Python貌似有点火热,上手还是比较简单的,自己找了个教程也偷偷的学习一下,扒了一下网上的图片和数据,感觉并不是很难呀(不过之前换电脑,代码丢了,有点可惜,不过网上教程一抓一大把,随便看看也能扒一些基础的图片了),所以就有了这么一篇基础的学习笔记,自己记录一下,方便自己以后要用的话很快的能够捡起来。
编译型语言
通过编译器,统一编译,一次性执行,最终生成可执行文件(相对执行更快)
代表语言:C语言
解释型语言
逐行解释每一行代码,逐行编译,逐行执行(跨平台运行能力更强),在不同的操作系统上安装不同的解释器,相同源代码使用不同的解释器进行工作
代表语言:Python
优缺点
优点
- 简单,易学
- 可读性强
- 开发速度快
- 面向对象
- 免费,开源
- 可扩展性
- 具有丰富的库
缺点
- 运行速度相对较慢
- 国内市场较小
- 中文资料匮乏
设计哲学
- 优雅(代码工整)
- 明确
- 简单
用一种方法,最好是只有一种方法来做一件事情
Python特点
- 完全面向对象的语言(一切皆对象)
- 拥有一个强大的标准库
- Python社区提供了大量的第三方模块
Python3.0没有考虑向下的兼容
Python解释器
- CPython -- 官方版本的C语言实现
- Jython -- 可以运行在Java平台
- IronPython -- .NET和Mono平台
- PyPy -- Python实现的,支持JIT即时编译
Python变量
1.不用事先声明变量,赋值过程中就包含了变量的声明和定义的过程
2.用"=" 赋值,左边是变量名,右边是变量值
3.使用前必须先被初始化(先被赋值)
4.可以通过del语句删除不再使用的变量
标识符
- 区分大小写
- 第一个字符必须是字母或者下划线
- 不能使用关键字
- 以双划线开头或者结尾的名称通常有特殊意义,不建议使用
模块和包名 -> 全小写,尽量简单
函数名 -> 全小写,多个单词用下划线隔开
类名 -> 首字母大小,采用驼峰命名法
常量名 -> 全大写,多个单词使用下划线隔开
链式赋值
使用同一个对象赋值给多个变量 x = y = 123
系列解包赋值
系列数据赋值给对应相同个数的变量(个数必须保持一致)
a,b,c=4,5,6
常量
Python不支持常量,没有语法规则限制改变一个常量的值。只能约定常量的命名规则,以及在程序的逻辑上不对常量的值做出修改
数字
// 整数除法 7//2 -> 3
** 幂 2**3 -> 8
divmod()函数同事得到商和余数 :
divmod(13,3) ->(4,1) 返回元组
整数
int_var = 1
0b或者0B -> 二进制
0o或者0O -> 八进制
0x或者0X -> 十六进制
自动转型,整数和浮点数相加 自动转化成浮点数
Python3中,int可以存储任意大小的整数,long 被取消
使用int()实现类型转换
1.浮点数直接舍去小数部分。 int(9.9) -> 9
2.布尔值True转为1,False转为0。 int(True) -> 1
3.字符串符合整数格式(浮点数据格式不行)则转换成对应整数,否则报错
时间的表示
1970年1月1日0点开始,以毫秒计算
time.time()获得当前时刻,返回的是以秒为单位精度的浮点值
浮点数
float_var = 1.0
round(value)可以返回四舍五入的值,但不会改变原有值,产生新的值
布尔型
True False
字符串型
字符串
字符串是不可变的 没有字符类型,单个字符也是字符串
Python3直接使用Unicode,可以表示世界上任何书名语言的字符
ord('苏') -> 获取单个字符的Unicode编码。chr(65) 获取Unicode编码表示的字符
Python允许空字符串的存在,不包含任何字符且长度为0
字符串切片slice操作
str = "I Love Python"
print(str[2:5]) // 输出第三个到第五个之间的字符,不包括第六个
print(str[:5]) // 输出0-5之间的字符串 (不包括第六个)
print(str[2:]) // 输出第3-最后一个的字符串(包括最后一个)
print(str * 2) // 输出字符串两次
print(str + " And Java") // 拼接之后输出
print(str[0:5:2]) // 最后一个代表步长step
print(str[-6]) // 倒数6个 Python
print(str[::-1]) // 步长为负,从右到左反向提取
字符串搜索
str.isalnum() // 所有字符全是字母或者数字
str.count("Love") // 指定字符出现的次数
str.find("L") // 返回首次出现的下标
str.rfind("o") // 反向搜索,返回首次出现的下标
去除字符串信息
str.strip("*") // 去除首尾指定信息
str.lstrip("*") // 去除字符串首部左边指定信息
str.rstrip("*") // 去除字符串尾部右边指定信息
大小写转换
str.capitalize() // 产生新的字符串,首字母大写
str.title() // 产生新的字符串,每个单词首字母大写
str.upper() // 产生新的字符串 ,所有字符串转换成大写
str.lower() // 产生新的字符串 ,所有字符串转换成小写
str.swapcase() // 产生新的字符串 ,所有字母大小写转换
排版格式
aa = "str"
print(aa.center(10, "*")) ->***str****
print(aa.ljust(10, "*")) ->str*******
print(aa.rjust(10, "*")) ->*******str
format格式化
aa = "名字是:{0},年龄是:{1}。{0}是个好小伙"
print(aa.format("Steven", 18))
b = "名字是:{name},年龄是:{age}。{name}是个好小伙"
print(b.format(name="Steven", age=18)) // 名字是:Steven,年龄是:18。Steven是个好小伙
填充和对齐
填充和对齐一起使用
^、<、>分别是居中、左对齐、右对齐。后面带宽度
:号后面带填充的字符,只能是一个字符,不指定的话默认是空格填充
a = "我的电话号码是{0:*^11}"
print(a.format(888)) // 我的电话号码是****888****
数字格式化
浮点数通过f,整数通过d进行需要的格式化
数字 格式 输出 描述
3.1415926 {:.2f} 3.14 保留小数点后两位
3.1415926 {:+.2f} 3.14 带符号保留小数点后两位
2.71828 {:.0f} 3 不带小数
5 {:0>2d} 05 数字补零 (填充左边, 宽度为 2)
5 {:x<4d} 5xxx 数字补 x (填充右边, 宽度为 4)
10 {:x<4d} 10xx 数字补 x (填充右边, 宽度为 4)
1000000 {:,} 1,000,000 以逗号分隔的数字格式
0.25 {:.2%} 25.00% 百分比格式
1000000000 {:.2e} 1.00E+09 指数记法
13 {:10d} 13 右对齐 (默认, 宽度为 10)
13 {:<10d} 13 左对齐 (宽度为 10)
13 {:^10d} 13 中间对齐 (宽度为 10)
字符串拼接
- +两边都是字符串,则拼接
- +两边都是数字,则加法运算
- +两边类型不同,则抛异常
不换行打印
print("字符串",end = "*") 打印时不会换行,换行符替换成了*符号,使用*连接。*可以是任意字符串
str()实现数字转型字符串
replace()会生成一个新的字符串对象
join字符串拼接
"".join(列表) ->使用将列表中的字符串连接起来
可变字符串 io.StringIo(s)
修改过程中不会产生新的字符串对象
列表
类似于Java中的数组,是一个有序可变的集合容器,支持内置的基础数据结构甚至是列表,列表是可以嵌套的。不同的数据结构可以放在同一个列表中,没有统一类型的限制
list_a = ["str", 1, 1.0]
元组
不可变的列表,在赋值之后就不能二次更改了
tuple_a = ("str", 1, ["a", "b", 1], 2.0)
输出结果: ('str', 1, ['a', 'b', 1], 2.0)
字典(用的比较多)
类似于Java中的map,key-value键值对的形式 无序的容器
dict_a = {
"name": "Steven",
"age": 27,
1: "1800000000"
}
print(dict_a) // {'name': 'Steven', 'age': 27, 1: '1800000000'}
print(dict_a["name"]) // Steven
print(dict_a[1]) // 1800000000
print("name" in dict_a) 判断是否包含改键值// True
print(dict_a.keys()) // dict_keys(['name', 'age', 1])
print(dict_a.values()) // dict_values(['Steven', 27, '1800000000'])
print(dict_a.items()) // dict_items([('name', 'Steven'), ('age', 27), (1, '1800000000')])
逻辑运算符
- and 与关系 类似于Java中的&& x and y ->x 为true,则返回y的值。x为false,则直接返回false
- or 或关系 类似于Java中的|| x or y ->x 为true,则直接返回true。x为false,则返回y的值
- not 非 类似于Java中的!
