由于51cto的编辑不太好用,这是有道上的文档http://note.youdao.com/noteshare?id=aedd53c99b4a97aebbe9af136104113a
在 MongoDB 中,有两种数据冗余方式,一种 是 Master-Slave 模式(主从复制),一种是 Replica Sets 模式(副本集)。
三种集群:1、 主从集群(目前已经不推荐使用)
2、 副本集
3、 分片集群
分片集群是三种模式中最复杂的一种,副本集其实一种互为主从的关系,可理解为主主。
副本集指将数据复制,多份保存,不同服务器保存同一份数据,在出现故障时自动切换。对应的是数据冗余、备份、镜像、读写分离、高可用性等关键词;
而分片则指为处理大量数据,将数据分开存储,不同服务器保存不同的数据,它们的数据总和即为整个数据集。追求的是高性能。
在生产环境中,通常是这两种技术结合使用,分片+副本集。
下面的内容将介绍mongodb副本集、分片集群、拆分gridfs上传的文件、利用nginx-gridfs结合mongodb分片集群,并且在浏览器显示拆分的文件,四大类。
第1章 Mongodb副本集集群介绍
1.1 简介
为什么介绍副本集,因为在3.6版本后,分片集群搭建和副本集一起使用。
副本集实现了mongodb集群的高可用。
副本集是一种在多台机器同步数据的进程,副本集体提供了数据冗余,扩展了数据可用性。在多台服务器保存数据可以避免因为一台服务器导致的数据丢失。
也可以从硬件故障或服务中断解脱出来,利用额外的数据副本,可以从一台机器致力于灾难恢复或者备份。
在一些场景,可以使用副本集来扩展读性能,客户端有能力发送读写操作给不同的服务器。也可以在不同的数据中心获取不同的副本来扩展分布式应用的能力。
mongodb副本集是一组拥有相同数据的mongodb实例,主mongodb接受所有的写操作,所有的其他实例可以接受主实例的操作以保持数据同步。
主实例接受客户的写操作,副本集只能有一个主实例,因为为了维持数据一致性,只有一个实例可写,主实例的日志保存在oplog。
1.2 原理
MongoDB 的副本集不同于以往的主从模式。
在集群Master故障的时候,副本集可以自动投票,选举出新的Master,并引导其余的Slave服务器连接新的Master,而这个过程对于应用是透明的。可以说MongoDB的副本集是自带故障转移功能的主从复制。
相对于传统主从模式的优势
传统的主从模式,需要手工指定集群中的 Master。如果 Master 发生故障,一般都是人工介入,指定新的 Master。 这个过程对于应用一般不是透明的,往往伴随着应用重
新修改配置文件,重启应用服务器等。而 MongoDB 副本集,集群中的任何节点都可能成为 Master 节点。一旦 Master 节点故障,则会在其余节点中选举出一个新的 Master 节点。 并引导剩余节点连接到新的 Master 节点。这个过程对于应用是透明的。
一个副本集即为服务于同一数据集的多个MongoDB实例,其中一个为主节点,其余的都为从节点。主节点上能够完成读写操作,从节点仅能用于读操作。主节点需要记录所有改变数据库状态的操作,这些记录保存在oplog中,这个文件存储在local数据库,各个从节点通过此oplog来复制数据并应用于本地,保持本地的数据与主节点的一致。oplog具有幂等性,即无论执行几次其结果一致,这个比mysql的二进制日志更好用。集群中的各节点还会通过传递心跳信息来检测各自的健康状况。
当主节点故障时,多个从节点会触发一次新的选举操作,并选举其中的一个成为新的主节点(通常谁的优先级更高,谁就是新的主节点),心跳信息默认每2秒传递一次。客户端连接到副本集后,不关心具体哪一台机器是否挂掉。主服务器负责整个副本集的读写,副本集定期同步数据备份。一旦主节点挂掉,副本节点就会选举一个新的主服务器。这一切对于应用服务器不需要关心。

副本集中的副本节点在主节点挂掉后通过心跳机制检测到后,就会在集群内发起主节点的选举机制,自动选举出一位新的主服务器。
1.3 节点
副本集拥有三种节点:主节点、从节点、仲裁节点
1)主节点负责处理客户端请求,读、写数据, 记录在其上所有操作的oplog;
2)从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。默认情况下,从节点不支持外部读取,但可以设置;副本集的机制在于主节点出现故障的时候,余下的节点会选举出一个新的主节点,从而保证系统可以正常运行。
3)仲裁节点不复制数据,仅参与投票。由于它没有访问的压力,比较空闲,因此不容易出故障。由于副本集出现故障的时候,存活的节点必须大于副本集节点总数的一半,否则无法选举主节点,或者主节点会自动降级为从节点,整个副本集变为只读。因此,增加一个不容易出故障的仲裁节点,可以增加有效选票,降低整个副本集不可用的风险。仲裁节点可多于一个。也就是说只参与投票,不接收复制的数据,也不能成为活跃节点。
注意:
官方推荐MongoDB副本节点最少为3台,建议副本集成员为奇数,最多12个副本节点,最多7个节点参与选举。限制副本节点的数量,主要是因为一个集群中过多的副本节点,增加了复制的成本,反而拖累了集群的整体性能。太多的副本节点参与选举,也会增加选举的时间。而官方建议奇数的节点,是为了避免脑裂 的发生。
1.4 工作流程
