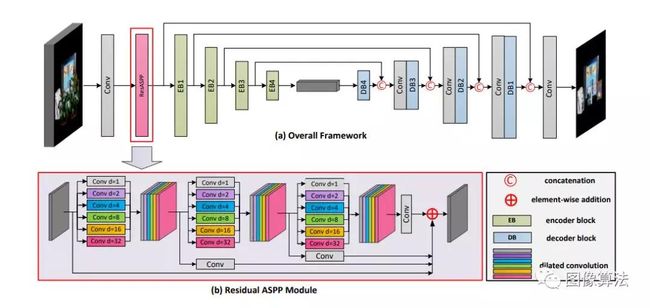
图2:我们的DeOccNet概述。 (a)总体架构。 (b)剩余ASPP模块的结构。
光领域的深度学习
深度神经网络已广泛用于各种LF任务,例如图像超分辨率,视图合成和深度估计。与这些任务相比,用于LF-DeOcc的网络应具有更大的接收范围,并使用更多的被遮挡表面信息。目前,文献中尚无有关基于深度学习的LF-DeOcc的现有工作。
方法
网络架构
作者的DeOccNet的任务是用背景像素替换遮挡像素, 为了完成此任务,自作者的网络需要找到对应关系并合并来自SAI的补充信息。注意,前景遮挡通常具有浅深度和大差异。即遮挡像素在SAI之间总是具有非常大的位置变化。因此,我们的网络需要具有大接收域的多尺度特征。
残留的ASPP模块:在我们的网络中,输入体积首先由1×1卷积层处理以生成具有固定深度的特征。
编码器路径:将由残留ASPP模块生成的特征传输到编码器路径,在此将4个编码器块级联以合并空间和角度信息。具体地,如图3所示,每个编码器块包含三个级联单元。在每个单元中,将批归一化的特征赋予两条分离的路径,以实现局部残差学习。
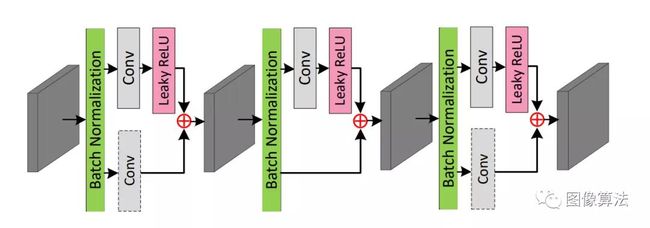
图3:编码器和解码器模块的结构。 注意,编码器和解码器块共享镜像结构。 即,在每个编码器块的第三单元中使用跨步卷积,而在每个解码器块的第一单元中使用反卷积。
解码器路径:经过瓶颈后,将通过解码器路径对特征进行解码。注意,解码器块具有作为编码器块的镜像结构。
遮罩嵌入,用于训练数据综合
重要的是要提供足够的数据来训练我们的DeOccNet, 尽管可以通过捕获带有/不带有前景遮挡的真实场景来获取具有可移动遮挡的LF,或者通过使用3dsMax2和Blender3之类的软件渲染合成场景来获取LF,但是这些方法的计算强度很大,因此,重要的是设计一种有效的方法来生成大量数据以进行网络训练。在本文中,我们提出了“掩膜嵌入”,一种训练数据综合方法,用于合成具有可移动前景遮挡的低频信号。图4显示了我们的掩膜嵌入方法。
如图4(a)所示,我们使用柳叶,网格,栅栏和剪纸等标签从Internet手动收集了80张蒙版图像。
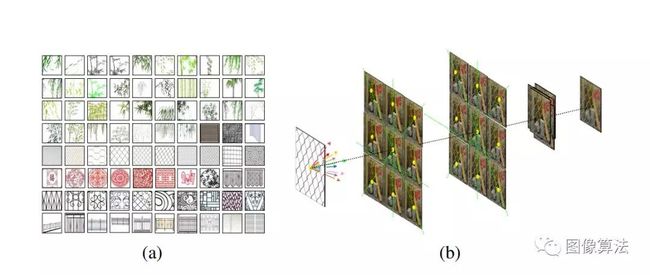
图4:我们的遮罩嵌入方法的示意图。 (a)我们的方法中使用的口罩。 请注意,执行裁剪和缩放以实现更好的可视化。 (b)我们的掩膜嵌入方法。 在此,以3×3 LF为例。
值得注意的是,场景中的前景和背景是相对的概念。也就是说,如图5所示,在多遮挡情况下,某些遮挡也可以视为背景对象。