同一运算符is(is not)
用于比较两个对象的存储单元,实际比较的是对象的地址
整数缓存问题
Python仅仅在命令行中执行时对较小的整数对象进行缓存,范围为[-5,256]之内的整数缓存起来。而在Pycharm或者保存为文件执行时,缓存范围是[-5,任意正整数]
if语句
if (a == b):
print("a == b")
else:
print("a != b")
turtle图形绘制库
\行连接符 续行符
变量位于:堆内存
对象位于:栈内存
序列
序列是一种数据存储方式,用来存储一系列的数据。在内存中,序列就是一块用来存放多个值的连续的内存空间。
常用的序列结构:字符串、列表、元组、字典、集合
列表:用于存储任意数目、任意类型的数据集合。
列表对象的常用方法汇总如下:
方法 要点 描述
list.append(x) 增加元素 将元素 x 增加到列表 list 尾部
list.extend(aList) 增加元素 将列表 alist 所有元素加到列表 list 尾部
list.insert(index,x) 增加元素 在列表 list 指定位置 index 处插入元素 x
list.remove(x) 删除元素 在列表 list 中删除首次出现的指定元素 x
list.pop([index]) 删除元素 删除并返回列表 list 指定位置 index 处的元素,默认是最后一个元素
list.clear() 删除所有元素 删除列表所有元素,并不是删除列表对象
list.index(x) 访问元素 返回第一个 x 的索引位置,若不存在 x 元素抛出异常
list.count(x) 计数 返回指定元素 x 在列表 list 中出现的次数
len(list) 列表长度 返回列表中包含元素的个数
list.reverse() 翻转列表 所有元素原地翻转
list.sort() 排序 所有元素原地排序
list.copy() 浅拷贝 返回列表对象的浅拷贝
Python的列表大小可变,根据需要随时增加或缩小
列表的创建
基本语法[ ]创建
a = [10,20,'gaoqi','sxt']
a = [] #创建一个空的列表对象
list()创建
使用 list()可以将任何可迭代的数据转化成列表。
a = list() #创建一个空的列表对象
a = list(range(10))
a - > [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a = list("gaoqi,sxt")
a - > ['g', 'a', 'o', 'q', 'i', ',', 's', 'x', 't']
range()创建整数列表
range()可以帮助我们非常方便的创建整数列表,这在开发中及其有用。语法格式为:
range([start,] end [,step])
start 参数:可选,表示起始数字。默认是 0
end 参数:必选,表示结尾数字。
step 参数:可选,表示步长,默认为 1
python3 中 range()返回的是一个 range 对象,而不是列表。我们需要通过 list()方法将其转换成列表对象
a = [x*2 for x in range(100) if x%9==0] #通过 if 过滤元素
[0, 18, 36, 54, 72, 90, 108, 126, 144, 162, 180, 198]
列表元素的增加和删除
当列表增加和删除元素时,列表会自动进行内存管理,大大减少了程序员的负担。但这个特点涉及列表元素的大量移动,效率较低。除非必要,我们一般只在列表的尾部添加元素或删除元素,这会大大提高列表的操作效率。
append()方法
原地修改列表对象,是真正的列表尾部添加新的元素,速度最快,推荐使用。
a = [20,40]
a.append(80)
+运算符操作
并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。这样,会涉及大量的复制操作,对于操作大量元素不建议使用。
a = a+[50]
extend()方法
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象。
a.extend([50,60])
insert()插入元素
使用 insert()方法可以将指定的元素插入到列表对象的任意制定位置。这样会让插入位置后
面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用。
类似发生这种移动的函数还有:remove()、pop()、del(),它们在删除非尾部元素时也会发生操作位置后面元素的移动。
a.insert(2,100)
列表元素的删除
本质上是列表的拷贝,将后面的赋值拷贝到前面的值中
del 删除
del a[1]
pop()方法
pop()删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
a = [10, 20, 30, 40]
a.pop() -> 返回 40
a.pop(1) -> 返回 20
remove()方法
删除首次出现的指定元素,若不存在该元素抛出异常。
a = [10,20,30,40,50,20,30,20,30]
a.remove(20)
列表元素访问和计数
通过索引直接访问元素
我们可以通过索引直接访问元素。索引的区间在[0, 列表长度-1]这个范围。超过这个范围则会抛出异常。
index()获得指定元素在列表中首次出现的索引
index()可以获取指定元素首次出现的索引位置。语法是:index(value,[start,[end]])。其中,
start 和 end 指定了搜索的范围。
count()获得指定元素在列表中出现的次数
len()返回列表长度
成员资格判断
判断列表中是否存在指定的元素,我们可以使用 count()方法,返回 0 则表示不存在,返回大于 0 则表示存在。但是,一般我们会使用更加简洁的 in 关键字来判断,直接返回 True或 False。
切片操作
切片是 Python 序列及其重要的操作,适用于列表、元组、字符串等等
切片 slice 操作可以让我们快速提取子列表或修改。标准格式为:
[起始偏移量 start:终止偏移量 end[:步长 step]]
操作和说明 示例 结果
[:] 提取整个列表 [10,20,30][:] [10,20,30]
[start:]从 start 索引开始到结尾 [10,20,30][1:] [20,30]
[:end]从头开始直到 end-1 [10,20,30][:2] [10,20]
[start:end]从start到 end-1 [10,20,30,40][1:3] [20,30]
[start:end:step] 从 start 提取到 end-1,步长是 step [10,20,30,40,50,60,70][1:6:2] [20, 40, 60]