在MongoDB副本集中,主节点负责处理客户端的读写请求,备份节点则负责映射主节点的数据。备份节点的工作原理过程可以大致描述为,备份节点定期轮询主节点上的数据操作,从而保证跟主节点的数据同步。至于主节点上的所有数据库状态改变的操作,都会存放在一张特定的系统表中。备份节点则是根据这些数据进行自己的数据更新。
1.4.1 Oplog
上面提到的数据库状态改变的操作,称为 oplog(operationlog,主节点操作记录。oplog 存储在local数据库的"oplog.rs"表中。副本集中备份节点异步的从主节点同步oplog,然后重新执行它记录的操作,以此达到了数据同步的作用。
关于 oplog 有几个注意的地方:
1)oplog 只记录改变数据库状态的操作
2)存储在oplog 中的操作并不是和主节点执行的操作完全一样,例如"$inc"操作就会转化为"$set"操作
3)oplog 存储在固定集合中(capped collection),当oplog的数量超过oplogSize,新的操作就会覆盖旧的操作
1.4.2 数据同步
在副本集中,有两种数据同步的方式:
1)initial sync(初始化):这个过程发生在当副本集中创建一个新的数据库或其中某个节点刚从宕机中恢复,或者向副本集中添加新的成员的时候,默认的,副本集中的节点会从离它最近的节点复制oplog来同步数据,这个最近的节点可以是primary也可以是拥有最新oplog副本的 secondary节点。该操作一般会重新初始化备份节点,开销较大。
2)replication(复制):在初始化后这个操作会一直持续的进行着,以保持各个secondary节点之间的数据同步。
当遇到无法同步的问题时,只能使用以下两种方式进行initial sync了
1)第一种方式就是停止该节点,然后删除目录中的文件,重新启动该节点。这样,这个节点就会执行 initial sync
注意:通过这种方式,sync的时间是根据数据量大小的,如果数据量过大,sync时间就会很长同时会有很多网络传输,可能会影响其他节点的工作
2)第二种方式,停止该节点,然后删除目录中的文件,找一个比较新的节点,然后把该节点目录中的文件拷贝到要 sync 的节点目录中
1.5 副本集选举过程
Mongodb副本集选举采用的是Bully算法,这是一种协调者(主节点)竞选算法,主要思想是集群的每个成员都可以声明它是主节点并通知其他节点。别的节点可以选择接受这个声称或是拒绝并进入主节点竞争,被其他所有节点接受的节点才能成为主节点。
节点按照一些属性来判断谁应该胜出,这个属性可以是一个静态ID,也可以是更新的度量像最近一次事务ID(最新的节点会胜出)
1.5.1 副本集的选举过程
1)得到每个服务器节点的最后操作时间戳。每个 mongodb 都有 oplog 机制会记录本机的操作,方便和主服 务器进行对比数据是否同步还可以用于错误恢复。
2)如果集群中大部分服务器 down 机了,保留活着的节点都为 secondary 状态并停止,不选举了。
3)如果集群中选举出来的主节点或者所有从节点最后一次同步时间看起来很旧了,停止选举等待人来操作。
4)如果上面都没有问题就选择最后操作时间戳最新(保证数据是最新的)的服务器节点作为主节点。
1.5.2 副本集选举的特点
选举还有个前提条件,参与选举的节点数量必须大于副本集总节点数量的一半(建议副本集成员为奇数。最多12个副本节点,最多7个节点参与选举)如果已经小于一半了所有节点保持只读状态。集合中的成员一定要有大部分成员(即超过一半数量)是保持正常在线状态,3个成员的副本集,需要至少2个从属节点是正常状态。
如果一个从属节点挂掉,那么当主节点down掉 产生故障切换时,由于副本集中只有一个节点是正常的,少于一半,则选举失败。
4个成员的副本集,则需要3个成员是正常状态(先关闭一个从属节点,然后再关闭主节点,产生故障切换,此时副本集中只有2个节点正常,则无法成功选举出新主节点)。
1.6 MongoDB 同步延迟问题
当你的用户抱怨修改过的信息不改变,删除掉的数据还在显示,你掐指一算,估计是数据库主从不同步。与其他提供数据同步的数据库一样,MongoDB 也会遇到同步延迟的问题,在MongoDB的Replica Sets模式中,同步延迟也经常是困扰使用者的一个大问题。
1.6.1 什么是同步延迟
首先,要出现同步延迟,必然是在有数据同步的场合,在 MongoDB 中,有两种数据冗余方式,一种是Master-Slave 模式,一种是Replica Sets模式。这两个模式本质上都是在一个节点上执行写操作, 另外的节点将主节点上的写操作同步到自己这边再进行执行。在MongoDB中,所有写操作都会产生 oplog,oplog是每修改一条数据都会生成一条,如果你采用一个批量 update 命令更新了 N 多条数据, 那么,oplog会有很多条,而不是一条。所以同步延迟就是写操作在主节点上执行完后,从节点还没有把 oplog拿过来再执行一次。而这个写操作的量越大,主节点与从节点的差别也就越大,同步延迟也就越大了。
1.6.2 同步延迟带来的问题
首先,同步操作通常有两个效果,一是读写分离,将读操作放到从节点上来执行,从而减少主节点的 压力。对于大多数场景来说,读多写少是基本特性,所以这一点是很有用的。
另一个作用是数据备份, 同一个写操作除了在主节点执行之外,在从节点上也同样执行,这样我们就有多份同样的数据,一旦 主节点的数据因为各种天灾人祸无法恢复的时候,我们至少还有从节点可以依赖。但是主从延迟问题 可能会对上面两个效果都产生不好的影响。
