文章来源:http://blog.seclibs.com/nginx...
Nginx程序架构图如下

后面就先按照这个图所展示出来的内容对Nginx的架构进行一次梳理,文中所涉及到的内容,主要都是针对Linux系统的。
最上面的Master进程是管理员直接控制的,也只有Master进行接受管理员信号,一个Master用户可以fork多个Worker进程,一个Worker进程可以响应多个用户请求。
- Master进程负责加载配置文件,启动worker进程和平滑升级。
- Worker进程处理并响应用户的请求。
每个Worker都是由核心模块core和多个模块modules组成的,比如有http协议的ht_core模块,为了功能完善还有很多其它模块,如实现负载均衡的ht_upstream模块,ht_proxy反代模块,ht_fastcgi模块,memcache模块等。
因为Nginx是高度模块化的,我们在用到哪个模块的时候,便将哪个模块编译或者载入就可以了,比如基于ht_core可以与web通信, 基于ht_fastcgi模块可与php通信,基于memcache模块可与mamcache通信。
这里来解释一下什么是FastCGI,CGI全称”通用网关接口”(Common Gateway Interface),用于HTTP服务器与其它机器上的程序服务通信交流的一种工具,CGI程序须运行在网络服务器上;但是由于CGI的性能和安全性都比较差,处理高并发几乎是不可用的,所以就诞生了FastCGI,FastCGI是一个可伸缩地、高速地在HTTP服务器和动态脚本语言间通信的接口(FastCGI接口在Linux下是socket(可以是文件socket,也可以是ip socket)),主要优点是把动态语言和HTTP服务器分离开来。多数流行的HTTP服务器都支持FastCGI,包括Apache、Nginx和lightpd,同时它也被许多脚本语言所支持,包括PHP等。
Nginx不支持对外部动态程序的直接调用或者解析,所有的外部程序(包括PHP)必须通过FastCGI接口来调用。FastCGI接口在Linux下是socket(可以是文件socket,也可以是ip socket)。为了调用CGI程序,还需要一个FastCGI的wrapper,这个wrapper绑定在某个固定socket上,如端口或者文件socket。当Nginx将CGI请求发送给这个socket的时候,通过FastCGI接口,wrapper接收到请求,然后派生出一个新的线程,这个线程调用解释器或者外部程序处理脚本并读取返回数据;接着,wrapper再将返回的数据通过FastCGI接口,沿着固定的socket传递给Nginx;最后,Nginx将返回的数据发送给客户端,这就是Nginx+FastCGI的整个运作过程。
FastCGI的主要优点是把动态语言和HTTP服务器分离开来,是Nginx专一处理静态请求和向后转发动态请求,而PHP/PHP-FPM服务器专一解析PHP动态请求。
说完Nginx+FastCGI后,继续说前面的模块,memcache是一个分布式的高速缓存系统,常用来做缓存服务器、将从数据库查询的数据缓存起来,减少数据库查询、加快查询速度。
然后说图中用户与Nginx交互的部分,在与用户请求进行交互的时候,通过kevent、epoll和select来实现多路复用,实现处理并发用户请求,这里是因为Nginx采用的是多进程(单线程)的模式,采用多进程可以提高并发效率,并且各进程之间相互独立,一个Worker进程挂掉之后不会影响其他进程的运行。
到这里为止上面图中上半部分就说完了,主要就是nginx与用户和后端程序之间的关系,此外Nginx还提供了缓存机制,支持高级I/O机制、sendfile机制、AIO机制(异步非阻塞I/O)、mmap机制等。
我们先来说sendfile机制,在网上查到的所有资料里都提到sendfile机制可以提高文件传输的性能。在传统的文件传输中,使用的是read/write方式来进行文件与socket的传输,所需要经过的流程是这样的
- 调用read函数,文件数据被copy到内核缓冲区
- read函数返回,文件数据从内核缓冲区copy到用户缓冲区
- write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
- 数据从socket缓冲区copy到相关协议引擎。
总结一下就是硬盘—>内核buf—>用户buf—>socket相关缓冲区—>协议引擎,用一张图来表示,就是这个样子的