其他操作(三个量为负数)的情况:
示例 说明 结果
[10,20,30,40,50,60,70][-3:] 倒数三个 [50,60,70]
10,20,30,40,50,60,70][-5:-3] 倒数第五个到倒数第三个(包头不包尾) [30,40]
[10,20,30,40,50,60,70][::-1] 步长为负,从右到左反向提取 [70, 60, 50, 40, 30, 20, 10]
切片操作时,起始偏移量和终止偏移量不在[0,字符串长度-1]这个范围,也不会报错。起始
偏移量小于 0 则会当做 0,终止偏移量大于“长度-1”会被当成”长度-1”
列表的遍历
for obj in listObj:
print(obj)
列表排序
修改原列表,不建新列表的排序
a.sort() #默认是升序排列
a.sort(reverse=True) #降序排列
random.shuffle(a) #打乱顺序
建新列表的排序
通过内置函数 sorted()进行排序,这个方法返回新列表,不对原列表做修改。
a = sorted(a) #默认升序
c = sorted(a,reverse=True) #降序
reversed()返回迭代器
内置函数 reversed()也支持进行逆序排列,与列表对象 reverse()方法不同的是,内置函数
reversed()不对原列表做任何修改,只是返回一个逆序排列的迭代器对象。
迭代器只能使用一次 第二次会返回空
a = [20,10,30,40]
c = reversed(a)
max 和 min
用于返回列表中最大和最小值。
max(a)
min(a)
sum
对数值型列表的所有元素进行求和操作,对非数值型列表运算则会报错。
sum(a)
多维列表
二维列表
一维列表可以帮助我们存储一维、线性的数据。
二维列表可以帮助我们存储二维、表格的数据。
a = [
["高小一",18,30000,"北京"],
["高小二",19,20000,"上海"],
["高小一",20,10000,"深圳"],
]
print(a[1][0],a[1][1],a[1][2])
元组 tuple
列表属于可变序列,可以任意修改列表中的元素。元组属于不可变序列,不能修改元组中的元素。因此,元组没有增加元素、修改元素、删除元素相关的方法。
元组支持如下操作:
1. 索引访问
2. 切片操作
3. 连接操作
4. 成员关系操作
5. 比较运算操作
6. 计数:元组长度 len()、最大值 max()、最小值 min()、求和 sum()等。
-
通过()创建元组。小括号可以省略。
a = (10,20,30) 或者 a = 10,20,30
如果元组只有一个元素,则必须后面加逗号。这是因为解释器会把(1)解释为整数 1,(1,)解释为元组。
-
通过 tuple()创建元组
tuple(可迭代的对象)b = tuple() #创建一个空元组对象 b = tuple("abc") b = tuple(range(3)) b = tuple([2,3,4])
tuple()可以接收列表、字符串、其他序列类型、迭代器等生成元组。
list()可以接收元组、字符串、其他序列类型、迭代器等生成列表。
元组的元素访问和计数
元组的元素不能修改
-
元组的元素访问和列表一样,只不过返回的仍然是元组对象。
a = (20,10,30,9,8) a[1] -> 10 a[1:3] -> (10, 30) a[:4] -> (20, 10, 30, 9) -
列表关于排序的方法 list.sort()是修改原列表对象,元组没有该方法。如果要对元组排序,只能使用内置函数 sorted(tupleObj),并生成新的列表对象。
a = (20,10,30,9,8) sorted(a) -> [8, 9, 10, 20, 30]
zip
zip(列表 1,列表 2,...)将多个列表对应位置的元素组合成为元组,并返回这个 zip 对象
a = [10,20,30]
b = [40,50,60]
c = [70,80,90]
d = zip(a,b,c)
list(d) -> [(10, 40, 70), (20, 50, 80), (30, 60, 90)]
生成器推导式创建元组
从形式上看,生成器推导式与列表推导式类似,只是生成器推导式使用小括号。列表推
导式直接生成列表对象,生成器推导式生成的不是列表也不是元组,而是一个生成器对象。
我们可以通过生成器对象,转化成列表或者元组。也可以使用生成器对象的__next__()
方法进行遍历,或者直接作为迭代器对象来使用。不管什么方式使用,元素访问结束后,如果需要重新访问其中的元素,必须重新创建该生成器对象。
s = (x * 2 for x in range(5))
print(tuple(s)) -> (0, 2, 4, 6, 8) #只能访问一次元素。第二次就为空了。需要再生成一次
元组总结
- 元组的核心特点是:不可变序列。
- 元组的访问和处理速度比列表快。
- 与整数和字符串一样,元组可以作为字典的键,列表则永远不能作为字典的键使用。
字典
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含:“键
对象”和“值对象”。可以通过“键对象”实现快速获取、删除、更新对应的“值对象”。
键”是任意的不可变数据,比如:整数、浮点数、字符串、元组。但是:列表、
字典、集合这些可变对象,不能作为“键”。并且“键”不可重复。
字典的创建
-
我们可以通过{}、dict()来创建字典对象。
a = {'name':'Steven','age':18,'job':'programmer'} b = dict(name='Steven',age=18,job='programmer') a = dict([("name","Steven"),("age",18)]) a = dict({("name", "Steven"), ("age", 18)}) a = dict({'name': 'Steven', 'age': 18, 'job': 'programmer'}) c = {} #空的字典对象 d = dict() #空的字典对象 -
通过 zip()创建字典对象
k = ['name','age','job'] v = ['Steven',18,'programmer'] d = dict(zip(k,v)) print(d) -> {'name': 'Steven', 'age': 18, 'job':'programmer'} -
通过 fromkeys 创建值为空的字典
a = dict.fromkeys(['name','age','job']) print(a) -> {'name': None, 'age': None, 'job': None} # none 是一个值,表示没有赋值