如果主从延迟过大,主节点上会有很多数据更改没有同步到从节点上。这时候如果主节点故障,就有 两种情况:
1)主节点故障并且无法恢复,如果应用上又无法忍受这部分数据的丢失,我们就得想各种办法将这部 数据更改找回来,再写入到从节点中去。可以想象,即使是有可能,那这也绝对是一件非常恶心的活。
2)主节点能够恢复,但是需要花的时间比较长,这种情况如果应用能忍受,我们可以直接让从节点提 供服务,只是对用户来说,有一段时间的数据丢失了,而如果应用不能接受数据的不一致,那么就只能下线整个业务,等主节点恢复后再提供服务了。
如果你只有一个从节点,当主从延迟过大时,由于主节点只保存最近的一部分 oplog,可能会导致从 节点青黄不接,不得不进行 resync 操作,全量从主节点同步数据。
带来的问题是:当从节点全量同步的时候,实际只有主节点保存了完整的数据,这时候如果主节点故障,很可能全部数据都丢掉了。
1.7 副本集搭建过程
1.7.1 环境准备
Centos7 64位系统
Mongodb 4.0版本
三台虚拟机
192.168.1.182:27017
192.168.1.186:27017
192.168.1.122:27017安装包(三台一样)
下载地址
https://www.mongodb.com/download-center?jmp=nav#community
https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-4.0.2.tgz解压到/usr/local/mongodb/目录下
1.7.2 搭建过程
1、 创建数据目录(三台创建)mkdir /data/mongodb/27017/ -p
2、 创建配置文件(三台配置一样)
systemLog:
destination: file
logAppend: true
path: /data/mongodb/27017/mongodb.log
storage:
dbPath: /data/mongodb/27017/
journal:
enabled: true
processManagement:
fork: true
net:
port: 27017
bindIp: 0.0.0.0#副本集标志,三台name要一样,才能加入到副本集。
replication:
replSetName: data3、 启动
启动三台实例/usr/local/mongodb/bin/mongod -f /data/mongodb/27017/mongodb.conf
4、 初始化
登录任意一台实例,进行初始化sql语句,三大步sql。
config = { _id:"data", members:[
{_id:0,host:"192.168.1.182:27017"},
{_id:1,host:"192.168.1.186:27017"},
{_id:2,host:"192.168.1.122:27017"}]
}进入到admin,进行初始化use admin
初始化需要时间rs.initiate( config )
查看状态rs.status() #副本集状态,一个primary,其它SECONDARY。primary是主,只有primary能写入。
注意:-id,为副本集配置文件里面的name一致。
1.7.3 优先级设置
primary的选举依赖于各个实例的优先权重,默认权重都是1
复本集的主挑选权重最高的,权重一样的无法控制谁为主
设置各个实例的优先权重,挑选自己想要的实例为主,只有primary可以更改权重配置
conf = rs.config() #获取副本集的配置,默认权重都是1
conf.members[0].priority = 10 #索引号从0开始,每次递增1,类似数组
conf.members[1].priority = 5
conf.members[2].priority = 2
rs.reconfig(conf) #更新mongodb副本集的配置,优先权重最高的提升为primary。关闭启动后也为主
至此,副本集搭建介绍完成
第2章 Mongodb分片集群介绍
Sharding cluster是一种可以水平扩展的模式,在数据量很大时特给力,实际大规模应用一般会采用这种架构去构建。sharding分片很好的解决了单台服务器磁盘空间、内存、cpu等硬件资源的限制问题,把数据水平拆分出去,降低单节点的访问压力。每个分片都是一个独立的数据库,所有的分片组合起来构成一个逻辑上的完整的数据库。因此,分片机制降低了每个分片的数据操作量及需要存储的数据量,达到多台服务器来应对不断增加的负载和数据的效果。
2.1 Sharding分区概念
将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。
2.1.1 分片的基本思想
将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分。通过一个名为mongos的路由进程进行操作,mongos知道数据和片的对应关系(通过配置服务器)。大部分使用场景都是解决磁盘空间的问题,对于写入有可能会变差(+++里面的说明+++),查 询则尽量避免跨分片查询。
2.1.2 使用分片的时机
1)机器的磁盘不够用了。使用分片解决磁盘空间的问题。
2)单个mongod已经不能满足写数据的性能要求。通过分片让写压力分散到各个分片上面,使用分片服务器自身的资源。
