为企业设计数据库时,主要目标是正确的表示数据、数据之间的联系以及与企业业务相关的数据约束。为了实现这个目标,我们可以使用一种或多种数据库设计技术。前面讲了实体 - 联系(ER)建模。下面将讲述另一种数据库设计技术——规范化。
规范化 是一种数据库设计技术,从分析属性之间的联系(即函数依赖)入手。属性刻画了企业重要数据的特性或者这些数据之间联系的特性。规范化使用一系列测试(描述为范式)帮助我们确定这些属性的最佳组合,最终生成可支持企业数据需求的一组适当关系。
本篇主要目标是介绍函数依赖的概念,并且讨论如何将关系规范化到第三范式。下一篇还将给出函数依赖的形式化描述以及比 3NF 更高的范式。
1. 规范化的目的
规范化(normalization):生成一组既具有所期望的特性又能满足企业数据需求的关系的技术。
进行规范化的目的是确定一组合适的关系以支持企业的数据需求。所谓合适的关系,应具有如下性质:
- 属性的个数最少,且这些属性是支持企业的数据需求所必需的。
- 具有紧密逻辑联系(描述为 函数依赖)的诸属性均在同一关系中。
- 最少 的冗余,即每个属性仅出现一次,作为外部关键字的属性除外。连接相关关系必须用到外部关键字。
数据库拥有一组合适的关系的好处是:数据库易于用户访问,数据易于维护,在计算机上占有较小的存储空间。而使用未能被适当规范化的关系带来的问题详见第 3 小节。
2. 规范化对数据库设计的支持
规范化是一种能够应用于数据库设计任何阶段的形式化技术。这里着重强调规范化的两种使用方法。方法 1 将规范化视为一种自下而上的独立的数据库设计技术。方法 2 则将规范化作为一种确认技术使用:用规范化技术检验关系的结构,而这些关系的建立可能采用自上而下的方法,比如 ER 建模。不管使用哪一种方法,目标都是一致的,即建立一组设计良好(well-designed)的关系以满足企业的数据需求。
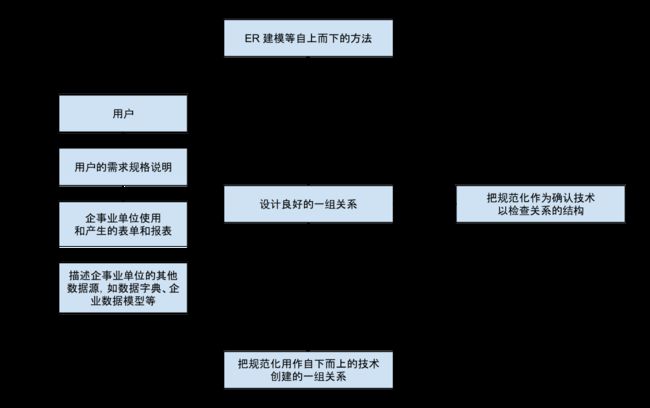
上图给出了一些能够用来进行数据库设计的数据源示例。尽管用户的需求规格说明书是首选的数据源,但是仅基于直接从其他数据源获得的信息进行数据库设计也是可能的,这些数据源包括表单和报表。上图还说明对同一个数据源两种方法均适用。然而尽管理论上如此,实际操作时究竟采用哪一种方法还要取决于数据源反映出的数据库的大小、范围以及复杂度,同时还取决于数据库设计者的偏好及其专长。是否将规范化作为一种自上而下的独立的数据库设计技术(即方法 1)使用,常常受限于数据库设计者对设计细节的掌握程度。然而,当我们将规范化作为一种确认技术(即方法 2)使用时,就没有了这种限制。因为在这种使用方法中,数据库设计者在任何时刻都能专注于数据库的一部分,例如一个单一的关系,因此,不管数据库的大小或者复杂度如何,规范化都能发挥效能。
3. 数据冗余与更新异常
如上所述,关系数据库设计的一个主要目标就是将属性组合成关系时力求最少的数据冗余。如果能够达到这个目标,就可能为数据库带来以下好处:
能用最少的操作完成对数据库中存储数据的更新,由此可以降低数据库中出现数据不一致的概率。
减少存储基本关系所需的文件存储空间,因而将成本降低至最低。
当然,关系数据库(的运行)也依赖于一定的数据冗余的存在。这种冗余一般是以主关键字(或者候选关键字)的多个副本的形式出现,这些副本在与之相关联的关系(即主关键字或候选关键字所述的关系)中,做为外部关键字出现,用以表示数据之间的联系。
举例说明:
关系 StaffBranch 是关系 Staff 和 关系 Branch 的另一种表达方式,这些关系的结构如下所示:
Staff (staffNo, sName, position, salary, branchNo)
Branch (branchNo, bAddress)
StaffBranch (staffNo, sName, position, salary, branchNo, bAddress)
注意,每个关系的主关键字都有下划线。
在关系 StaffBranch 中存在冗余数据:同一个分公司的信息在每一个属于该分公司的员工信息里反复出现。相反,在关系 Branch 中,每个分公司的信息只出现了一次,而且在关系 Staff 中只有分公司的编号(branchNo)这一属性的值重复出现,这是为了能够表示出每一个员工都归属于哪一个分公司。存在冗余数据的关系可能存在一些问题——更新异常,更新异常又可分为插入异常、删除异常和修改异常。关系 Staff 关系 Branch 和关系 StaffBranch表如下所示。