字典元素的访问
a = {'name':'Steven','age':18,'job':'programmer'}
-
通过 [键] 获得“值”。若键不存在,则抛出异常。
a['name'] -> 'Steven' -
通过 get()方法获得“值”。推荐使用。优点是:指定键不存在,返回 None;也可以设定指定键不存在时默认返回的对象。推荐使用 get()获取“值对象”。
a.get('name') -> 'Steven' a.get('sex','一个男人') -> '一个男人' -
列出所有的键值对
a.items() -> dict_items([('name', 'Steven'), ('age', 18), ('job', 'programmer')]) -
列出所有的键,列出所有的值
a.keys() -> dict_keys(['name', 'age', 'job']) a.values() -> dict_values(['Steven', 18, 'programmer']) -
len() 键值对的个数
len(a) a.__len__() -
检测一个“键”是否在字典中
print("name" in a) -> True
字典元素添加、修改、删除
-
给字典新增“键值对”。如果“键”已经存在,则覆盖旧的键值对;如果“键”不存在,
则新增“键值对”。a['address']='世界大厦1101' a['age']=16 print(a) -> {'name': 'Steven', 'age': 16, 'job': 'programmer', 'address': '世界大厦1101'} -
使用 update()将新字典中所有键值对全部添加到旧字典对象上。如果 key 有重复,则直接覆盖
b = {'name': 'StevenSon', 'money': 1000, 'sex': '男的'} a.update(b) print(a) -> {'name': 'StevenSon', 'age': 16, 'job': 'programmer', 'money': 1000, 'sex': '男的'} -
字典中元素的删除,可以使用 del()方法;或者 clear()删除所有键值对;pop()删除指定键值对,并返回对应的“值对象”;
del(a["name"]) print(a) -> {'age': 18, 'job': 'programmer'} a_value = a.pop("age") print(a) -> {'job': 'programmer'} print(a_value) -> 18 -
popitem() :随机删除和返回该键值对。若想一个接一个地移除并处理项,这个方法就非常有效(因为不用首先获取键的列表)。
print(a.popitem()) -> ('job', 'programmer') print(a) -> {'name': 'Steven', 'age': 18}
序列解包
序列解包可以用于元组、列表、字典。序列解包可以让我们方便的对多个变量赋值。
x,y,z=(20,30,10)
(a,b,c)=(9,8,10)
[a,b,c]=[10,20,30]
序列解包用于字典时,默认是对“键”进行操作; 如果需要对键值对操作,则需要使用
items();如果需要对“值”进行操作,则需要使用 values();
s = {'name':'gaoqi','age':18,'job':'teacher'}
name,age,job=s #默认对键进行操作
name,age,job=s.items() #对键值对进行操作
name,age,job=s.values() #对值进行操作
字典核心底层原理(重要)
字典对象的核心是散列表。散列表是一个稀疏数组(总是有空白元素的数组),数组的
每个单元叫做 bucket。每个 bucket 有两部分:一个是键对象的引用,一个是值对象的引用。
由于,所有 bucket 结构和大小一致,我们可以通过偏移量来读取指定 bucket。
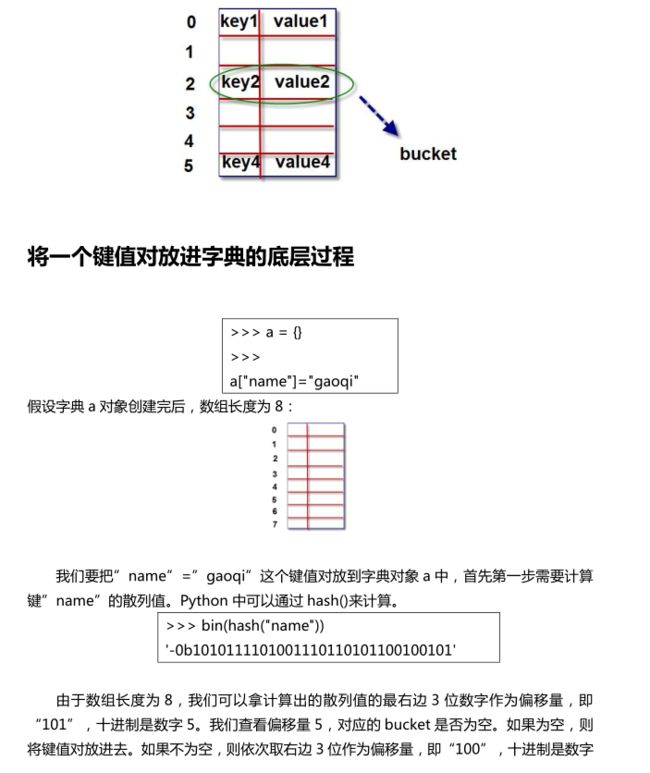

根据键查找“键值对”的底层过程

用法总结:
-
键必须可散列
(1) 数字、字符串、元组,都是可散列的。
(2) 自定义对象需要支持下面三点:1 支持 hash()函数 2 支持通过__eq__()方法检测相等性。 3 若 a==b 为真,则 hash(a)==hash(b)也为真。 字典在内存中开销巨大,典型的空间换时间。
键查询速度很快
往字典里面添加新建可能导致扩容,导致散列表中键的次序变化。因此,不要在遍历字典的同时进行字典的修改。 会报RuntimeError: dictionary changed size during iteration错误
集合
集合是无序可变,元素不能重复。实际上,集合底层是字典实现,集合的所有元素都是字典中的“键对象”,因此是不能重复的且唯一的。
集合创建和删除
-
使用{}创建集合对象,并使用 add()方法添加元素
a = {3, 5, 7} a.add(9) -
使用 set(),将列表、元组等可迭代对象转成集合。如果原来数据存在重复数据,则只保留一个。
b = set(a)
-
remove()删除指定元素;clear()清空整个集合
a.remove(3)
集合相关操作
Python 对集合提供了并集、交集、差集等运算
a = {1, 3, 'sxt'}
b = {'he', 'it', 'sxt'}
a|b 或者 a.union(b) #并集 -> {1, 3, 'sxt', 'he', 'it'}
a&b 或者 a.intersection(b) #交集 ->{'sxt'}
a-b 或者 a.difference(b) #差集 ->{1, 3}
控制语句
选择结构
单分支选择结构
if 语句单分支结构的语法形式如下:
if 条件表达式:
语句/语句块
num = input("输入一个数字:")
if int(num)<10:
print(num)
条件表达式详解
在选择和循环结构中,条件表达式的值为 False 的情况如下:
False、0、0.0、空值 None、空序列对象(空列表、空元祖、空集合、空字典、空字符串)、空 range 对象、空迭代对象。其他情况均为True
条件表达式中,不能有赋值操作符“=”
双分支选择结构
双分支结构的语法格式如下:
if 条件表达式 :
语句 1/语句块 1
else:
语句 2/语句块 2
三元条件运算符
Python 提供了三元运算符,用来在某些简单双分支赋值情况。三元条件运算符语法格式如下:
条件为真时的值 if (条件表达式) else 条件为假时的值
多分支选择结构
多分支选择结构的语法格式如下:
if 条件表达式 1 :
语句 1/语句块 1
elif 条件表达式 2:
语句 2/语句块 2
.
.
.