3)想把大量数据放到内存里提高性能。和上面一样,通过分片使用分片服务器自身的资源。
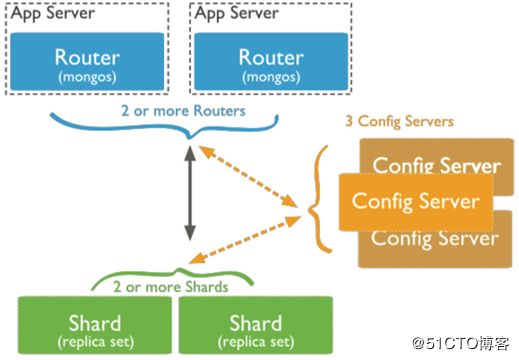
2.1.3 三种角色
1)分片服务器(Shard Server)
mongod实例,用于存储实际的数据块,实际生产环境中一个 shard server 角色可由几台机器组个一个 relica set 承担,防止主机单点故障。
这是一个独立普通的mongod进程,保存数据信息。可以是一个副本集也可以是单独的一台服务器(生产环境都是副本集)。
2)配置服务器(Config Server)
mongod 实例,存储了整个 Cluster Metadata,其中包括 chunk 信息。
这是一个独立的mongod进程,保存集群和分片的元数据,即各分片包含了哪些数据的信息。最先开始建立,启用日志功能。像启动普通的 mongod 一样启动。
配置服务器,指定configsvr 选项。不需要太多的空间和资源,配置服务器的 1KB 空间相当于真是数据的 200MB。保存的只是数据的分布表。
3)路由服务器(Route Server)
mongos实例,前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用
起到一个路由的功能,供程序连接。本身不保存数据,在启动时从配置服务器加载集群信息,开启 mongos 进程需要知道配置服务器的地址,指定configdb选项。
2.1.4 片键的意义
一个好的片键对分片至关重要。片键必须是一个索引,通过sh.shardCollection 加会自动创建索引。一个自增的片键对写入和数据均匀分布就不是很好, 因为自增的片键总会在一个分片上写入,后续达到某个阀值可能会写到别的分片。但是按照片键查询会非常高效。随机片键对数据的均匀分布效果很好。注意尽量避免在多个分片上进行查询。
在所有分片上查询,mongos 会对结果进行归并排序
2.1.5 分片的原理
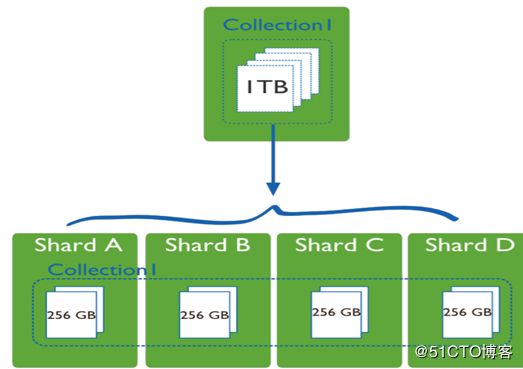
分片,是指将数据拆分,将其分散到不同的机器上。这样的好处就是,不需要功能强大的大型计算机也可以存储更多的数据,处理更大的负载。mongoDB 的分片,是将collection 的数据进行分割,然后将不同的部分分别存储到不同的机器上。当 collection 所占空间过大时,我们需要增加一台新的机器,分片会自动将 collection 的数据分发到新的机器上。
2.1.6 分片集群的构造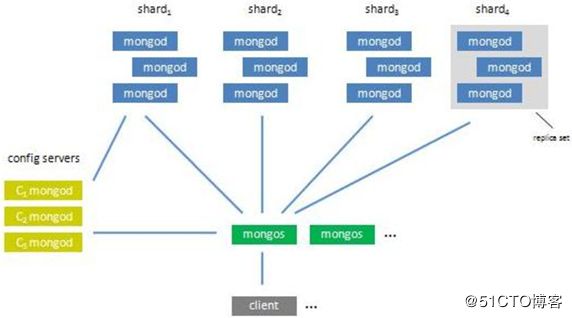
2.2 分片集群的搭建
2.2.1 环境准备
Centos7 64位系统
Mongodb 4.0版本
三台虚拟机
##三台路由服务器
192.168.1.182:20000
192.168.1.186:20000
192.168.1.122:20000
##三台配置服务器
192.168.1.182:21000
192.168.1.186:21000
192.168.1.122:21000
##九个分片数据服务器(测试复用三台),三组分片数据,各组为副本集。
192.168.1.182:27001
192.168.1.186:27001
192.168.1.122:27001
192.168.1.182:27002
192.168.1.186:27002
192.168.1.122:27002
192.168.1.182:27003
192.168.1.186:27003
192.168.1.122:27003###创建数据目录
#三台服务器,创建路由配置目录
mkdir /data/mongodb/20000 –p
#三台服务器,创建配置服务器目录
mkdir /data/mongodb/21000 –p
#三台服务器,创建shard目录
mkdir /data/mongodb/27001 –p
mkdir /data/mongodb/27002 –p
mkdir /data/mongodb/27003 –p安装包
三台服务下载安装包,解压到/usr/local/mongodb目录
https://www.mongodb.com/download-center?jmp=nav#community
https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-4.0.2.tgz解压到/usr/local/mongodb/目录下
2.2.2 配置角色搭建(configsvr)
1、编辑文件vim /usr/local/mongodb/conf/config.conf,三台服务器配置一样。
systemLog:
destination: file
logAppend: true
path: /data/mongodb/21000/mongodb.log
storage:
dbPath: /data/mongodb/21000/
journal:
enabled: true
processManagement:
fork: true
net:
port: 21000
bindIp: 127.0.0.1
replication:
replSetName: conf
sharding:
clusterRole: configsvr2、启动跟单例的启动方式一致,都是使用mongod
3、配置角色副本集搭建,配置角色也是副本集,达到高可用
config = { _id:"conf ",
