简介
Python是近年来用于数据处理、数据分析和网站构建等各种任务的最常用语言之一。在处理这些任务的过程中,有许多任务依赖于操作系统。Python允许开发人员通过Python中的os模块使用多个依赖于操作系统的功能。这个包抽象了平台的功能,并提供了相关python函数来导航、创建、删除和修改文件和文件夹。在本教程中,你将了解如何导入这个包、它的基本功能以及使用这个库执行数据合并任务的python示例项目。
基本函数
我们通过一些实例代码来学习一下这个模块。
导入库:
我们来获取本模块可以使用的方法列表:
输出:

现在,使用getcwd方法我们可以获取当前工作目录路径。
输出:
列出文件夹和文件
我们使用 listdir 来列出当前目录的文件夹/文件:
输出:
如你所看到的,我有两个文件夹: Data 和 Population_Data ,三个文件:README.mdmarkdown 文件, 以及两个名为 tutorial.py 和 tutorial_v2.py的Python文件。
为了获取我的项目文件夹的树形结构,我们来写一个函数,使用 os.walk() 来迭代当前目录下每个文件夹中的所有文件。
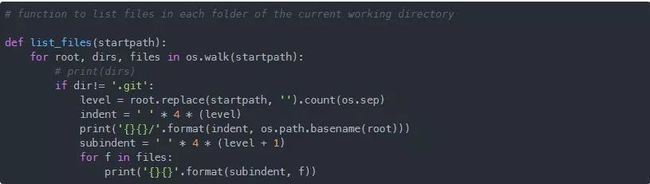
在当前工作路径中调用这个函数,当前路径可以通过之前学习的函数得到:
输出:
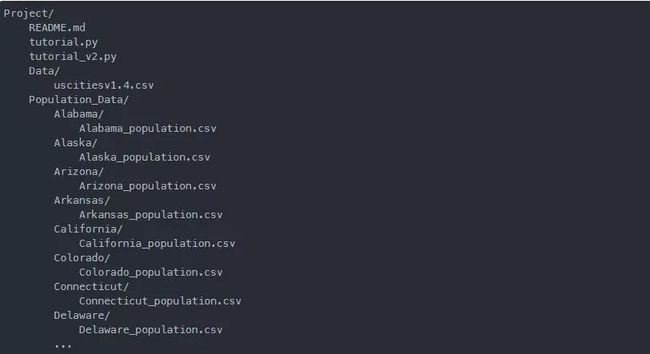
备注:为方便起见,只截取输出一部分。
从输出中可以看到,文件夹的名称以一个 / 结尾,文件夹中的文件向右缩进了四个空格。Data 文件夹中有一个名为 uscitiesv1.4.csv的csv文件。这个文件包含了美国每个城市的人口数据。Population_Data文件夹保存所有州的数据,其中包含从uscitiesv1.4.csv中提取的每个州的人口数据的独立csv文件。
改变工作目录
我们来改变工作目录,进入到包含 “New York”州数据的目录。
现在,我们在这个目录中再次运行 list_files方法。
输出:
如你所见,我们进入了 Population_Data文件夹下的 New York文件夹。
创建单个和嵌套目录结构
现在,我们在这个目录中创建一个名为 testdir的新目录。
输出:

如你所见,它在当前工作目录中创建了一个新目录。
我们来创建一个两层嵌套的目录。
输出:

我们得到一个错误。具体来说,我们得到一个 FileNotFoundError 错误。你可能想知道,当我们试图创建目录时,为什么会产生一个 FileNotFound 错误。
原因:Python模块寻找一个名为 level1dir 的目录来创建 level2dir 目录。因为 level1dir 不存在,所以它首先抛出一个 FileNotFoundError错误。
对于这样的目的,我们可以使用 mkdirs() 函数来代替,它可以递归地创建多个目录。
查看当前目录树。
输出:

可以看到,现在在 New York 文件夹下有两个子目录:testdir 和 level1dir。level1dir下面有一个名为level2dir 的目录。
递归删除单个和多层目录
os 模块也有修改或删除目录的方法,我将在这里演示。
现在,让我们来使用 rmdir 删除刚才创建的目录:
查看当前目录树来确认此目录已经不存在:
输出:

你可以看到,testdir目录已经被删除。
我们来尝试删除嵌套目录树 level1dir 和 level2dir。
输出:

正如所见,这里抛出了一个 OSError,这是正确的。它提示 level1dir 目录不是空的。这是正确的,因为它下面有 level2dir。
使用 rmdir 方法不可能删除非空目录,类似于Unix命令行版本。
就像 makedirs() 方法一样,我们试一下 rmdirs(),它可以递归地删除树结构中的目录。
我们再来看一下树结构:
输出:
它返回前一个目录的状态。
数据处理实例
到目前为止,我们已经研究了如何查看、创建和删除嵌套目录结构。现在我们来看一个 os 模块如何帮助数据处理的例子。
为此,我们在目录结构中向上一层。
这一步操作之后,我们再来查看一下目录树结构。
输出:
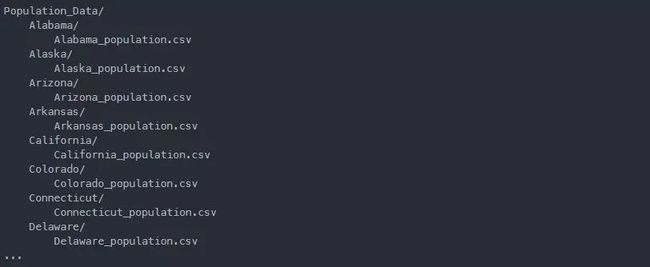
备注:为了简便起见,只截取输出一部分。
我们通过遍历每个州的目录并合并CSV文件来合并所有州的数据。
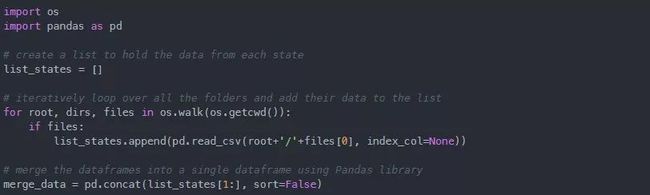
由于 os 模块的部分原因,我们能够创建 merge_data,这是一个包含来自每个州的人口数据的数据帧。
结论
在本文中,我们简要地探讨了Python内置 os 模块的不同功能。我们还看到了一个简单的例子,说明如何在数据科学和分析领域中使用该模块。很重要的一点是,要了解 os还提供了很多的功能,并且可以根据开发人员的需要构建更复杂的逻辑。