图5:LF-DeOcc中的多遮挡情况。 (a)闭塞的中央视野SAI。 (b)我们的DeOccNet的结果是在较浅的深度((a)中的蓝色虚线)处纠正了输入。 最前面的树被视为前景遮挡。 (c)我们的DeOccNet的结果得到了更深层的纠正((a)中的红色虚线)。 三棵前树被视为前景遮挡。 因此,我们的DeOccNet可以产生不同的结果,而相同的输入会在不同的深度值处进行校正。
因此,对于LFDeOcc,应将训练和测试场景都校正为特定深度。在本文中,我们通过相应地裁剪每个SAI进行校正,以使遮挡具有正视差值,而背景具有负视差值。这样,我们的DeOccNet只需删除具有正视差值的对象即可有效地实现LF-DeOcc。最后,我们以112的步幅将遮挡的SAI裁剪为224×224像素块,并进行了2倍上采样以进行数据增强。同时,对无遮挡的中心视图SAI进行了裁剪和相应的上采样以生成地面真相。
实验
测试场景
真实世界的场景。我们在公开的CD场景中跟踪并测试了我们的方法。原始CD场景由分布在5×21网格上的105个视图组成。我们选择了中央5×15的视图进行绩效评估。Groundtruth图像由第二次捕获提供,并且去除了遮挡。此外,我们使用安装在龙门架上的移动Leica Q相机(带有F = 10,f = 28 mm镜头)拍摄了多个真实场景。在[23,29]中提出,在静态情况下,扫描方案等效于相机阵列的单次拍摄。我们将摄影机移至基线为3 cm的5×5网格上的25个位置。使用中的方法对捕获的图像进行校准。
合成场景
由于实际测试场景的数量很少,因此我们渲染了4个具有可移动前景遮挡的合成场景,以供进一步评估。我们合成场景中的所有元素都是从Internet上收集的,并且参数(例如照明,深度范围)已进行了调整,以更好地反映真实场景。每个场景的角分辨率设置为5×5,而基线和遮挡范围在不同场景中有所不同。还提供了无遮挡的中心视角SAI进行定量评估。

图6:在CD场景中获得的定性结果[16](遮挡率为40.2%)。 (a)被遮挡的中央视野SAI。 (b)-(e)通过不同方法获得的比较结果。 (f)我们的DeOccNet使用75个相同的中心视图SAI作为输入获得的结果(在第4.4节中讨论)。 (g)我们的结果。 (h)无遮挡的中央视野SAI。

图7:在我们自行开发的真实场景中获得的定性结果。 请注意,这三个场景的遮挡率分别为61.8%,57.7%和39.1%。
可以得出,DeOccNet确实是利用disparity的差异来解析场景结构,并利用视角间的互补信息实现遮挡物的去除,这与单帧图像修复的机制有所区别。
论文中采用L1误差、峰值信噪比PSNR以及结构相似度SSIM进行数值评价,结果如下表所示。
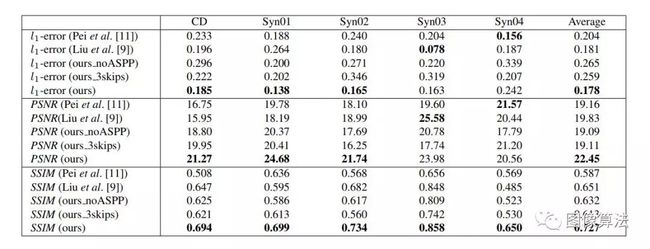
表1:通过DeOccNet的不同方法和不同设计选择获得的定量结果。 请注意,对于l1误差,较小的分数表示较好的性能,对于PSNR和SSIM,较高的分数表示较好的性能。
结论
在本文中,作者提出了DeOccNet,这是第一个基于深度学习的LF-DeOcc方法。我们将遮罩嵌入现有的LF中以生成大型训练数据集。在合成和真实场景上进行的实验表明,我们的DeOccNet可以通过视差差异自动删除前景遮挡,并且与现有方法相比,性能更高。
论文地址源码下载地址:关注“图像算法”微信公众号 回复“DeOccNet”