configsvr: true,
members:[
{_id:0,host:"192.168.1.182:21000"},
{_id:1,host:"192.168.1.186:21000"},
{_id:2,host:"192.168.1.122:21000"}
]
}
rs.initiate(config)
rs.status() #查看状态2.2.3 路由角色搭建(mongos)
1、 编辑配置文件vim /usr/local/mongodb/conf/mongos.conf,三台一样配置,配置多个router,任何一个都能正常的获取数据
systemLog:
destination: file
logAppend: true
path: /data/mongodb/20000/mongodb.log
processManagement:
fork: true
net:
port: 20000
bindIp: 0.0.0.0
sharding:
configDB: config/192.168.1.182:21000,192.168.1.186:21000,192.168.1.122:21000##文件最后指定,配置角色的ip+端口。
2、 启动/usr/local/mongodb/bin/mongos -f /usr/local/mongodb/conf/mongos.conf
#路由服务器的启动和其他角色不一样。
2.2.4 数据角色搭建(shard)
三个shard,共有三个副本集。
##shard1
1、 编辑配置文件vim /usr/local/mongodb/conf/shard1.conf,三台shard1,配置一样。
systemLog:
destination: file
logAppend: true
path: /data/mongodb/27001/mongodb.log
storage:
dbPath: /data/mongodb/27001/
journal:
enabled: true
processManagement:
fork: true
net:
port: 27001
bindIp: 0.0.0.0
replication:
replSetName: data1
#name三台一致,副本集。不同的shard名称不同,如:data2、data3
sharding:
clusterRole: shardsvr
2、 启动3、 配置副本集
config = { _id:"data1",
members:[
{_id:0,host:"192.168.1.182:27001"},
{_id:1,host:"192.168.1.186:27001"},
{_id:2,host:"192.168.1.122:27001"}
]
}
#初始化
rs.initiate(config)
rs.status() #查看状态
至此搭建完成。2.3 验证
2.3.1 分片集群添加数据角色
#连接路由角色
sh.addShard("data1/192.168.1.182:27001,192.168.1.186:27001,192.168.1.122:27001");
sh.addShard("data2/192.168.1.182:27002,192.168.1.186:27002,192.168.1.122:27002");
sh.addShard("data3/192.168.1.182:27003,192.168.1.186:27003,192.168.1.122:27003");
sh.status()2.3.2 分片策略设置
默认添加数据没有分片存储,操作都是在路由角色里面
针对某个数据库的某个表使用hash分片存储,分片存储就会同一个colloection分配两个数据角色
use admin
db.runCommand( { enablesharding :"malin"});
db.runCommand( { shardcollection : "malin.myuser",key : {_id: "hashed"} } )2.3.3 插入数据进行分片
use malin
for(i=1; i<=500;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}查看三个shard是否有数据。
第3章 Mongodb gridfs介绍
GridFS是用于存储和检索超过 BSON -文档大小限制为16 MB的文件的规范。
GridFS不是将文件存储在单个文档中,而是将文件分成多个部分或块[1],并将每个块存储为单独的文档。默认情况下,GridFS使用默认的块大小255 kB; 也就是说,GridFS将文件分成255 kB的块,但最后一个块除外。最后一个块只有必要的大小。同样,不大于块大小的文件只有最终的块,只使用所需的空间和一些额外的元数据。
GridFS使用两个集合来存储文件。一个集合存储文件块(chunks),另一个存储文件元数据(files)。
GridFS不仅可用于存储超过16 MB的文件,还可用于存储您想要访问的任何文件,而无需将整个文件加载到内存中。
3.1 使用时机
1、 如果文件系统限制目录中的文件数,则可以使用GridFS根据需要存储任意数量的文件。
2、 如果要从大型文件的各个部分访问信息而无需将整个文件加载到内存中,可以使用GridFS调用文件的各个部分,而无需将整个文件读入内存。
