GFS 是导致 HDFS 的问世的根本原因?
说起 HDFS 的由来,很多人都会提到是因为 Google 在大数据领域的三篇论文,也被称为 Google 的三驾马车。但我想更深层的原因,可能不单单是此,Google 作为互联网的超级巨头,其数据积累呈指数增长,这海量的数据已经触碰到单台服务器的硬盘容量的天花板了,迫使其进行存储改革,引入分布式存储机制去满足海量数据的存储需求。同样,除 Google 外的各大互联网公司也会很快遇到像 Google 一样的存储问题。所以,我认为对 Google 的 GFS 论文最合理的定位是催生了 HDFS,并不是很多人所认同的 “GFS 是 HDFS 问世的根本原因”!
HDFS 的设计目标
- 硬件失效
由于 HDFS 可能由成百上千的服务器所组成,我们不可能要求这么多的服务器都正常运行,所以在设计之初就考虑到硬件的异常是常态,比软件异常更加常见,HDFS 需要检测这些异常,并快速自动恢复数据。 - 流式数据访问
HDFS 存储的数据集作为离线计算框架 MapReduce(已很少使用)或者 Spark 的处理对象,其设计初衷就是希望数据集生成之后,不会对特定记录进行读取、修改或者删除。Spark 任务每次的分析都将用到该数据集的大部分数据甚至全部数据。因此读取整个数据集的时间延迟比读取某一条记录的时间延迟更为重要。所以流式数据访问更适合这种场景,同时,硬盘的物理构造特点也导致了其更适合流式读取。(流式读取最小化了硬盘的寻址开销,只需要寻址一次,就可以将单个文件块读下来,与流式数据访问对应的是随机数据访问,它要求定位、查询或者修改某条记录的延迟较小,比较适合数据集生成之后,频繁读写的情况) - 大规模数据集
运行在 HDFS 之上的 Spark 任务要处理很大规模的数据集,HDFS 上的典型文件大小为 GB 到 TB 级别。 - 数据一致性
“一次写入,多次读取”的数据读写模型,即一个文件经过创建、写入和关闭之后就不需要再改变。这一读写模型简化了数据的一致性问题,并且使得高吞吐量的数据访问成为可能。HDFS 计划要扩充一下这个模型,支持文件的附加写操作。 - 移动计算而不是移动数据
由于数据是海量的,计算程序一般很小,不算导入的各种包,了不起能到 20MB 左右,这时候将计算程序移动到存储数据的服务器上,就会比移动上 TB 的文件到存放计算程序的节点上划算的多,通过移动计算的方式可以显著减少网络的负载,降低网络拥塞。具体移动计算好还是移动数据好,可以通过下面的图对比一下:
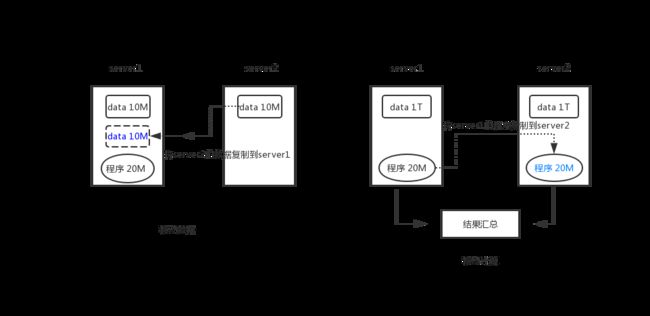
在数据量不大的时候,传统的方式往往是移动数据,将存放在 server2 上的数据移动到 server1,然后计算 20MB 数据集得到正确的结果。但是到了大数据时代,假设1Gb的带宽,实际传输速率大约在70MB/s ~ 80MB/s,那么传输 1TB 的数据需要4小时左右,很显然这种移动数据的方案就不可行了。采用移动计算的方式,只需要传输20MB的数据,为什么要移动计算我想大家都明白了吧!