elif 条件表达式 n :
语句 n/语句块 n
[else:
语句 n+1/语句块 n+1
]
【注】计算机行业,描述语法格式时,使用中括号[ ]通常表示可选,非必选。
选择结构嵌套
选择结构可以嵌套,使用时一定要注意控制好不同级别代码块的缩进量,因为缩进量决定了代码的从属关系。
循环结构
循环结构用来重复执行一条或多条语句。表达这样的逻辑:如果符合条件,则反复执行循环体里的语句。在每次执行完后都会判断一次条件是否为 True,如果为 True 则重复执行循环体里的语句。
循环体里面的语句至少应该包含改变条件表达式的语句,以使循环趋于结束;否则,就会变成一个死循环。
while 循环
while 循环的语法格式如下:
while 条件表达式:
循环体语句
for 循环和可迭代对象遍历
for 循环通常用于可迭代对象的遍历。for 循环的语法格式如下:
for 变量 in 可迭代对象:
循环体语句
可迭代对象
Python 包含以下几种可迭代对象:
- 序列。包含:字符串、列表、元组
- 字典
- 迭代器对象(iterator)
- 生成器函数(generator)
- 文件对象
range 对象
range 对象是一个迭代器对象,用来产生指定范围的数字序列。格式为:
range(start, end [,step])
生成的数值序列从 start 开始到 end 结束(不包含 end)。若没有填写 start,则默认从 0开始。step 是可选的步长,默认为 1。
for i in range(10) 产生序列:0 1 2 3 4 5 6 7 8 9
for i in range(3,10) 产生序列:3 4 5 6 7 8 9
for i in range(3,10,2) 产生序列:3 5 7 9
break 语句
break 语句可用于 while 和 for 循环,用来结束整个循环。当有嵌套循环时,break 语句只能跳出最近一层的循环。
continue 语句
continue 语句用于结束本次循环,继续下一次。多个循环嵌套时,continue 也是应用于最
近的一层循环。
else 语句
while、for 循环可以附带一个 else 语句(可选)。如果 for、while 语句没有被 break 语句
结束,则会执行 else 子句,否则不执行。语法格式如下:
while 条件表达式:
循环体
else:
语句块
或者:
for 变量 in 可迭代对象:
循环体
else:
语句块
循环代码优化
编写循环时,遵守下面三个原则可以大大提高运行效率,避免不必要的低效计算:
- 尽量减少循环内部不必要的计算
- 嵌套循环中,尽量减少内层循环的计算,尽可能向外提。
- 局部变量查询较快,尽量使用局部变量
其他优化手段
- 连接多个字符串,使用 join()而不使用+
- 列表进行元素插入和删除,尽量在列表尾部操作
使用 zip()并行迭代
我们可以通过 zip()函数对多个序列进行并行迭代,zip()函数在最短序列“用完”时就会停止。
names = ("Steven","高老二","高老三","高老四")
ages = (18,16,20,25)
jobs = ("老师","程序员","公务员")
for name,age,job in zip(names,ages,jobs):
print("{0}--{1}--{2}".format(name,age,job)
执行结果:
Steven--18--老师
高老二--16--程序员
高老三--20--公务员
推导式创建序列
推导式是从一个或者多个迭代器快速创建序列的一种方法。它可以将循环和条件判断结合,
从而避免冗长的代码。推导式是典型的 Python 风格,会使用它代表你已经超过 Python 初
学者的水平。
列表推导式
列表推导式生成列表对象,语法如下:
[表达式 for item in 可迭代对象 ]
或者:
{表达式 for item in 可迭代对象 if 条件判断
[x*2 for x in range(1,5)] -> [2, 4, 6, 8]
[x*2 for x in range(1,20) if x5==0 ] -> [10, 20, 30]
[a for a in "abcdefg"] -> ['a', 'b', 'c', 'd', 'e', 'f', 'g']
cells = [(row,col) for row in range(1,10) for col in range(1,10)] #可以使用两个循环
字典推导式
字典的推导式生成字典对象,格式如下:
{key_expression : value_expression for 表达式 in 可迭代对象}
my_text = ' i love you, i love sxt,i love Steven'
char_count = {c:my_text.count(c) for c in my_text}
集合推导式
集合推导式生成集合,和列表推导式的语法格式类似:
{表达式 for item in 可迭代对象 }
或者:
{表达式 for item in 可迭代对象 if 条件判断}
生成器推导式(生成元组)
元组是没有推导式的,推导式推导出的是一个生成器,可以通过生成器生成元组。一个生成器只能运行一次。第一次迭代可以得到数据,第二次迭代发现数据已经没有了。
tunple((x for x in range(4))) -> (0, 1, 2, 3)
函数用法和底层分析
Python 函数的分类
Python 中函数分为如下几类:
- 内置函数
我们前面使用的 str()、list()、len()等这些都是内置函数,我们可以拿来直接使用。 - 标准库函数
我们可以通过 import 语句导入库,然后使用其中定义的函数 - 第三方库函数
Python 社区也提供了很多高质量的库。下载安装这些库后,也是通过 import 语句导
入,然后可以使用这些第三方库的函数 - 用户自定义函数
函数的定义和调用
核心要点
Python 中,定义函数的语法如下:
def 函数名 ([参数列表]) :
'''文档字符串'''
函数体/若干语句
Python 执行 def 时,会创建一个函数对象,并绑定到函数名变量上。即函数也是一个对象
-
参数列表
(1) 圆括号内是形式参数列表,有多个参数则使用逗号隔开
(2) 形式参数不需要声明类型,也不需要指定函数返回值类型
(3) 无参数,也必须保留空的圆括号
(4) 实参列表必须与形参列表一一对应
-
return 返回值
(1) 如果函数体中包含 return 语句,则结束函数执行并返回值;
(2) 如果函数体中不包含 return 语句,则返回 None 值。
return 返回值要点:
- 如果函数体中包含 return 语句,则结束函数执行并返回值;
- 如果函数体中不包含 return 语句,则返回 None 值。
- 要返回多个返回值,使用列表、元组、字典、集合将多个值“存起来”即可。
文档字符串(函数的注释)
通过三个单引号或者三个双引号来实现,中间可以加入多行文字进行说明。
调用 help(函数名.__doc__)可以打印输出函数的文档字符串
变量的作用域( 全局变量和局部变量)
全局变量:
在函数和类定义之外声明的变量。作用域为定义的模块,从定义位置开始直到模块
结束。全局变量降低了函数的通用性和可读性。应尽量避免全局变量的使用。
全局变量一般做常量使用。
-
函数内要改变全局变量的值,使用 global 声明一下
global a #如果要在函数内改变全局变量的值,增加 global 关键字声明
局部变量:
- 在函数体中(包含形式参数)声明的变量。
- 局部变量的引用比全局变量快,优先考虑使用。
- 如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量
参数的传递
函数的参数传递本质上就是:从实参到形参的赋值操作。 Python 中“一切皆对象”,
所有的赋值操作都是“引用的赋值”。所以,Python 中参数的传递都是“引用传递”,不
是“值传递”。具体操作时分为两类:
- 对“可变对象”进行“写操作”,直接作用于原对象本身。
- 对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填
充这块空间。(起到其他语言的“值传递”效果,但不是“值传递”)
可变对象:
字典、列表、集合、自定义的对象等
不可变对象:
数字、字符串、元组、function 等
传递可变对象的引用
传递参数是可变对象(例如:列表、字典、自定义的其他可变对象等),实际传递的还是对
象的引用。在函数体中不创建新的对象拷贝,而是可以直接修改所传递的对象
传递可变对象的引用
传递参数是可变对象,实际传递的还是对象的引用。在函数体中不创建新的对象拷贝,而是可以直接修改所传递的对象。
a = 100
def f1(n):
print("n:",id(n)) #传递进来的是 a 对象的地址
n = n+200 #由于 a 是不可变对象,因此创建新的对象 n
print("n:",id(n)) #n 已经变成了新的对象
print(n)
f1(a)
print("a:",id(a)
执行结果:
n: 1663816464
n: 46608592
300