3、 如果要保持文件和元数据在多个系统和工具中自动同步和部署,可以使用GridFS。使用地理位置分散的副本集时,MongoDB可以自动将文件及其元数据分发到多个 mongod实例和工具中。
3.2 Gridfs集合
chunks存储二进制块。默认是fs.chunks
#字段
{
“ _ id ” : < ObjectId > ,
“files_id” : < ObjectId > ,
“n” : < num > ,
“data” : < binary >
}files存储文件的元数据。默认是fs.files
#字段
{
"_id" :
"length" :
"chunkSize" :
"uploadDate" :
"md5" :
"filename" :
"contentType" :
"aliases" :
"metadata" :
}
3.3 拆分GridFS
3.3.1 拆分chunks
对chunks集合进行分片,使用files_id字段,利用哈希进行分片
3.3.2 拆分files
对files集合进行分片,使用_id字段,利用哈希进行分片
3.4 实例
1、配置分片策略
#进入到路由服务器
use admin
#指定拆分的数据库test
db.runCommand( { enablesharding :"test"});
#指定拆分的files,test数据库中的test-file.files集合,利用_id字段
db.runCommand( { shardcollection : "test.test-file.files",key : {_id: "hashed"} } )
#指定拆分的chunks,test数据库中的test.test-file.chunks集合,利用files_id,字段
db.runCommand( { shardcollection : "test.test-file.chunks",key : {files_id: "hashed"}})2、 上传文件到test库中的test-file集合
命令行
mongofiles -d test1 -h 127.0.0.1 --port 20000 --prefix test-file put 1553.png
-d指定数据库
-h主机
--port端口(路由角色)
--prefix 指定集合
Put 上传第4章 Nginx GridFS介绍
mongodb分片已经搭建完成,利用nginx的GridFS模块,实现nginx直接连接到mongodb数据库读取文件、图片。
4.1 下载nginx
1、安装 nginx 需要的依赖
yum install -y zlib zlib-devel gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel
注意:编译nginx过程中,如在出现问题,自行安装依赖。
2、下载nginx
wget -c https://nginx.org/download/nginx-1.12.1.tar.gz
tar -zxvf nginx-1.12.1.tar.gz -C /usr/local/nginx
4.2 下载nginx-gridfs模块
nginx通过该模块和mongodb的gridfs进行整合
wget -c https://github.com/mdirolf/nginx-gridfs/archive/v0.8.tar.gz -O nginx-gridfs-0.8.tar.gz
tar -xzvf ./nginx-gridfs-0.8.tar.gz
4.3 下载nginx的mongodb驱动
将这个驱动下的所有移动到nginx-gridfs模块目录下的mongo-c-driver目录,为了后期编译
wget https://github.com/mongodb/mongo-c-driver/archive/v0.3.1.tar.gz
tar -zxvf v0.3.1.tar.gz
cd /root/mongo-c-driver-0.3.1
#将驱动下的所有移动到nginx-gridfs目录下的mongo-c-driver目录下。
mv ./* /root/nginx-gridfs-0.8/mongo-c-driver/
[root@hadoop-namenode mongo-c-driver]# ll
total 36
-rw-rw-r-- 1 root root 11358 May 13 2011 APACHE-2.0.txt
drwxrwxr-x 2 root root 40 May 13 2011 buildscripts
drwxrwxr-x 2 root root 41 May 13 2011 docs
-rw-rw-r-- 1 root root 10760 May 13 2011 doxygenConfig
-rw-rw-r-- 1 root root 363 May 13 2011 HISTORY.md
-rw-rw-r-- 1 root root 3024 May 13 2011 README.md
-rw-rw-r-- 1 root root 4090 May 13 2011 SConstruct
drwxrwxr-x 2 root root 185 May 13 2011 src
drwxrwxr-x 2 root root 282 May 13 2011 test
4.4 编译安装