- 多硬件平台间的可移植性
HDFS 是用 java 编写的,java 有良好的跨平台特性,那么 HDFS 自然也易于运行于各个硬件平台上,方便了推广。
HDFS 的架构原理
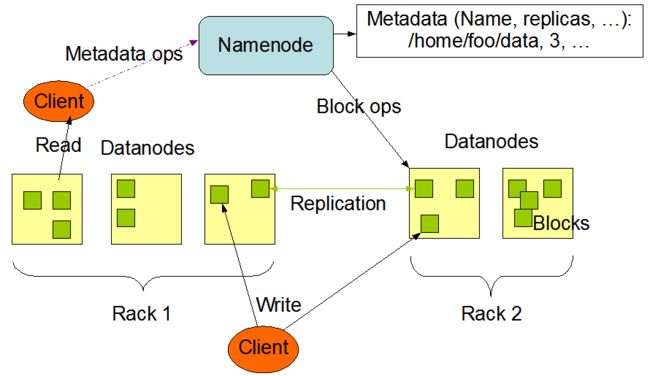
从上图中可以看出,一个典型的 HDFS 集群由一个 Namenode 节点和一定数量的 Datanodes 节点采用 master/slave 架构组成,Namenode 是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。一般是一个节点对应一个 Datanode,负责管理它所在节点上的存储。从内部看,一个文件被分成了一个或者多个数据块,这些块存储在不同的 Datanode 上。Datanode 负责处理文件系统客户端的读写请求,在 Namenode 的统一调度下进行数据块的创建、删除和复制。
1、通过客户端上传文件到 HDFS
- 我们通过命令
hadoop fs -put aiopen_test_.sh /tmp/hive/ainidata/test将客户端本地文件aiopen_test_.sh上传到 hdfs 文件系统/tmp/hive/ainidata/test目录下,客户端向 namenode 请求上传本地文件aiopen_test_.sh。 - namenode 首先检索元数据(Metadata)的目录树,查看当前的客户端用户是否具有操作待写目录的权限,之后再检查客户端想要上传的文件是否存在于 hdfs 中,如果存在,会拒绝客户端的上传,若不存在,则响应客户端的上传操作,以下图例演示了步骤1和2:

- 客户端收到可以上传的响应之后,会把待上传的文件
aiopen_test_.sh切成 block 块(hadoop 1.x 默认块大小为64MB;hadoop 2.x 默认块的大小为128MB),然后再次给 namenode 发送请求,上传第一个 block。(如果有多个 block的情况下) - namenode 收到客户端上传第一个 block 块的请求后,首先会检索其保存的 datanode 信息,确定要将该文件存储到哪些节点上,并响应给客户端一组 datanode 节点信息。
- 客户端收到 namenode 返回的一组 datanode 节点信息,找到离客户端最近的一台 datanode 建立网络连接;然后该 datanode 会与剩下的 datanode 建立传输通道,通道建立好之后会把确认信息返回到客户端,表示通道已经连接,客户端可以传输数据到选定的 datanode。
- 客户端收到确认信息之后,向选定的 datanode 传输第一个 block 的数据,该 datanode 收到数据后,首先会缓存下来,然后将缓存的数据一份写到硬盘,一份发送到传输通道,通过传输通道发送到其他的 datanode 。
- datanode 写完块之后,返回确认信息给客户端,第一个 block 写完。
- 如果还有 block 需要传输则需要从4开始,继续执行4-7,直到没有 block 需要传输为止。
- 写完整个文件,关闭传输通道,发送完成信息给 namenode。
2、从 HDFS 读文件到客户端
- 我们通过命令
hadoop fs -get /tmp/hive/ainidata/test .将 hdfs 文件系统/tmp/hive/ainidata/test目录复制到客户端当前目录.,客户端向 namenode 请求下载/tmp/hive/ainidata/test。 - namenode 检索元数据(Metadata)的目录树,获取到 block 的位置信息,将数据所在的 datanode 信息返回给客户端。
- 客户端根据得到的 datanode 信息,挑选一台距离最近的 datanode,向其发起下载文件的请求,若数据存储在多个 block 上,多个 block 又分散在不同的 datanode 上,则客户端分别向多个 datanode 发起下载文件的请求。
- datanode 响应客户端的请求,将数据返给客户端。
- 从多个 datanode 上获得的数据不断在客户端追加,形成完整的文件。
核心模块详解
1、Namenode 详解
从整个 HDFS 架构来看,Namenode 是最重要、最复杂的部分,Namenode 是整个 HDFS 集群的管理者,一旦 Namenode 出现故障,整个集群就不可用了。Namenode 大致分为两个主要管理模块,一个是 namespace,负责管理文件系统中得树状目录结构以及文件与数据块的映射关系;另一个是 blocksMap,负责管理文件系统中文件的物理块与实际存储位置的映射关系 BlocksMap。除了上述两个主要模块外,Namenode 还需要维护整个 HDFS 集群的机架信息(rack),Datanode 信息,Lease 管理以及缓存管理等。