Staff:
| staffNo | sName | position | salary | branchNo |
|---|---|---|---|---|
| SL21 | John White | Manager | 30000 | B005 |
| SG37 | Ann Beech | Assistant | 12000 | B003 |
| SG14 | David Ford | Supervisor | 18000 | B003 |
| SA9 | Mary Howe | Assistant | 9000 | B007 |
| SG5 | Susan Brand | Manager | 24000 | B003 |
| SL41 | Julie Lee | Assistant | 9000 | B005 |
Branch:
| branchNo | bAddress |
|---|---|
| B003 | 163 Main St, Glasgow |
| B007 | 16 Argyll St, Aberdeen |
| B005 | 22 Deer Rd, London |
StaffBranch:
| staffNo | sName | position | salary | branchNo | bAddress |
|---|---|---|---|---|---|
| SL21 | John White | Manager | 30000 | B005 | 22 Deer Rd, London |
| SG37 | Ann Beech | Assistant | 12000 | B003 | 163 Main St, Glasgow |
| SG14 | David Ford | Supervisor | 18000 | B003 | 163 Main St, Glasgow |
| SA9 | Mary Howe | Assistant | 9000 | B007 | 16 Argyll St, Aberdeen |
| SG5 | Susan Brand | Manager | 24000 | B003 | 163 Main St, Glasgow |
| SL41 | Julie Lee | Assistant | 9000 | B005 | 22 Deer Rd, London |
3.1 插入异常
插入异常主要有两类,我们用上表中的关系 StaffBranch 来解释这两类异常。
在关系 StaffBranch 中插入一位新员工的信息时,这些信息中必须包括该员工将被分配到分公司的信息。比如,在插入某一被分配到编号为 B007 的分公司工作的员工信息时,我们必须正确输入分公司 B007 的所有信息,由此确保这些数据与关系 StaffBranch 已有的关于分公司 B007 的元组中的信息一致。而 Staff 和 Branch 关系则不存在这种潜在的不一致性,因为在关系 Staff 中,秩序为每个员工录入相应的分公司编号就可以了,而在关系 Branch 中,编号为 B007 的分公司的信息是作为一个单独的元组存储在数据库中的。
在向关系 StaffBranch 中插入一个新的分公司的信息时,由于该分公司目前可能还没有给员工,因此有必要在录入与员工相关的信息时将其设为 NULL,如将 staffNo 赋值为 NULL。但是 staffNo 是关系 StaffBranch 的主关键字,若试图为 staffNo 录入 NULL 值,则会违反实体完整性约束,这样做是不允许的,我们也因此无法向关系 StaffBranch 中插入一个 staffNo 为 NULL的一个新的分公司的元组。Staff 和 Branch 的关系设计则避免了这类问题的出现,因为分公司的信息在关系 Branch 中单独录入,与员工信息分离,而员工被分配到哪个分公司工作的信息则会在以后的时间再录入关系 Staff 中。
3.2 删除异常