而在引入sendfile机制以后,数据的流程变为了这样
- sendfile系统调用,文件数据被copy至内核缓冲区
- 再从内核缓冲区copy至内核中socket相关的缓冲区
- 最后再socket相关的缓冲区copy到协议引擎
可以发现,引入sendfile机制以后,省去了拷贝到用户buf的过程,流程就变成了下图的样子

nginx在支持了sendfile系统调用后,避免了内核层与用户层的上线文切换(content swith)工作,大大减少了系统性能的开销。
前面说了这么多,都没有绕开内核缓冲区和用户缓冲区,那它们分别又是什么东西?
这里首先先区分一下缓冲区buffer和缓存cache是两个完全不同的东西,buffer是减少调用次数,集中调用,提高系统性能的,而cache是将读取过的数据保留下来,如果重新读取的时候发现已经读取过,就不需要再去读硬盘数据了。
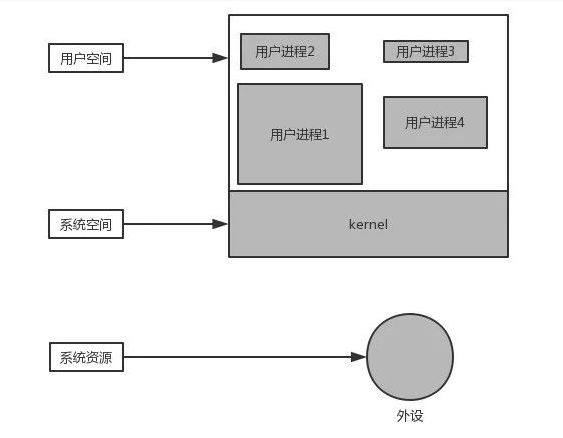
上图是一个计算机系统运行时的简化模型,在说用户进程和系统进程之前还需要再说一下内核态(kernel mode)和用户态(user mode),内核态可以访问系统资源,比如CPU、IO设备、进程管理、内存、进程间通信IPC、网络通信等,这些资源在用户进程中是不能直接访问的,需要经过操作系统才可以,这些有操作系统提供的功能也叫做系统调用。
下图是用户通过shell来对文件进行操作的示例图,它们都是经过内核来进行操作的,而提供这些限制的基础就是CPU提供的内核态和用户态。

前面说了用户进程在访问系统资源的时候,需要先切换到内核态,在这之前有很多的堆栈、内存环境等需要提前准备好,在调用结束以后,必须恢复到用户态,这其中的堆栈等又必须回到用户进程的上下文,这其中的切换就会消耗大量的资源。所以用户缓冲区就是在读取文件的时候申请的一块内存空间,也就是buffer,然后程序都是从buffer中获取数据的,只有在内存空间使用完后才会进行下一次调用来填充buffer,这样就减少了系统调用的次数,减少了在用户态和内核态之间切换的消耗时间。
当然内核也有它自己的缓冲区,在用户进程要从磁盘读取数据的时候,内核一般不会去读磁盘,而是将内核缓冲区中的数据复制给用户进程缓冲区,如果内核缓冲区没有数据的话,内核会将请求加入到请求队列中,然后将进程挂起,去处理其他的进程,直到内核缓冲区读取到数据以后,才会将内核缓冲区中的数据复制给用户进程缓冲区,然后通知进程,当然不同的io模型,在调度方式上也是有一些差异的;所以内核缓冲区就在OS级别,提高了磁盘的IO效率。
到这里sendfile机制也就说完了,接着用刚刚讲的内核和用户进程的知识来说一下AIO机制(异步非阻塞I/O),我们先来看阻塞,先上图,看一下阻塞和非阻塞的区别