namespace: 对于文件系统所有的对元数据的操作,namenode 都会用 Editlog 的事务日志记录下来,例如在 HDFS 中创建一个文件,或是修改文件的副本数都会在 Editlog 记录。另外数据块到文件的映射、文件的属性都会存储在Fsimage文件中,内存和硬盘上都会保存这两个文件,以便于重启 HDFS 之后,可以恢复服务。可以简单理解为:namespace = Editlog + Fsimage。
blocksMap: blocksMap 在 namenode 内存空间占据很大的比例。存储的是所有的 datanode 向 namenode 汇报的块的信息,这部分数据不会保存到硬盘,所以,当 namenode 重启之后,加载完 Fsimage 和 Editlog 之后,会监听所有 datanode 向 namenode 发送的块的信息报告,存储到 blocksMap。
安全模式:当 namenode 启动后会进入一个称为安全模式的特殊状态。 namenode 首先将 Fsimage 载入到内存,并执行编辑日志文件 Editlog 中的各项操作,一旦在内存中成功建立文件系统的元数据影像,则创建一个新的 Fsimage 和一个空的 Editlog。此时,namenode 开始监听 datanode 请求,整个过程期间,namenode 一直运行在安全模式。在安全模式下,各个 datanode 会向 namenode 发送最新的块的信息,当 namenode 接收到足够的块位置信息之后(可以配置的百分比参数,默认是99.9%的最小副本数)再加上30s的等待时间就会退出安全模式。
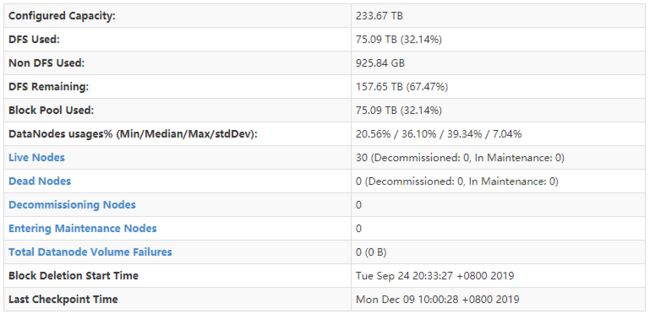

以上是30台节点的集群,TB级别数据量的 namenode 重启的步骤以及各个步骤所花费的时间。
2、Datanode 详解
Datanode 要比 Namenode 简单的多,是 HDFS 集群中存储真实文件数据的节点,并负责读/写文件操作。块(block)是 datanode 的最基本的存储单位,一个大文件(size > 128MB)在 datanode 是通过多副本(replication,默认是3个副本)的方式将多个 block 存储到不同的 datanode 节点上。当 datanode 启动的时候,datanode 需要将自身的一些信息发送给 namenode,namenode 经过检查后使其称为集群中的一员。然后 datanode 将节点上的 block 信息汇报给 namenode,namenode 将这些信息维护在 blocksMap 中,另外 datanode 需要每隔一段时间发送心跳包到 namenode。
心跳机制:在 HDFS 的主从架构中,master 与 slave 之间的通信是通过心跳机制,心跳是通过 RPC(remote procedure call,远程过程调用)实现的,由于整个过程是持续地按照一定的频率在运行,十分接近心脏的工作机制,所以我们将之称为“心跳机制”。当master启动的时候,会开启一个 RPC server,slave 启动时会连接 master,并每个三秒钟主动向 master 发送一个心跳包,将自己的状态信息告诉 master,master 通过心跳的返回值,向 slave 节点传达指令。
namenode 如何判断 datanode 是否失效?如果 datanode 在3s的时间间隔没有给 namenode 发送心跳,namenode 并不会直接认为 datanode 失效,而是给 datanode 10次机会,也就是30s的时间里,namenode 还是没有收到 datanode 的心跳,namenode 就暂时认为 datanode 失效。那么 namenode 就会每隔5min检查 datanode 发送是否发送了心跳包,如果检查2次依旧没有收到 datanode 的心跳包,那么 namenode 就会标记该 datanode 已经失效。注意一点,namenode 不会主动发起 RPC,而是响应来自 datanode 的 RPC 请求。所以,默认的超时时间为10min+30s,当然这个参数可以在 hdfs-default.xml 文件中自定义配置:
dfs.heartbeat.interval
3
Determines datanode heartbeat interval in seconds.
