什么是半监督学习呢,我们都知道有监督学习是数据都有特征和标签,而半监督的数据除了R部分有标签的,还有U部分无标签但是有特征的。半监督学习也分为transductive learning和inductive learning,前者是训练时已知测试数据的学习,而后者是训练好后,拿去训练未知的测试集

我们假设要做猫狗的分类,我们可以根据不同颜色,直接选择边界来分类

假设我们多了一些未标记的灰色点,形成新的分布,我们可能就会考虑新的边界

半监督学习往往伴随着假设,灰色的点也可能是个狗不过背景比较像,所以学习有没有用常常取决于假设合不合理

我们会讲半监督学习用于生成模型,还要讲2种假设方法,最后提到有一种更好的陈述,但这个要放到无监督学习那里讲

我们回顾下有监督学习,我们判别样本x属于C1,C2时,通过假设高斯分布,同一个协方差,我们可以求出x属于C1的概率,而且可以找到一个合适的边界

而半监督学习实际样本的和有标签样本得到的可能不一样,所以我们需要无标签的样本帮助我们重新估计优先概率prior,还有均值,方差,从而生成新的边界

半监督学习我们可以通过已有标签的数据先计算出参数,里面分别是2个优先概率,2个均值,和方差,我们第一步呢就是先根据model得出参数下,取出无标签的样本,是C1的概率,第二步就是更新模型,优先概率考虑无标签的样本可能性,均值同理考虑了样本*概率求和后一般化
更新模型后把参数进一步迭代,理论上会得到收敛,但是初始带标签的样本会影响到最终结果

我们做监督学习时可以衡量有标签的数据的可能性,当有无标签的部分数据(半监督学习)时,我们就增加了无标签项出现的概率的log项,这个无标签项既可能来自C1也可能来自C2,我们想让其最大化,但是这个数据是不可导的,只能通过一次次迭代收敛

我们机器学习的一种假设就是分割处的密度是比较低的,也就是一种‘非黑即白’的描述,下图2种边界在训练集都100%准确率,但是考虑到测试集,我们可能左侧的分类效果会好一点

我们基于这种假设可以采用self-training的方法,利用带标签的数据训练(逻辑回归,神经网络,决策树等)出模型,将一组无标签的数据带入,得到新的标签,将新标签数据和无标签数据结合到一起,得到训练新的模型,如此反复,问题常常是我们怎么去选择这么一组数据。
老师问到,如果模型是用线性回归,那我们去这么做有意义吗,其实是没用的,因为新产生的模型不变

self-trainning和之前讲的generative model很类似,区别在于前者的标签是hard label即我们非黑即白,离谁近就是谁,后者是软标签,还有概率成分,如果我们训练参数是0.7,0.3,硬标签会将其置为0,1,而软标签对其没有变化= =,相当于没起作用

上面的进阶型基于熵的正则,我们根据参数可以得到无标签的输出概率,我们按低密度分割考虑,同类里分布应该是比较密集的,左下3种分布前2种比较密集,第三种就比较平均(不好),我们就考虑引入熵的公式,将3种情况带入可以得到,前2个的熵是0,第三个最大是ln5,所以一般这个熵越小越好,
所以我们的损失函数加上了无标签部分的熵的正则项,来决定是根据样本数据多一点还是考虑将熵减少(分类更明显)多一点

我们还没有讲SVM,这里先简介下,比如我们有一组数据,下图做,4个未标记,我们做SVM就是找到一个边界,是间隔最大同时最小错误率,我们对未标签的做假设,有其中几种可能如右,我们可以分别作出他的SVM,最后从中选出分类边距最大的,就选择方框中的,有人会说我们如果有M个未标签数据,岂不是要做个假设,其实我们实际做SVM,都是改一笔data的label看假设是否使边界变大,如果变大就采用假设