a: 1663816464
浅拷贝和深拷贝
内置函数:copy(浅拷贝)、deepcopy(深拷贝)。
浅拷贝:不拷贝子对象的内容,只是拷贝子对象的引用。
深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象
传递不可变对象包含的子对象是可变的情况
传递不可变对象时。不可变对象里面包含的子对象是可变的。则方法内修改了这个可变对象,源对象也发生了变化
参数的几种类型
位置参数
函数调用时,实参默认按位置顺序传递,需要个数和形参匹配。按位置传递的参数,称为:“位置参数”。
默认值参数
我们可以为某些参数设置默认值,这样这些参数在传递时就是可选的。称为“默认值参数”。默认值参数放到位置参数后面。
命名参数
我们也可以按照形参的名称传递参数,称为“命名参数”,也称“关键字参数”。参数传递顺序可变
可变参数
可变参数指的是“可变数量的参数”。分两种情况:
*param(一个星号),将多个参数收集到一个“元组”对象中。
-
**param(两个星号),将多个参数收集到一个“字典”对象中。
def f1(a,b,*c): print(a,b,c) f1(8,9,19,20) def f2(a,b,**c): print(a,b,c) f2(8,9,name='gaoqi',age=18) def f3(a,b,*c,**d): print(a,b,c,d) f3(8,9,20,30,name='gaoqi',age=18
强制命名参数
在带星号的“可变参数”后面增加新的参数,必须在调用的时候“强制命名参数”
lambda 表达式和匿名函数
lambda 表达式可以用来声明匿名函数。lambda 函数是一种简单的、在同一行中定义函数
的方法。lambda 函数实际生成了一个函数对象。
lambda 表达式只允许包含一个表达式,不能包含复杂语句,该表达式的计算结果就是函数
的返回值
lambda 表达式的基本语法如下:
lambda arg1,arg2,arg3... : <表达式>
arg1/arg2/arg3 为函数的参数。<表达式>相当于函数体。运算结果是:表达式的运算结果。
eval()函数
功能:将字符串 str 当成有效的表达式来求值并返回计算结果。
nonlocal 关键字
nonlocal 用来声明外层的局部变量。
global 用来声明全局变量
LEGB 规则
Python 在查找“名称”时,是按照 LEGB 规则查找的:
Local-->Enclosed-->Global-->Built in
Local 指的就是函数或者类的方法内部
Enclosed 指的是嵌套函数(一个函数包裹另一个函数,闭包)
Global 指的是模块中的全局变量
Built in 指的是 Python 为自己保留的特殊名称。
对象
类
类的定义
定义类的语法格式:
class 类名:
类体
- 类名必须符合“标识符”的规则;一般规定,首字母大写,多个单词使用“驼峰原则”。
- 类体中我们可以定义属性和方法。
- 属性用来描述数据,方法(即函数)用来描述这些数据相关的操作。
__init__构造方法和__new__方法
类是抽象的,也称之为“对象的模板”。
__init__()的要点如下:
- 名称固定,必须为:__init__()
- 第一个参数固定,必须为:self。 self 指的就是刚刚创建好的实例对象。
- 构造函数通常用来初始化实例对象的实例属性
- 通过“类名(参数列表)”来调用构造函数
- __init__()方法:初始化创建好的对象,初始化指的是:“给实例属性赋值”
- __new__()方法: 用于创建对象,但我们一般无需重定义该方法。
- 如果我们不定义__init__()方法,系统会提供一个默认的__init__()方法。如果我们定义了带参
的__init__()方法,系统不创建默认的__init__()方法。
注:
Python 中的 self 相当于 C++中的 self 指针,JAVA 和 C#中的 this 关键字。
Python 中,self 必须为构造函数的第一个参数,名字可以任意修改。但一般遵守惯例,都叫做 self。
实例属性和实例方法
实例属性
实例属性是从属于实例对象的属性,也称为“实例变量”。
使用要点:
实例属性一般在\__init__()方法中通过如下代码定义:
self.实例属性名 = 初始值在本类的其他实例方法中,也是通过 self 进行访问:
self.实例属性名-
创建实例对象后,通过实例对象访问:
obj01 = 类名() #创建对象,调用__init__()初始化属性 obj01.实例属性名 = 值 #可以给已有属性赋值,也可以新加属性
实例方法
实例方法是从属于实例对象的方法。实例方法的定义格式如下:
def 方法名(self [, 形参列表]):
函数体
方法的调用格式如下:
对象.方法名([实参列表])
要点:
- 定义实例方法时,第一个参数必须为 self。和前面一样,self 指当前的实例对象。
- 调用实例方法时,不需要也不能给 self 传参。self 由解释器自动传参。
函数和方法的区别
- 都是用来完成一个功能的语句块,本质一样。
- 方法调用时,通过对象来调用。方法从属于特定实例对象,普通函数没有这个特点。
- 直观上看,方法定义时需要传递 self,函数不需要。
其他操作:
- dir(obj)可以获得对象的所有属性、方法
- obj._dict_ 对象的属性字典
- pass 空语句
- isinstance(对象,类型) 判断“对象”是不是“指定类型”
类对象、类属性、类方法、静态方法
类对象
类对象的类型就是type
pass 为空语句。就是表示什么都不做,只是作为一个占位符存在。当你写代码时,
遇到暂时不知道往方法或者类中加入什么时,可以先用 pass 占位,后期再补上。
类属性
类属性是从属于“类对象”的属性,也称为“类变量”。由于,类属性从属于类对象,可以
被所有实例对象共享。
类属性的定义方式:
class 类名:
类变量名= 初始值
class Student:
company = "SXT" #类属性
count = 0 #类属性
def __init_(self,name,score):
self.name = name #实例属性
self.score = scor
类方法
类方法是从属于“类对象”的方法。类方法通过装饰器@classmethod 来定义,格式如下:
@classmethod
def 类方法名(cls [,形参列表]) :
函数体
要点如下:
- @classmethod 必须位于方法上面一行
- 第一个 cls 必须有;cls 指的就是“类对象”本身;
- 调用类方法格式:“类名.类方法名(参数列表)”。 参数列表中,不需要也不能给 cls 传
值。 - 类方法中访问实例属性和实例方法会导致错误
- 子类继承父类方法时,传入 cls 是子类对象,而非父类对象
静态方法
Python 中允许定义与“类对象”无关的方法,称为“静态方法”。
“静态方法”和在模块中定义普通函数没有区别,只不过“静态方法”放到了“类的名字空
间里面”,需要通过“类调用”。
静态方法通过装饰器@staticmethod 来定义,格式如下:
@staticmethod
def 静态方法名([形参列表]) :
函数体
要点如下:
- @staticmethod 必须位于方法上面一行
- 调用静态方法格式:“类名.静态方法名(参数列表)”。
- 静态方法中访问实例属性和实例方法会导致错误
__del__方法(析构函数)和垃圾回收机制
__del__方法称为“析构方法”,用于实现对象被销毁时所需的操作。
__del__方法称为“析构方法”,用于实现对象被销毁时所需的操作。
可以通过 del 语句删除对象,从而保证调用__del__方法。系统会自动提供__del__方法,一般不需要自定义析构方法。
__call__方法和可调用对象
定义了__call__方法的对象,称为“可调用对象”,即该对象可以像函数一样被调用。
class SalaryAccount:
def __call__(self, salary):
yearSalary = salary*12
daySalary = salary//30
hourSalary = daySalary//8
return dict(monthSalary=salary,yearSalary=yearSalary,daySalary=daySalary,hourSalary=hourSalary)
s = SalaryAccount()
print(s(5000)
{'monthSalary': 5000, 'yearSalary': 60000, 'daySalary': 166, 'hourSalary': 20}
方法没有重载
Python 中,方法的的参数没有声明类型(调用时确定参数的类型),参数的数量也可以由
可变参数控制。
不要使用重名的方法!Python 中方法没有重载
方法的动态性
Python 是动态语言,我们可以动态的为类添加新的方法,或者动态的修改类的已有的方法。
Python 一切皆对象
私有属性和私有方法(实现封装)
Python 对于类的成员没有严格的访问控制限制,这与其他面向对象语言有区别。关于私有
属性和私有方法,有如下要点:
- 通常我们约定,两个下划线开头的属性是私有的(private)。其他为公共的(public)。
- 类内部可以访问私有属性(方法)
- 类外部不能直接访问私有属性(方法)
- 类外部可以通过“_类名__私有属性(方法)名”访问私有属性(方法)p._Employee__age
@property 装饰器
@property 可以将一个方法的调用方式变成“属性调用”。
class Employee
def __init__(self,name,salary):
self.name = name
self.__salary = salary
@property #相当于 salary 属性的 getter 方法
def salary(self):
print("月薪为{0},年薪为{1}".format(self.__salary,(12*self.__salary)))
return self.__salary;
@salary.setter
def salary(self,salary): #相当于 salary 属性的 setter 方法
if(0面向对象
继承
语法格式
Python 支持多重继承,一个子类可以继承多个父类。继承的语法格式如下:
class 子类类名(父类 1[,父类 2,...]):
类体
默认父类是 object 类
class Person:
def __init__(self,name,age):
self.name = name
self.__age = age
class Student(Person):
def __init__(self,name,age,score):
self.score = score
Person.__init__(self,name,age) #构造函数中包含调用父类构造函数。根据需要,不是必须。
子类并不会自动调用父类的\_\_init\_\_(),我们必须显式的调用
类成员的继承和重写
- 成员继承:子类继承了父类除构造方法之外的所有成员。
- 方法重写:子类可以重新定义父类中的方法,这样就会覆盖父类的方法,也称为“重写”
重写__str__()方法
object 有一个__str__()方法,用于返回一个对于“对象的描述”,对应于内置函数 str()
经常用于 print()方法,帮助我们查看对象的信息。__str__()可以重写。
多重继承
Python 支持多重继承,一个子类可以有多个“直接父类”。这样,就具备了“多个父类”的特点。但是由于这样会被“类的整体层次”搞的异常复杂,尽量避免使用。
MRO()
Python 支持多继承,如果父类中有相同名字的方法,在子类没有指定父类名时,解释器将
“从左向右”按顺序搜索。
MRO(Method Resolution Order):方法解析顺序。 我们可以通过 mro()方法获得
“类的层次结构”,方法解析顺序也是按照这个“类的层次结构”寻找的。
super()获得父类定义
在子类中,如果想要获得父类的方法时,我们可以通过 super()来做。
super()代表父类的定义,不是父类对象。
多态
多态(polymorphism)是指同一个方法调用由于对象不同可能会产生不同的行为。
- 多态是方法的多态,属性没有多态。
- 多态的存在有 2 个必要条件:继承、方法重写。
特殊方法和运算符重载
Python 的运算符实际上是通过调用对象的特殊方法实现的。
常见的特殊方法统计如下:
方法 说明 例子
__init__ 构造方法 对象创建:p = Person()
__del__ 析构方法 对象回收
__repr__,__str__ 打印,转换 print(a)
__call__ 函数调用 a()
__getattr__ 点号运算 a.xxx
__setattr__ 属性赋值 a.xxx = value
__getitem__ 索引运算 a[key]
__setitem__ 索引赋值 a[key]=value
__len__ 长度 len(a)
运算符 特殊方法 说明
运算符+ __add__ 加法
运算符- __sub__ 减法
<,<=,== __lt__,__le__,__eq__ 比较运算符
>,>=,!= __gt__,__ge__,__ne__ 比较运算符
|,^,& __or__,__xor__,__and__ 或、异或、与
<<,>> __lshift__,__rshift__ 左移、右移
*,/,%,// __mul__,__truediv__,__mod__,__floordiv__ 乘、浮除、模运算
(取余)、整数除
** __pow__ 指数运算
每个运算符实际上都对应了相应的方法
特殊属性
Python 对象中包含了很多双下划线开始和结束的属性,这些是特殊属性,有特殊用法
特殊方法 含义
obj.__dict__ 对象的属性字典
obj.__class__ 对象所属的类
class.__bases__ 类的基类元组(多继承)
class.__base__ 类的基类
class.__mro__ 类层次结构
class.__subclasses__() 子类列表
对象的浅拷贝和深拷贝
- 变量的赋值操作
只是形成两个变量,实际还是指向同一个对象。
- 浅拷贝
Python 拷贝一般都是浅拷贝。拷贝时,对象包含的子对象内容不拷贝。因此,源对象
和拷贝对象会引用同一个子对象。
- 深拷贝
使用 copy 模块的 deepcopy 函数,递归拷贝对象中包含的子对象。源对象和拷贝对象
所有的子对象也不同
组合
is-a”关系,我们可以使用“继承”。从而实现子类拥有的父类的方法和属性。
“has-a”关系,我们可以使用“组合”,也能实现一个类拥有另一个类的方法和属性。
设计模式_工厂模式实现
工厂模式实现了创建者和调用者的分离,使用专门的工厂类将选择实现类、创建对象进行统一的管理和控制。
class CarFactory:
def createCar(self,brand):
if brand == "奔驰":
return Benz()
elif brand == "宝马":
return BMW()
elif brand == '比亚迪':
return BYD()
else:
return "未知品牌,无法创建"
class Benz:
pass
class BMW:
pass
class BYD:
pass
factory = CarFactory()
c1 = factory.createCar("奔驰")
c2 = factory.createCar("宝马")
设计模式_单例模式实现
单例模式(Singleton Pattern)的核心作用是确保一个类只有一个实例,并且提供一个访问该实例的全局访问点。
class MySingleton:
__obj = None
__init_flag = True
def __new__(cls, *args, **kwargs):
if cls.__obj == None:
cls.__obj = object.__new__(cls) # 创建父类对象
return cls.__obj
def __init__(self,name):
if MySingleton.__init_flag: # 保证初始化只执行一次
print( "init....")
self.name = name
MySingleton.__init_flag = False
a = MySingleton( "aa")
print(a)
b = MySingleton( "bb")
print(b)
异常
在执行程序的时候遇到错误,会停止程序的执行,并提示错误信息,这就是异常
捕获异常
语法格式:
try:
# 尝试执行的代码
except:
# 出现错误的处理
捕获特殊错误类型
程序运行出错的第一个单词,就是错误类型
try:
# 尝试执行的代码
pass
except 错误类型1:
# 出现错误类型1的处理
pass
except (错误类型2, 错误类型3):
# 出现错误类型2或者错误类型3的处理
pass
捕获未知错误
except Exception as result: # result变量接收错误信息
print("未知错误 %s" % result)
异常捕获完整语法
try:
pass
except ValueError:
pass
except Exception as result:
pass
else:
# 没有异常执行的代码
pass
finally:
# 无论是否出现异常,都会执行。最后执行
pass
异常的传递
当函数/方法出现错误时,会把异常传递给函数/方法的调用处,直到主程序
当异常抛出到主程序时,仍然没有进行异常捕获,程序就会终止
利用异常的传递性,可以在主程序中捕获异常
抛出raise异常
创建一个Exception的对象
-
使用raise关键字抛出异常对象
# 创建异常对象 ex = Exception("异常描述信息") # 主动抛出异常 raise ex # raise + 异常对象
模块
模块的导入
import导入
模块导入关键字import,导入模块应该单行导入一个模块
模块名.的方式使用模块中提供的类,全局变量,函数
使用关键字as指定模块的别名,别名命名方法使用大驼峰命名法(单个单词首字母大写)
