配置环境:
ubuntu 14.0.4 +hadoop.2.7.1
1.设置用户sudo权限
chmod u+w /etc/sudoers
vim /etc/sudoers
在root ALL=(ALL) ALL添加
cms(这是我的用户名根据实际情况填写) ALL=(ALL) ALL
chmod u-w /etc/sudoers
2.设置静态IP
systems settings---network----wired---options
弹出框,选择ipv4 settings
地址为192.168.31.131(注意ip地址、网关、DNS等与自动方式的ip一致)

3.安装jdk
4.配置另外两台机器
虚拟机--管理--克隆
选择(虚拟机中的当前状态--创建连接克隆)
设置静态ip,分别为192.168.31.132,192.168.31.133
5.集群环境配置
1)修改当前机器名称
修改三台机器里文件/etc/hostname里的值即可,修改成功后用hostname命令查看当前主机名是否设置成功。
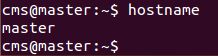
一定要将图中该行注释掉,否则最后通过命令hdfs dfsadmin -report
查看 DataNode 是否正常启动时 Live datanodes 为 0 (个人在这个坑里捣鼓了好久)

2)配置hosts文件
在所有机器
/etc/hosts文件后面加
192.168.31.131 Master
192.168.31.132 Slave1
192.168.31.133 Slave2
ping 测试

配置ssh免登录
1)三台机器安装ssh
2)Master机器利用ssh-keygen命令生成一个无密码密钥对。
在Master机器上执行以下命令:
ssh-keygen –t rsa
生成的密钥对:id_rsa(私钥)和id_rsa.pub(公钥),默认存储在/home/用户名/.ssh目录下。

查看"/home/用户名/"下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。
3)接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
查看是否成功

4)将公钥复制到slave1和slave2
在master上执行
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2```
并且ssh slave1等测试。
####hadoop配置文件(路径hadoop.2.7.1/etc/hadoop)(在master上配置)
#####安装hadoop
1.在官网上下载hadoop-2.7.1.tar.gz
2.解压:```tar -zxvf hadoop-2.7.1.tar.gz```
3.配置环境变量
打开/etc/profile
添加(连同java的环境变量,一起给出):

```soure /etc/profile``` 让配置文件立即执行
####修改配置文件
这里我只把我的实例贴出来,经供参考,更多详细配置请参照官方文档
1.hadoop-env.sh
该文件是 hadoop运行基本环境的配置,需要修改的为 java虚拟机的位置。
故在该文件中修改 JAVA_HOME值为本机安装位置
The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
2.core-site.xml
3.hdfs-site.xml
```
dfs.replication
2
dfs.datanode.data.dir
file:///opt/hadoop/datanode
#该namenode属性在复制到slave中去时应删除
dfs.namenode.name.dir
file:///opt/hadoop/namenode
#该namenode属性在复制到slave中去时应删除
dfs.namenode.secondary.http-address
master:9001
#该namenode属性在复制到slave中去时应删除
dfs.webhdfs.enabled
true
4.mapred-site.xml
这个是mapreduce 任务的配置,由于 hadoop2.x使用了yarn 框架,所以要实现分布式部署,必须在 mapreduce.framework.name属性下配置为yarn。
版本中/etc/hadoop/ 中找不到 mapred-site.xml文件,默认情况下,/hadoop-2。7.1/etc/hadoop/文件夹下有 mapred.xml.template文件
复制并重命名
cp mapred-site.xml.template mapred-site.xml
编辑器打开此新建文件
vi mapred-site.xml
然后编辑mapred-site.xml
mapreduce.framework.name
yarn
Execution framework set to Hadoop YARN.
mapreduce.jobhistory.address
master:10020
MapReduce JobHistory Server host:port, default port is 10020
mapreduce.jobhistory.webapp.address
master:19888
MapReduce JobHistory Server Web UI host:port, default port is 19888.
jobhistory是 Hadoop自带了一个历史服务器,用于记录 Mapreduce历史作业。默认情况下, jobhistory没有启动,可用手动通过命令启动,如下所示:
Shell代码
``jobhistory-daemon.sh start historyserver```
5.yarn-site.xml
该文件为yarn 框架的配置
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address master:8088
6.slaves
该文件里面保存所有slave节点的信息,hdfs
写入以下内容(hosts里从机的主机名):
Slave1
Slave2
7.向节点服务器slave1、slave2复制我们刚刚在master服务器上配置好的hadoop
scp -r hadoop-2.7.1 slave1
scp -r hadoop-2.7.1 slave2
配置slave1、slave2
1)配置环境变量,/etc/profile 与上面master配置一致
2)删除hdfs-site中的多余属性(在前面已标注)
启动hadoop
在每次namenod之前,最好
在三个机器/opt下 先删除临时文件 hadoop
然后新建 hadoop/
修改权限:
chown -R cms hadoop
避免
hadoop namenode -format 失败
1)执行hadoop namenode -format
出现

则成功格式化HDFS
如果不成功,执行上述删除临时文件夹等步骤再格式化
2)在master上启动集群
start-dfs.sh
start-yarn.sh
3)用jps检验各后台进程是否成功启动
master

slave1

slave2

缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令
hdfs dfsadmin -report
查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有2 个 Datanodes:

master:8088能显示你的集群状态
master: 50070能进行一些节点的管理
#######向hadoop集群系统提交第一个mapreduce任务
1)hadoop fs -mkdir /tmp 在虚拟分布式文件系统上创建一个测试目录tmp
2)hadoop fs -put 1.txt /tmp/1.txt
将当前目录下的带有任意单词的文件复制到虚拟分布式文件系统中
例如,我的文件
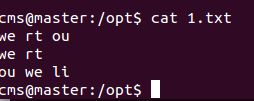
3)hadoop fs -ls /tmp查看文件系统中是否存在我们所复制的文件

4)复制hadoop安装目录下的mapreduce example 的jar 包到/opt目录下
cp /hadoop-2.7.1/share/mapreduce/hadoop-mapreduce-examples-2.7.1.jar /opt
5)运行单词计数mapreduce任务
hadoop jar /opt/hadoop-mapreduce-examples-2.7.1.jar wordcount /tmp/1.txt /tmp/1_out

4)查看任务输出
li 1
ou 2
rt 2
we 3```
至此,集群搭建成功