#进入到nginx包目录下
cd nginx-1.12.0
#开始编译,--add-module=/root/nginx-gridfs-0.8。这个目录就是nginx-gridfs模块的位置。
./configure --user=nginx --group=nginx --prefix=/usr/local/nginx/ --with-http_v2_module --with-http_ssl_module --with-http_sub_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --add-module=/root/nginx-gridfs-0.8/
make && make install4.5 问题处理
1、在make && make install的时候报错:
ngx_http_gridfs_module.c:684:16: 错误:变量‘chunksize’被设定但未被使用
处理方法:进入nginx包目录 vi nginx-1.12.0/objs/Makefile修改一个小错误,把第3行的-Werror错误去掉。
2、not exist /root/nginx-gridfs-0.8/mongo-c-driver/src/*.h,表示nginx的mongodb驱动没有安装。
处理方法:安装驱动,下载nginx的mongodb驱动。
至此nginx和nginx-gridfs模块编译成功,下面是配置文件的修改。
4.6 nginx-gridfs配置文件
#进入安装好的nginx配置文件conf目录下
server{
listen 80;
server_name 192.168.60.235;
#charset koi8-r;
#access_log logs/host.access.log main;
location /pics/ {
gridfs test
field=_id
type=objectid;
mongo 192.168.xx.2x7:27017;
}
}4.7 配置文件参数详解
gridfs:nginx识别插件的关键字
edusns:db名
[root_collection]: 选择collection,如root_collection=blog, mongod就会去找blog.files与blog.chunks两个块,默认是fs
[field]: 查询字段,保证mongdb里有这个字段名,支持_id, filename, 可省略, 默认是_id
[type]: 解释field的数据类型,支持objectid, int, string, 可省略, 默认是int
[user]: 用户名, 可省略
[pass]: 密码, 可省略
mongo: mongodb 路由地址(集群中)
4.8 测试
1、上传文件到mongodb,然后进行浏览器测试。
#命令行mongodb上传文件
mongofiles put 1234.jpg --local ~/1234.jpg --host 172.0.0.1 --port 27017 --db testdb --type jpg
2、浏览器访问
ip/pics/1234.jpg
#nginx地址
第5章 总结
5.1 分片集群搭建
5.1.1 Config角色
配置文件(三台都配置)
systemLog:
destination: file
logAppend: true
path: /data/mongodb/21000/mongodb.log
storage:
dbPath: /data/mongodb/21000/
journal:
enabled: true
processManagement:
fork: true
net:
port: 21000
bindIp: 127.0.0.1
replication:
replSetName: conf
sharding:
clusterRole: configsvr
#只需修改端口即可,三台一致。配置副本集
启动进入到任意一台实例进行配置
config = { _id:"conf ",
configsvr: true,
members:[
{_id:0,host:"192.168.1.182:21000"},
{_id:1,host:"192.168.1.186:21000"},
{_id:2,host:"192.168.1.122:21000"}
]
}
rs.initiate(config)
rs.status() #查看状态
#注意:_id为副本集名称5.1.2 mongos角色
配置文件(三台一样配置文件)
systemLog:
destination: file
logAppend: true
path: /data/mongodb/20000/mongodb.log
processManagement:
fork: true
net:
port: 20000
bindIp: 0.0.0.0
sharding:
configDB: config/192.168.1.182:21000,192.168.1.186:21000,192.168.1.122:21000
#指定配置角色位置5.1.3 shard角色
配置文件(九个实例,三个为一组副本集),只需修改端口和副本集名称
systemLog:
destination: file
logAppend: true
path: /data/mongodb/27001/mongodb.log
