本文参考:http://www.it165.net/admin/html/201311/2045.html进行学习。
一.简述:
Hadoop是一种分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储。Hadoop 1.2.1版本下载地址:http://apache.dataguru.cn/hadoop/common/hadoop-1.2.1/
本文章配置的是完全分布模式。
hadoop 三种运行模式:
单机模式:无需任何守护进程,所有程序在单JVM上执行
伪分布模式:守护进程运行在本地机器上。
完全分布模式:守护进程运行在一个集群上。
二、准备安装环境
本机: windows8.1企业版X64,上面装有VMware vSphere Client。
测试服务器:公司一台DELL PowerEdgeT110测试服务器(上面安装有VMwareVsphere Esxi5.1),在Esxi上面虚拟了3个centos6.4。
JDK: jdk1.7.0_45
集群:一个master,两个slave,主机名称分别是node1,node2,node3.
机器名 |
IP |
作用 |
Node1 |
192.168.1.191 |
NameNode,JobTraker |
Node2 |
192.168.1.192 |
DataNode,TaskTraker |
Node3 |
192.168.1.193 |
DataNode,TaskTraker |
三 .安装
1.修改主机名称并设置hosts
设置主机名:Hostname node1(三台主机上分别设置)
Hostname node2
Hostname node3
修改hosts:Vim/etc/hosts,写入下列内容(三台主机都要设置)
192.168.1.191 node1
192.168.1.192 node2
192.168.1.193 node3
然后保证互ping可以通。
2.清除防火墙规则和临时关闭selinux。
防火墙设置:
保存规则:iptables-save>iptables-script
清除规则:iptables –F
临时关闭selinux :
使用命令setenforce 0
3.安装JDK
1.)下载JDK. 打开http://java.sun.com/javase/downloads/index.jsp


mkdir -p /usr/local/java/
tar -zxvf jdk-7u45-linux-x64.tar.gz
mv jdk1.7.0_45 /usr/local/java
修改/etc/profile,添加如下内容
JAVA_HOME=/usr/local/java/jdk1.7.0_45
JRE_HOME=$JAVA_HOME/jre
CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools/jar
PATH=$PATH:$HOME/bin:$JAVA_HOME:$JRE_HOME:$CLASSPATH:$JAVA_HOME/bin:/home/hadoop/hadoop-1.2.1/bin
export PATH
使配置生效
source /etc/profile
4.添加用户.
在root权限下使用以下命令添加hadoop用户,在三个虚拟机上都添加这个用户
useradd hadoop
将下载到的hadoop-1.2.1.tar文件放到/home/hadoop/目录下解压,然后修改解压后的文件夹的权限,命令如下:
Tar -zxvf hadoop-1.2.1.tar
Chown -R hadoop:hadoop hadoop-1.2.1
5.配置SSH无密码登录
在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的,这就须要在节点之间执行指令的时候是不须要输入密码的形式,故我们须要配置SSH运用无密码公钥认证的形式。
以本文中的三台机器为例,现在node1是主节点,他须要连接node2和node3。须要确定每台机器上都安装了ssh,并且datanode机器上sshd服务已经启动。
[hadoop@node1 ~]$ ssh-keygen -t rsa
这个命令将为hadoop上的用户hadoop生成其密钥对,询问其保存路径时直接回车采用默认路径,当提示要为生成的密钥输入passphrase的时候,直接回车,也就是将其设定为空密码。生成的密钥对id_rsa,id_rsa.pub,默认存储在/home/hadoop/.ssh目录下然后将id_rsa.pub的内容复制到每个机器(也包括本机)的/home/hadoop/.ssh/authorized_keys文件中,如果机器上已经有authorized_keys这个文件了,就在文件末尾加上id_rsa.pub中的内容,如果没有authorized_keys这个文件,直接复制过去就行。
下面是具体的过程:
1.)生成密钥对
su hadoop切换hadoop用户
cd /home/hadoop
ssh-keygen -t rsa
在/home/hadoop目录下会生成一个隐藏的.ssh目录。
ll -a

2.) 生成authorized_keys文件并测试
进入.ssh文件夹,然后将id_rsa.pub复制到authorized_keys文件,
命令如下:
cd .ssh
cp id_rsa.pub authorized_keys #生成authorized_keys文件
ssh localhost #测试无密码登陆,第一可能需要密码或者使用ssh node1命令。
注:在三台主机上都要执行上述命令。
3.)在node1、node2和node3上互换公钥。
在node2和node3执行以下命令
scp authorized_keys hadoop@node1:/tmp
#复制authorized_keys到node1的tmp目录中去
cat /tmp/authorized_keys>>/home/hadoop/.ssh/authorized_keys
#把公钥追加到文件后面。
现在node1上的authorized文件已经包含了三台主机的公钥。
最后把node1上的authorized_keys,再复制回node2和node3上。
scp /home/hadoop/.ssh/authorized_key root@node2:/home/hadoop/.ssh
4.)设置文件权限并测试。
chmod 644 authorized_keys 此步非常重要,如果权限不对,则无密码访问不成功。
测试三台主机之间无密码互访成功。