我们的第二种假设就是近朱者赤近墨者黑

我们有人就会说如果特征x接近,那么他们就有相同的y,其实这是不准确的。
准确的说应该是x分布不均匀的,如果x1,x2较相近且在一个高密度的区域里,那么他们的标签就相同,就如图中的x1,x2,看x特征好像x2,x3比较近,但实际上x1,x2在一簇里,而x3在另一簇
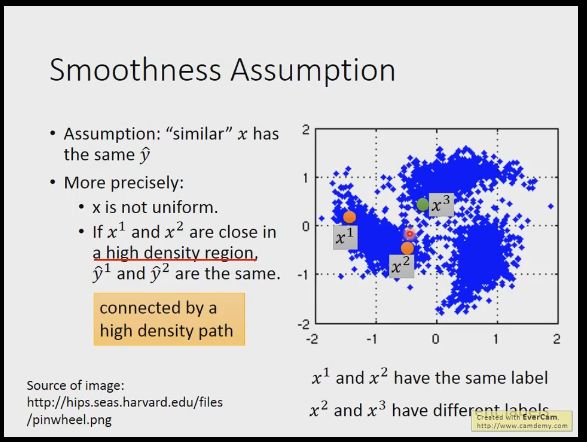
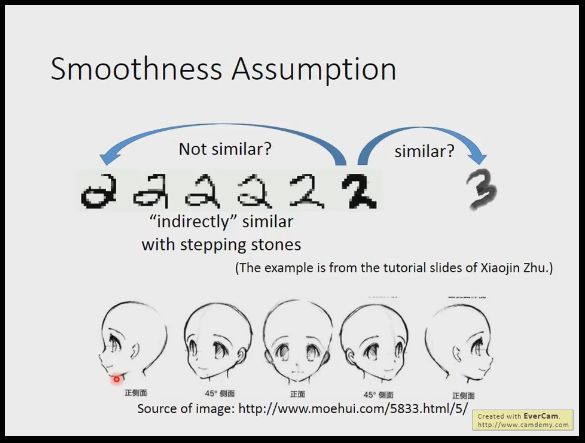
我们举几个例子,比如我们手写数字,2个2,一个带一个包围的弯,一个没有,可能后边的2反而和3比较像,但是看大部分没标签的数据,我们会发现这2个2其实是通过很多个过渡的2连接在一起,但是2和3虽然比之前的2接近,但是他们之间并没有过渡的数据。
又比如左侧人脸和右侧人脸,从图片数据上可能另一个左侧人脸和图片左侧人脸都比较接近,但是当引入过渡数据(不同角度的人脸后)就会发现其实他们是1类
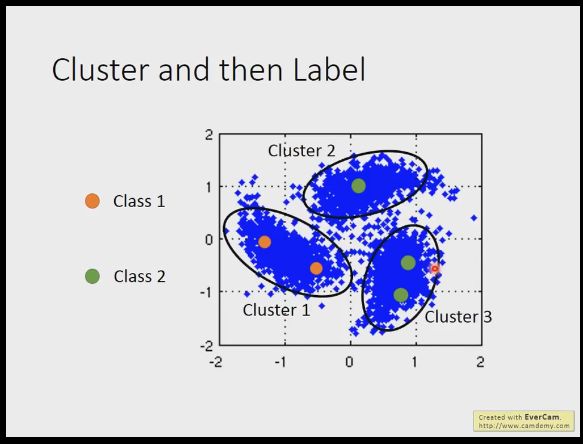
我们可以用聚类后打标签的方法,比如聚类后分成了3类,每类里都已经包含部分带标签的,就定义这类都是以包括范围内最多的带标签的标签(这有时候不准确,不如self-learning)
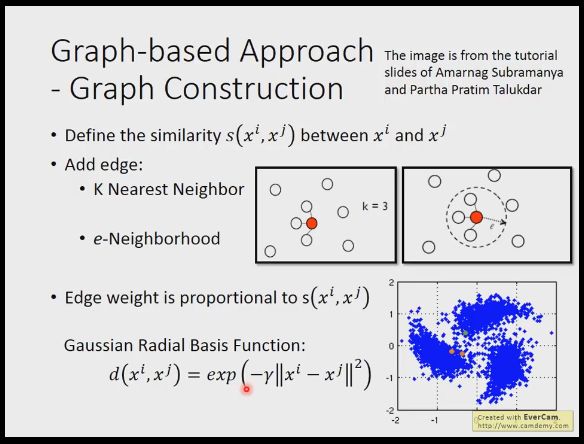
我们另一种方法是基于图像的接近法,比如我们找到几个数据的相互联系,然后就能把他们连起来,最后如果2个数据能通过图连起来,那他们就是一个类。如何将图连起来呢,比如我们找网页间的关系,他们有超链接引用,或者论文间相互引用,而有的时候你就需要镜子去建立这种关系图