heartbeat.recheck.interval
300000
注意 dfs.heartbeat.interval 单位为秒,而 heartbeat.recheck.interval 单位为毫秒。
小文件实际磁盘占用:在大数据面试中,往往会被问到的一个问题是:“如果一个文件的大小 < block 的大小,那么实际占用的磁盘空间为多大?” 答案是实际文件的大小,而非一个块的大小。感兴趣的小伙伴可以自行做实验生成一些小文件存储到 HDFS 中检验一下文件的实际占用物理空间,这里不再赘述。由于 HDFS 的block 是一个逻辑概念而非物理存在,所以 hdfs 是支持修改块大小的:
dfs.block.size
134217728
扩展补充
1、Namenode 与 Secondary Namenode
上面我们已经提到,namenode 上保存着 hdfs 集群上的所有元数据信息,一旦 namenode 发生故障,整个集群将处于不可用的状态,因此对于 namenode 的容错十分重要,hadoop 为此提供了两种机制实现容错,第一种是将元数据保存在多块磁盘上,甚至可以将元数据存储到远程挂载的网络文件系统(NFS)。另一种是运行一个辅助 namenode,即 secondary namenode。secondary namenode 并不是作为 namenode 的热备份机,其任务是定期从 namenode 拉取 fsimage 和 editlog,合并两者形成新的 fsimage,将新的 fsimage 返回给 namenode。其详细步骤为:
- secondary namenode 通知 namenode 要 checkpoint,这个过程是定时(默认1小时)
fs.checkpoint.period或者是 namenode 上的 editlog 数量达到阈值(默认64MB)fs.checkpoint.size。 - secondary namenode 将 namenode 的 editlog 下载到本地磁盘上。(注意,secondary namenode 节点只有在启动后,第一次进行 checkpoint 时才会将 namenode 的 editlog 和 fsimage 都下载到本地,再进行合并。后期的 checkpoint 都只会下载 editlog 文件,而不会下载 fsimage,因为自己磁盘上保存的 fsimage 和 namenode 是一致的)
- secondary namenode 将 editlog 和 fsimage 加载到内存中,进行合并产生新的 fsimage。
- secondary namenode 将新的 fsimage 传回给 namenode,覆盖 namenode 上的旧的 fsimage 文件,并将其保存到本地磁盘上覆盖掉旧的 fsimage。
通过这种方式,一方面可以避免 namenode 上的 editlog 过大,另一方面将合并操作放到 secondary namenode 上可以节省 namenode 的cpu和内存,显著减少 namenode 的工作压力。但由于 secondary namenode 上保存的 fsimage 会滞后于 namenode 的内存中的元数据,所以在 namenode 故障后,想通过 secondary namenode 保存的 fsimage 重启集群,会导致部分数据丢失。但是如果结合第一种方案,用 NFS 中的元数据做合并可以确保数据不会丢失。
2、Namenode 的高可用(High Availability,HA)
通过 Secondary Namenode 并且将元数据保存到 NFS 中,可以防止数据的丢失,但是依然无法实现 namenode 的高可用。namenode 一旦失效,整个 HDFS 集群将无法提供服务,管理员通过冷启动的方式重启集群需要等待一段时间,参考上面提到的 namenode 重启步骤。针对此问题,hadoop 2.x 提出了 namenode 的 HA 解决方案:
- 给集群增加一个 Standby Namenode 节点,用于做 Namenode 的热备份机。此时,集群中有两台 namendoe 节点,活跃的被称为 Active Namenode。Active Namenode 响应请求,而 Standby Namenode 不提供服务,只是同步 Active Namenode 的元数据,在 Active Namenode 失效时,备胎转正,立马提供服务。
- Active Namenode 与 Standby Namenode 之间通过高可用的共享存储系统保持数据的一致,Active Namenode 将数据写入共享存储系统,Standby Namenode 一直监听共享存储系统,一旦数据发生改变就将其加载到自己的内存中。
- datanode 需要同时向 Active Namenode 和 Standby Namenode 发送心跳包和块的报告。
- 故障转移控制器(Failover Contraller,FC),监控 Active Namenode 和 Standby Namenode 的状态,并不断向 zookeeper 集群汇报心跳信息。
- 一旦发现 Active Namenode 失效,zookeeper 就会重新选举 Standby Namnode 作为新的领导者,FC 通知其转变为新的 Active Namenode。hadoop 刚启动时,两台 Namenode 都是 Standby Namenode,zookeeper 集群通过选举产生 Active Namenode。
3、多次格式化 namenode 导致集群启动不成功
HDFS 格式化会改变命名空间 id,当首次格式化 HDFS 的时候,会将 datanode 和 namenode 会产生一个相同的 namespaceID,但是,用命令 hadoop namenode -format 重新格式化时,namenode 的 namspaceID 改变了,但是 datanode 的 namespaceID 并未改变,导致 namespaceID 在 namenode 和 datanode 中并不一致,重新启动集群就会失败。解决方法,第一种是将集群中每个 datanode的 /hdfs/data/current 中的 version 删掉,然后执行 hadoop namenode -format 重启集群。另一种是用命令 hdfs namenode -format -force 进行强制的格式化,-force 会同时格式化 namenode 和 datanode。
4、HDFS 自身的局限性
- 不适合低延迟的数据访问 这是因为 HDFS 设计的初衷是面向大规模数据集的流式读写,而不是要求 HDFS 快速精确地定位到某条记录。如果精确定位某条记录需要将大规模数据读出来,再筛选出特定的某条记录,所以实时性不高,但是 HBase 是可以支持数据的随机读写,实时性很高,比较适合低延迟的数据访问场景。
- 无法高效存储大量小文件 由于 HDFS 的 namenode 节点将所有文件的元数据保存在内存中,如果小文件太多,会导致元数据索引结构过于庞大,检索会很慢,导致整个 HDFS 集群效率低下。
- 不支持多用户写入以及任意修改文件