从关系 StaffBranch 中删除一个元组时,若该元组表示某分公司最后一名员工,则删除元组之后,该分公司的信息也从数据库中丢失了。例如,如果从关系 StaffBranch 中删除员工编号为 SA9 的元组,则编号为 B007 的分公司的信息也将从数据库中消失。同样的,Staff 和 Branch 的分开设计避免了这个问题。
3.3 修改异常
如果我们想要修改关系 StaffBranch 中某分公司的某个属性值,比如修改分公司 B003 的地址,那么我们必需更新所有 B003 的员工的元组。若如此修改操作未能在关系 StaffBranch 中所有相关的元组上执行,数据库则会产生不一致:同属分公司 B003 的员工,其元组在分公司地址这一属性上的取值可能会有不同。
上面的示例说明了 Staff 和 Branch 的分开设计比 StaffBranch 的设计具有更令人满意的特性。也就是说,当关系 StaffBranch 发生更新异常时,我们可以通过将其分解为 Staff 和 Branch 两个关系来避免这些异常。当把较大的关系分解成较小的关系时,有两个很重要的特性:
无损连接(lossless-join):该特性确保了缘关系的任意实例信息能通过较小关系的对应实例确定出来。
依赖保持(dependency preservation):该特性确保了只需简单的在较小的关系上支持某些约束,就可以继续支持在原关系上存在的约束。也就是说,我们不必对较小的关系执行连接操作就可以检验他们是否违反了原关系上的约束。
4. 函数依赖
与规范化相关的一个重要概念就是 函数依赖,函数依赖描述了属性之间的联系(Maier,1983)。
4.1 函数依赖的特征
为了讨论函数依赖,假设有某一关系模式,该关系模式具有属性(A,B,C, ... ,Z),我们用一个 全域关系(universal relation)R = (A,B,C,...,Z)来描述数据库。该假设意味着每个数据库中的属性都有一个唯一的名字。
函数依赖(functional dependency):描述一个关系中属性之间的联系。例如,假设 A 和 B 均为关系 R 的属性,若 A 的每个值都和 B 中一个唯一的值相对应,则称 B 函数依赖于 A,记为 A → B(A,B可能由一个或多个属性组成)。
函数依赖是属性在关系中的一种语义特性。该语义特性表明了属性和属性是如何关联起来的,确定了属性之间的函数依赖。当存在某一函数依赖时,这个以来就被视为属性之间的一种 约束。
考虑某一关系,它拥有属性 A、B,其中属性 B 函数依赖于属性 A。假设知道 A 的值,我们来验证该关系是否支持这种依赖。结果我们发现无论任何时候,对于所有元组,若属性 A 的值等于给定值,则该元组的属性 B 的值都是唯一的。因此,当两个元组的属性 A 的值相同时,其属性 B 的值也是相同的。反之则不然,对于一个给定的 B 的值,可能对应着几个不同的 A 的值。属性 A、B 之间这种以来可以用下图表示。

另外一种描述属性 A、B 之间的这种联系的术语为 “A 函数决定 B”。也许一些读者更喜欢使用后者,因为它与属性之间的函数依赖的箭头的方向相同,显得更自然一些。
决定方:位于函数依赖箭头左边的属性或属性组。
当存在函数依赖时,位于箭头左边的属性或属性组称为 决定方(determinant) 。例如,上图中,A 是 B 的决定方。
在确定一个关系中属性间的函数依赖时,必须明确它是仅当属性取某一特定值时成立,还是该属性取值集中任意值时均成立,区分清楚这一点很重要。换句话说,函数依赖是关系模式(内涵)的性质,而不是模式的某个实例(外延)的性质。
另一个规范化时有用的函数依赖的性质是:决定方应该具有最少的属性,这些属性是保证右边的属性函数依赖于它所必不可少的。我们称其为 完全函数依赖。
完全函数依赖(full functional dependency):假设 A 和 B 是某一关系的属性(组),若 B 函数依赖于 A,但不函数依赖于 A 的任一真子集,则称 B 完全函数依赖于 A。
对于函数依赖 A → B,如果去掉 A 中的任一属性都使得该依赖不再成立,那么 A → B 就是完全函数依赖。如果去掉 A 中的某些属性,依赖仍然成立,那么函数依赖 A → B 就是 部分函数依赖。
概括而言,规范化时要用到的函数依赖具有下列性质:
- 函数依赖左边的属性(组)(即决定方)与右边的属性(组)是一对一的联系(注意,若反过来看,也就是右边与左边的属性(组)之间则既可能为一对一的联系,也可能为一对多的联系)。