我们基于图的假设都有哪些做法呢,一般是定义一个相似度函数,比如我们定义KNN,找K个最近的连在一起,或者en,找到半径e内的连在一起,还有一种是算相似度函数跟距离的平方得e次幂的倒数,两个一旦距离远就相似度下降很快,所以只有很近的才能连接到一起
我们找到距离Class1比较近的点,根据连接就认为连接的点是Class1,而这种方式是会传递扩散的,但是如果数据量不够的话,可能有些过渡点就没有连接上

我们先看下图下面2组分布,已知x2,x3分类是1,x4是0,我们假设x1是1,0就得到2种情况,我们会认为左侧的比较smooth,我们就需要定义一个函数来评定平滑程度,对所有的数据(不管是否有标签),两两计算权重乘以预测结果(有标签为真实结果)之间的平方再求和,这个函数越小证明越平滑
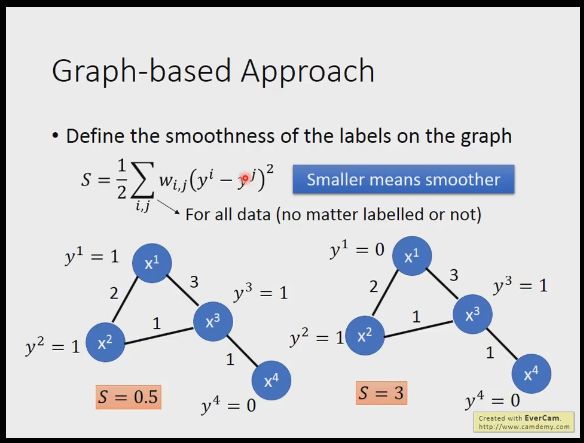
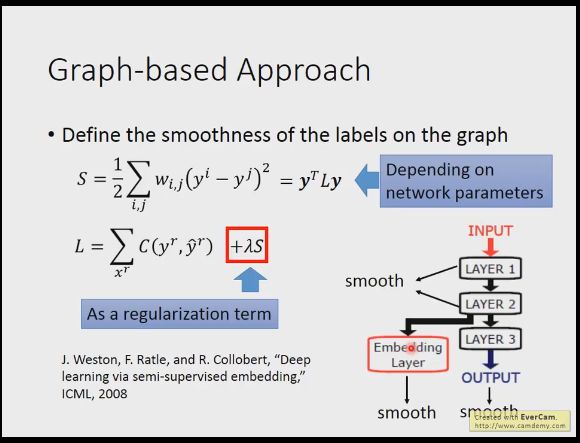
我们具体怎么做呢,我们可以将y定义为R+U维度的向量,那么s就可以写成上式,这个矩阵L=D-W,其中W是两两间的权重值(自身和自身,未连接的部分都为0),D是W每一行作和然后放到对角线的位置上,这个是可以证明的,不过证明起来比较无聊

我们的平滑函数是根据网络上的参数决定的,我们定义损失函数可以加上平滑函数的正则项,看是考虑已有标签多一点还是平滑程度多一点,我们考虑平滑程度不光可以在output层观察,可以在前几层layer就要去平滑
我们最后一个方法是better representation,方法具体会在无监督学习讲,精髓是去芜存菁,化繁为简

简单介绍下,我们分类时候其实有很多潜藏的因素在观察里,如果我们找到这些潜藏的因素往往就能得到很好的效果,图例是杨过(神雕侠侣)剪樊一翁打的胡子,观察到他的胡子是随头而动,所以观察点也很重要