在两个图的对比当中,可以看到,在阻塞IO中,如果数据没有准备好你就只能等着,直到数据准备好以后才可以再继续执行,这对于Nginx的Worker来说明显是很不适用的,而非阻塞的IO,当数据没有准备好时,我可以返回先去做其他的事情,过一会再来问一下,如果没有准备好,我再去处理其他的事情,直到你准备好,我过来开始拷贝数据,在这期间明显可以处理很多的事情,对于大量访问的时候也是非常好的,但是这样还有一个问题,虽然非阻塞,但是每隔一段时间就需要请求一下,也是非常浪费资源的,所以也就有了异步,也就是提供一种机制(select/poll/epoll/kquene这样的系统调用),让你可以同时监控多个事件,调用他们是阻塞的,但是可以设置超时时间,在超时时间之内,如果有事件准备好了就返回。
这样对于大量的并发就非常的友好了,这里的并发请求,是指未处理完的请求,线程只有一个,同时处理的请求只有一个,只是在请求间不断切换,切换是因为异步事件未准备好,主动让出的。这里的切换没有什么代价,可以理解为在循环处理多个准备好的事件;与多线程相比,不需创建线程,每个请求占用的内存也很少,没有上下文切换,事件处理非常轻量级,没有上下文切换的开销,更多并发,只会占更多的内存,这也是现在的网络服务器基本都使用的方式。
最后还有一个mmap机制,mmap机制也就是内存映射,传统的web服务器进行页面输入的时候,都是将硬盘的页面先输入到内核缓冲区,再有内核缓冲区复制一份到web服务器上,mmap机制就是让内核缓冲区与磁盘进行映射,web服务器直接复制页面内容即可,省去了从硬盘复制到内核缓冲区这一过程。
上面就是把Nginx所涉及到的功能都说了一遍,从整体角度来看Nginx的功能是这样的。
我们启动Nginx的时候首先会启动一个Master进程,Master进程会根据配置文件的要求fork相应个数的Worker进程(推荐设置worker数与cpu的核数一致,因为更多的worker,会导致进程竞争cpu资源,从而带来不必要的上下文切换,设置为auto即为与cpu一致),当Worker进程接收客户端请求时,如果使用缓存功能,会从缓存中加载数据直接返回给客户端,如果客户端请求的内容内存中没有,就会将请求代理到后端服务器取资源,如果后端服务器是HTTP就使用http模块,如果是php就是用FastCGI模块,然后取出数据后又会将数据在本地缓存下来以提高性能,缓存时基于key-value结构,检索性能时O(1)恒定不变,把key缓存在内存中,检索起来也是非常迅速的。
在Worker接受请求这里还有一些操作,这里来补充一下。
在Nginx启动后,Master进程fork出的多个Worker进程,Master能监控Worker进程的运行状态,如果有Worker异常退出后,会自动启动新的Worker进程,在Nginx0.8之前,我们是直接给Master进程发信号的,在重启或者重新加载配置的时候,Master进程在接收到信号之后,会先重新加载配置文件,然后再启动新的Worker进程,并向所有老的Worker进程发送不再接受新请求的信号,并且在处理完所有未处理完的请求后退出,新的Worker在启动后,就开始接受新的请求了;在Nginx0.8之后,我们不会直接对Master发送信号了,比如在执行./nginx -s reload的时候,会启动一个新的Nginx进程,该进程解析到reload参数后,知道要重新加载配置文件,它就会向Master进程发送信号,之后的处理与之前直接给Master进程发信号一样了。
还有一点就是所谓的“惊群现象”,在启动后,Master进程首先通过socket()来创建一个sock文件描述符来监听,然后fork出的Worker进程会继承父进程Master的socket文件描述符sockfd,之后Worker进程accept()后将创建已连接描述符(connected descriptor),然后通过已连接描述符来与客户端通信,由于每一个Worker进程都拥有Master的sockfd,那当链接进来的时候,所有的Worker都会收到通知,并且争着去建立链接,这就是“惊群现象”,这时大量的进程被激活又挂起,只有一个进程可以accept()到这个连接,就消耗了大量的系统资源。在Nginx中提供了一个accept_mutex的东西,这是在accept上加了一把共享锁,即每个Worker进程在执行accept之前都需要先获取锁,获取不到就放弃执行accept(),只有有了这把锁才会去accept(),同一时刻就只有一个Worker进程去接收请求了,这样就不会出现惊群问题了。
但是我在查资料的时候发现了另外一个情况
在对启动了20个worker的nginx进行压力测试的时候发现:如果把配置文件中event配置块中的accept_mutex开关打开(1.11.3版本之前默认开),就会出现worker压力不均,少量的worker的cpu利用率达到了98%,大部分的worker的压力只有1%左右;如果把accept_mutex关掉,所有的worker的压力差别就不大,而且QPS会有大幅提升;引用自博客园-sxhlinux
根据他的测试,在请求属于大量短链接的时候,打开accept_mutex选项是一个比较好的选择,避免了Worker争夺资源而造成的上下文切换以及try_lock的锁的开销,但是对于传输大量数据的TCP长链接来说,打开accept_mutex将会导致压力集中在某个Worker进程上,特别是将worker_connection值设置过大的时候,影响更加明显,具体的设置,需要根据实际情况来进行判定。而且目前新版的Linux内核中增加了EPOLLEXCLUSIVE选项,nginx从1.11.3版本之后也增加了对NGX_EXCLUSIVE_EVENT选项的支持,这样就可以避免多worker的epoll出现的惊群效应,从此之后accept_mutex从默认的on变成了默认off。
很明显所有的文件配置都与具体的实际情况有关,要更好的配置好相关内容必须对所有的内容都要有一个详细的了解才可以。
参考文档
Zero Copy I: User-Mode Perspective
文章首发公众号和个人博客
公众号:无心的梦呓(wuxinmengyi)