- 恒成立。
- 决定方具有最少的、足以支持与右边的属性(组)之间依赖关系的属性,即右边的属性(组)完全依赖于左边的属性(组)。
至此,我们已经讨论了在规范化时所关心的一些函数依赖,但是还有必要了解一种函数依赖,即 传递依赖(transitive dependency)。因为关系中若存在传递依赖,就有可能引起更新异常。本节只简单介绍传递依赖,目的是在需要时我们能够识别出他们。
传递依赖:假设 A、B、C 是某一关系的属性,若 A → B,B → C,则称 C 通过 B 传递依赖于 A(假设 A 并不函数依赖于 B 或 C)。
4.2 识别函数依赖
如果我们能够完全理解每一个属性的意义以及这些属性之间的联系,那么确定属性之间所有的函数依赖应该非常简单。这类信息应由企业提供,可能是通过与用户讨论形成,同时(或者)也可能是以文档的形式出现,比如用户需求规格说明书。但是,如果与用户无法沟通,并且(或者)文档并不完备,那么数据库设计人员就有必要基于该数据库应用的领域,利用自己的常识或经验来补充那些缺失的信息。
4.3 利用函数依赖确定主关键字
确定关系函数依赖集的主要目的是确定该关系必须满足的完整性约束集。首先要考虑辨别的一种重要的完整性约束是候选关键字,候选关键字中的一个将被选作关系的主关键字。
5. 规范化过程
规范化是一种基于关系的主关键字(或者候选关键字)和函数依赖对关系进行分析的形式化技术(Codd,1972b)。规范化技术涉及一系列的规则,这些规则能够用来对关系进行单独测试以保证数据库可以被规范化到任意程度。当某种规范化的要求未能得到满足时,就将违反需求的关系分解为多个关系,直至分解后的每一个关系都能满足规范化的要求为止。
最早提出的三个范式为第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。后来,R.Boyce 和 E.F.Codd 又提出了一种增强的第三范式,称为 Boyce-Codd 范式(BCNF)(Codd,1974)。除了第一范式,所有这些范式都是基于关系的属性之间的函数依赖的(Maier,1983)。随后还提出了比 BCNF 更高层的范式——第四范式(4NF)和第五范式(5NF)(Fagin,1977, 1979)。但是,需要用到第四范式、第五范式的情况相当少。本篇中将只讲述前三种范式,对 BCNF、4NF 和 5NF 的讨论则留到下一章进行。
规范化的过程包括一系列步骤,每一步都对应着某种具有已知性质的特定范式。随着规范化的进行,关系的个数逐渐增多,关系的形式也逐渐受限(结构越来越好),也就越来越不容易出现更新异常。对于关系数据模型,应该认识到在建立关系时只有满足第一范式(1NF)的要求是必须的,后面的其他范式都是可选的,这一点很重要。但是为了避免出现前面讨论过的更新异常的情况,通常建议将规范化至少进行到第三范式(3NF)。从第一范式到第五范式是是逐步递进的,第二范式是在满足第一范式的基础上增加条件形成的,以此类推。
下图为规范化过程的纵览图,途中突出显示了规范化过程中每一个步骤的主要操作。
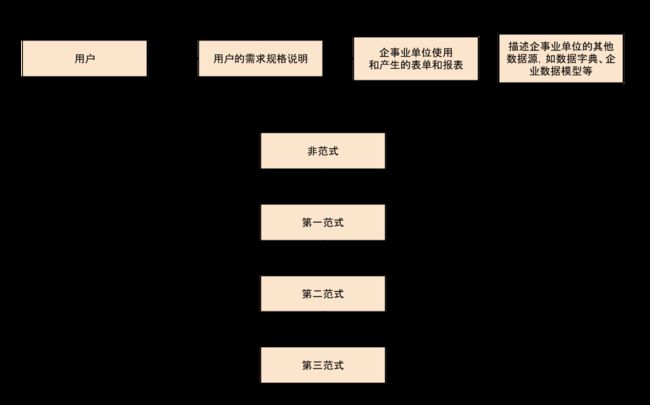
这里我们将规范化视为一种自下而上的技术,主要讲述如何利用这种技术从案例表单中抽取属性信息,并先将其转化为非范式(Unnormalized Form,UNF)表格的形式,然后将其逐渐分解以满足每一种范式的要求,分解一直进行到原案例表中的属性都被分解为若干满足 3NF 要求的关系为止。尽管这里使用的例子都是从某一范式规范化到更高一级的范式,但是,对于其他的例子来说并不一定必须这么做。在解决某些特殊问题时,我们可以将 1NF 的关系转换为 2NF 的关系,或者在某些情况下,直接将其转化为 3NF 的关系。
为了简化对规范化的讲述,我们假设在所用案例中,每一个关系都有一个函数依赖集,每一个关系都已被指派了一个主关键字。也就是说,在规范化的过程开始之前,充分、完全地理解属性的意义及其之间的联系是必要的。这些信息是进行规范化的基础,我们将利用这些信息来验证一个关系是否已经满足了指定范式的要求。
6. 第一范式(1NF)
非范式(UNF):包含一个或多个重复组的表。
第一范式(1NF):属于第一范式的关系,其每一行和每一列相交的位置有且仅有一个值。