import 模块名 as 模块名
from...import导入
从一个模块中,导入部分工具
from 模块名 import 工具名
通过from导入之后,不需要通过模块名.的方式来使用。可以直接使用工具名进行使用
注意:如果两个模块,存在同名的函数,那么后导入的函数,会覆盖掉之前导入的函数。
一旦发现有同名的函数,可以使用as指定别名
模块的搜索顺序
- 搜索当前目录指定模块名的文件,如果有就直接导入
- 如果没有,再搜索系统目录
__name__属性
文件被导入时,能够直接执行的代码不需要被执行!因此需要使用__name__属性来做判断。
__name__是Python的一个内置属性,记录着一个字符串.
如果是被其他文件导入的,__name__就是模块名
如果是当前执行的程序__name__就是__main__
Python文件的标准代码格式:
# 导入模块
# 定义全局变量
# 定义类
# 定义函数
def main():
pass
# 根据__name__属性判断是否需要执行代码
if __name__="__main__"
main()
包
- 包是一个包含多个模块的特殊目录
- 目录下有一个特殊文件:__init__.py
- 包的命名方式和变量名一样,小写字母+下划线
使用import 包名 可以一次性导入包中的所有模块
__init__.py
要在外界使用包中的模块,需要在__init__.py文件中指定对外界提供的模块列表
from . import 模块列表
发布模块
将自己开发的模块,分享给其他人
制作发布压缩包

安装删除模块

pip安装删除模块

文件
文件操作步骤
- 打开文件 open()
- 读写文件 read() write()
- 关闭文件 close()
read()函数运行之后会将指针移动到文件末尾,再次读的话是读取不到内容的
文件复制
小文件
小文件直接复制
file = open("move.json", encoding="utf-8")
text = file.read()
copyFile = open("copyMove.json", mode="w", encoding="utf-8")
copyFile.write(text)
file.close()
copyFile.close()
大文件
大文件需要逐行复制
file = open("move.json", encoding="utf-8")
copyFile = open("copyMove.json", mode="w", encoding="utf-8")
while True:
text = file.readline() # 逐行读取
if not text:
break
copyFile.write(text)
file.close()
copyFile.close()
文件操作
文件操作需要导入os模块
rename() 重命名
remove() 删除文件
# 文件重命名
os.rename("copyMove.json", "reNameCopyMove.json")
# 删除文件
os.remove("reNameCopyMove.json")
文本编码格式
- Python2.x 默认是ASCII编码格式
- Python3.x 默认是UTF-8编码格式 (UTF-8是Unicode的一种)
Python2.x 中第一行增加一行代码注释就可以处理Python文件中的中文导致的错误
# *-* coding:utf8 *-* 官方推荐
# coding = utf8
eval函数
eval()函数将字符串当成有效的表达式,并返回计算结果
print(eval("1+1")) # 输出2
eval函数不要滥用,不要直接转换input结果
网络编程
IP地址
目的:用来标记网络上的一台设备(唯一)
dest_ip 目标IP
src_ip 源IP
ip地址的分类
IP地址由四组数字组成 (0-255)

端口
dest_port 目标端口
src_port 源端口
用来标识PC的应用进程
知名端口
知名端口0-1023 动态端口从1024-65535
80端口http服务 21端口分配给FTP服务
socket
import socket
# 创建一个socket UDP
udp_socket = socket.socketpair(socket.AF_INET, socket.SOCK_DGRAM)
# 绑定端口号
udp_socket.bind("端口号")
# 使用套接字收发数据 数据和对方的IP地址以及端口号
udp_socket.sendto("数据", ("192.158.33.23", 8080))
udp_socket.close()
UDP收发收据
同一个套接字可以收发数据
import socket
# UDP聊天器,并保存聊天记录
def main():
# 创建一个socket
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
file = open("chatRecord.txt", mode="a", encoding="utf-8")
while True:
print("UDP聊天器")
print("输入0结束程序")
print("输入1发送数据")
print("输入2接收数据")
input_data = int(input())
if 0 == input_data:
file.close()
break
elif 1 == input_data:
file.write(str(send_data(udp_socket)) + "\n")
elif 2 == input_data:
file.write(str(receive_data(udp_socket)) + "\n")
else:
print("输入错误")
udp_socket.close()
# socket 接收数据
def receive_data(udp_socket):
receive_data = udp_socket.recvfrom(1024)
print("发送者:%s\n发送内容:%s" % (str(receive_data[1]), receive_data[0].decode("gbk")))
return "发送者:%s\n发送内容:%s" % (str(receive_data[1]), receive_data[0].decode("gbk"))
# 使用套接字发送数据
def send_data(udp_socket):
dest_ip = input("请输入对方的ip地址:")
dest_port = int(input("请输入对方的端口号:"))
send_data = input("请输入要聊天的内容:")
udp_socket.sendto(send_data.encode("gbk"), (dest_ip, dest_port))
return str(send_data.encode("utf-8"), encoding="utf-8")
if __name__ == '__main__':
main()
TCP
TCP客户端收发数据
import socket
def main():
# 创建套接字
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket.bind(("", 7788))
# 连接服务器
tcp_socket.connect(("192.168.28.90", 8080))
send_data = input("请输入要发送的内容:")
# 发送数据
tcp_socket.send(send_data.encode("gbk"))
# 接收数据
receive_data = tcp_socket.recvfrom(1024)
print("发送者:%s\n发送内容:%s" % (receive_data[1], receive_data[0].decode("gbk")))
# 关闭套接字
tcp_socket.close()
if __name__ == '__main__':
main()
TCP服务端收发数据
import socket
# 创建socket
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定端口信息
tcp_server_socket.bind(("", 7000))
tcp_server_socket.listen(128)
new_client_socket, client_address = tcp_server_socket.accept()
print(client_address)
receive_data = new_client_socket.recv(1024)
print(receive_data.decode("gbk"))
new_client_socket.send("收到信息啦...".encode("gbk"))
new_client_socket.close()
tcp_server_socket.close()
多任务
多线程
线程执行的顺序不确定
调用线程的start()方法时才会创建线程,以及运行线程
import time
import threading
def sing():
for i in range(5):
print("------唱歌--------")
time.sleep(1)
def dance():
for i in range(5):
print("=========跳舞========")
time.sleep(1)
def main():
sing_thread = threading.Thread(target=sing) # 注意这里是要用函数名,不能用函数名()->这个是调用函数
dance_thread = threading.Thread(target=dance)
sing_thread.start()
dance_thread.start()
if __name__ == '__main__':
main()
多线程共享全局变量
全局变量的的修改:
在一个函数中对全局变量进行修改的时候,到底是否需要使用global进行说明,要看是否对全局变量的指向进行了修改
如果修改了指向,即全局变量指向了一个新的地方,那么必须使用global
如果仅仅是修改了指向空间中的数据,此时不用使用global
多线程共享全局变量会导致资源竞争问题
互斥锁
lock = threading.Lock() #创建锁
lock.acquire() # 上锁
lock.release() # 释放锁
GIL