6.安装hadoop
将当前用户切换到hadoop用户,如果集群内机器的环境完全一样,可以在一台机器上配置好,然后把配置好的软件即hadoop-0.20.203整个文件夹拷贝到其他机器的相同位置即可。 可以将Master上的Hadoop通过scp拷贝到每一个Slave相同的目录下,同时根据每一个Slave的Java_HOME 的不同修改其hadoop-env.sh文件。
6.1)配置conf/hadoop-env.sh文件
切换到hadoop-1.2.1/conf目录下,添加JAVA_HOME路径

6.2)配置/conf/core-site.xml

fs.default.name是NameNode的URI。hdfs://主机名:端口/
hadoop.tmp.dir :Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器此目录,那么就需要重新执行NameNode格式化的命令。
6.3)配置/conf/mapred-site.xml

mapred.job.tracker是JobTracker的主机(或者IP)和端口。主机:端口。其中/home/hadoop/hadoop_home/var目录需要提前创建,并且注意用chown -R 命令来修改目录权限。
6.4)配置/conf/hdfs-site.xml

dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
此处的name1和data1等目录不能提前创建,如果提前创建会出问题。
6.5)配置master和slaves主从节点
配置conf/masters和conf/slaves来设置主从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。
vi masters:输入:
node1

vi slaves:输入
node2
node3

配置结束,把配置好的hadoop文件夹拷贝到另外两台主机中,并且保证上面的配置对于其他机器而言正确,
scp -r /home/hadoop/hadoop-1.2.1 root@node2:/home/hadoop/
#输入node2的root密码即可传输,如果java安装路径不一样,需要修改conf/hadoop-env.sh
四、Hadoop启动与测试
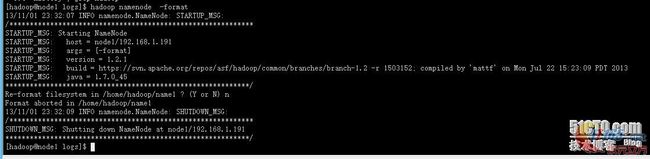
1、)格式化一个新的分布式文件系统
hadoop namenode -format #格式化文件系统
如下图(我的hadoop已经使用,不想重新格式化选择了No)
2、)启动所有节点
/home/hadoop/hadoop-1.2.1/bin/start-all.sh
3、)查看集群的状态:
hadoop dfsadmin -report

4、)Hadoop测试
浏览NameNode和JobTracker的网络接口,它们的地址默认为:
NameNode - http://192.168.1.191:50070/

JobTracker - http://192.168.1.191:50030/
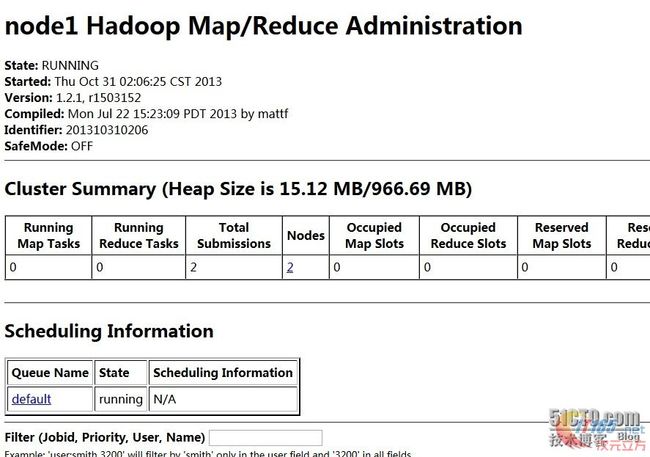
要想检查守护进程是否正在运行,可以使用 jps 命令(这是用于JVM 进程的ps 实用程序)。这个命令列出 5 个守护进程及其进程标识符。
将输入文件拷贝到分布式文件系统:
1.bin/hadoop fs -mkdir input #创建input目录
2.bin/hadoop fs -put conf/core-site.xml input #拷贝文件到input目录
3.bin/hadoop jar hadoop-examples-1.2.1.jar grep input output 'dfs[a-z]' #使用Hadoop运行示例

到此为止,hadoop已经配置完成。
五、Hadoop一些常用的操作命令
1、hdfs常用操作:
hadoop dfs -ls 列出HDFS下的文件
hadoop dfs -ls input 列出HDFS下某个文档中的文件
hadoop dfs -put 1.txt input/2.txt 上传文件到指定目录并重新命名,只有所有DataNode都接收完数据才算成功。
hadoop dfs -get input/1.txt test.txt 从HDFS下载文件并重新命名为test.txt,同put一样可操作文件也可操作目录

hadoop dfs -rmr out 删除指定文件从HDFS上
hadoop dfs -cat in/* 查看HDFS上in目录的内容
hadoop dfsadmin -report 查看HDFS的基本统计信息,结果如下
hadoop dfsadmin -safemode leave 退出安全模式
hadoop dfsadmin -safemode enter 进入安全模式
2、负载均衡
start-balancer.sh,可以使DataNode节点上选择策略重新平衡DataNode上的数据块的分布。
六.遇到的问题。
1) 执行jps时,找不到此命令。
答:这是由于jdk的环境没有配置好。

2)SSH无密码访问配置好之后,还是让输入密码?
答:文件权限问题。执行chmod 644 authorized_keys