我们开始进行规范化之前,首先要将数据从数据源(例如标准的数据输入表单)转换为包含行和列的表格形式。这种格式的表是非范式的,因而被视为 非规范化的表(unnormalized table)。为了将非规范化的表转化为第一范式,我们需要确定并删除表中的重复组。一个重复组可以是一个属性或一组属性,它对应表的某个(些)关键属性的一个实例可能出现多个值。注意,这里所说的 “关键属性” 是指非规范化的表中那些可以唯一标识每一行的属性(组)。从非规范化的表中消除重复组的常用方法有两种:
在含有重复数据的那些行的空白列上输入合适的数据,也就是在需要填充的位置复制非重复数据。这种方法通常被看做是对表的平板化(flattening)处理。
将重复数据单独移到一个新的关系中,同时也将原来关系中的关键属性(组)复制到这个新的关系中。有时候,非规范化的表可能包含多个重复组,或者在重复组里又有重复组。在这些情况下,重复使用这一方法直到不再存在重复组位置。若结果关系均不含重复组,则他们都是 1NF 的。
这两种方法得到的结果关系都是 1NF 的关系,在行、列交叉处都只包含原子(或单一)值。尽管两种方法都是正确的,然而方法 1 在对原 UNF 的表进行平板化的过程中也引入了较多的冗余;方法 2 则创建了两个或更多的关系,这些关系的冗余度都低于原 UNF 的表的冗余度。换句话说,在对原 UNF 的表的规范化过程中,方法 2 比方法 1 做的工作更多。但是,不管从哪一种方法开始,原 UNF 的表终将被规范化为一组相同的 3NF 的关系。
7. 第二范式(2NF)
第二范式基于完全函数依赖的概念,第二范式适用于具有合成关键字的关系,即主关键字有两个或两个以上的属性构成。主关键字仅包含一个属性的关系已经至少是 2NF 的。不是 2NF 的关系可能会出现前面讨论过的更新异常。
第二范式 (2NF):满足第一范式的要求并且每个非主关键字属性都完全函数依赖与主关键字的关系。
将 1NF 的关系规范化为 2NF 关系需要消除部分依赖。如果存在部分依赖,就要将部分依赖的属性从原关系移出,移到一个新的关系中去,同时将这些属性的决定方也复制到新的关系中。
8. 第三范式(3NF)
尽管 2NF 的关系比 1NF 关系的数据冗余度低,但是仍然存在更新异常问题。此时的更新异常是由依赖传递引起的,我们需要消除这种依赖,继续将关系规范化到第三范式。
第三范式(3NF):满足第一范式和第二范式的要求并且所有非主关键字属性都不传递依赖于主关键字的关系。
将 2NF 的关系规范化为 3NF 需要消除传递依赖。如果存在传递依赖,就将传递依赖的属性(组)移到一个新的关系中,并将这些属性的决定方也复制到该关系中。
9. 2NF 和 3NF 的一般化定义
在前两节的 2NF 和 3NF 的定义中,不允许存在对主关键字的部分依赖和传递依赖,以此避免出现前述的更新异常现象。然而,这些定义并没有考虑关系中的其他候选关键字(如果存在不止一个候选关键字)。下面将在考虑关系的所有候选关键字的基础上,给出 2NF 和 3NF 的更一般化定义。注意,考虑关系的候选关键字并不会影响 1NF 的定义,因为 1NF 与关键字和函数依赖无关。在更一般化的定义中,我们规定:属于任何一个候选关键字的属性都叫做主属性(candidate-key attribute);提到部分依赖、完全依赖和传递依赖时不仅仅是基于主关键字,而是基于所有的候选关键字。
第二范式(2NF):满足第一范式的要求并且每个非主属性都完全函数依赖于任何一个候选关键字的关系。
第三范式(3NF):满足第一范式和第二范式的要求并且没有一个非主属性传递依赖于任何一个候选关键字。
在使用 2NF 和 3NF 的一般化定义时,必须注意的是所有候选关键字上的部分依赖和传递依赖,而不只是主关键字上的。这使得规范化过程变得更加复杂,但一般化定义能为关系增加附加约束,从而有可能发现关系中隐藏的、被遗漏的冗余。
在进行规范化时,是仅简单的分析主关键字上的依赖,还是使用一般化定义进行规范化,这需要权衡。前者使得规范化过程简单,并且可以发现关系中存在的大多数问题和明显的数据冗余;后者则有更多的机会发现关系中被遗漏的冗余。实际上, 常见的情形是,无论使用基于主关键字的定义还是使用 2NF、3NF 的一般化定义,对关系进行分解的结果相同。