storage:
dbPath: /data/mongodb/27001/
journal:
enabled: true
processManagement:
fork: true
net:
port: 27001
bindIp: 0.0.0.0
replication:
replSetName: data1
#name三台一致,副本集。不同的shard名称不同,如:data2、data3
sharding:
clusterRole: shardsvr
#配置副本集
启动,进入到任意一台分片实例,进行副本集配置。
config = { _id:"data1",
members:[
{_id:0,host:"192.168.1.182:27001"},
{_id:1,host:"192.168.1.186:27001"},
{_id:2,host:"192.168.1.122:27001"}
]
}
rs.initiate(config)
rs.status() #查看状态
#注意:_id为副本集名称5.1.4 将数据角色添加到分片集群中
进入到路由角色实例
sh.addShard("data1/192.168.1.182:27001,192.168.1.186:27001,192.168.1.122:27001");
sh.addShard("data2/192.168.1.182:27002,192.168.1.186:27002,192.168.1.122:27002");
sh.addShard("data3/192.168.1.182:27003,192.168.1.186:27003,192.168.1.122:27003");
sh.status()
#三个shard分片。5.1.5 拆分Gridfs上传的文件
#进入到路由服务器
use admin
#指定拆分的数据库test
db.runCommand( { enablesharding :"test"});
#指定拆分的files,test数据库中的test-file.files集合,利用_id字段
db.runCommand( { shardcollection : "test.test-file.files",key : {_id: "hashed"} } )
#指定拆分的chunks,test数据库中的test.test-file.chunks集合,利用files_id,字段
db.runCommand( { shardcollection : "test.test-file.chunks",key : {files_id: "hashed"}})
#命令行上传测试
mongofiles -d test1 -h 127.0.0.1 --port 20000 --prefix test-file put 1553.png
5.2 Nginx-gridfs搭建
5.2.1 下载nginx包及依赖
yum install -y zlib zlib-devel gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel
wget -c https://nginx.org/download/nginx-1.12.1.tar.gz
tar -zxvf nginx-1.12.1.tar.gz -C /usr/local/nginx
5.2.2 下载nginx-gridfs模块
wget -c https://github.com/mdirolf/nginx-gridfs/archive/v0.8.tar.gz -O nginx-gridfs-0.8.tar.gz
tar -xzvf ./nginx-gridfs-0.8.tar.gz
5.2.3 下载nginx的mongodb驱动,并移动到nginx-gridfs模块下
wget https://github.com/mongodb/mongo-c-driver/archive/v0.3.1.tar.gz
tar -zxvf v0.3.1.tar.gz
cd /root/mongo-c-driver-0.3.1
mv ./* /root/nginx-gridfs-0.8/mongo-c-driver/
5.2.4 编译安装nginx
./configure --user=nginx --group=nginx --prefix=/usr/local/nginx/ --with-http_v2_module --with-http_ssl_module --with-http_sub_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --add-module=/root/nginx-gridfs-0.8/
5.2.5 配置文件
server{
listen 80;
server_name 192.168.60.235;
#charset koi8-r;
#access_log logs/host.access.log main;
location /pics/ {
gridfs test
field=_id
type=objectid;
mongo 192.168.xx.2x7:27017;
}
}5.2.6 命令行测试。上传文件
mongofiles put 1234.jpg --local ~/1234.jpg --host 172.0.0.1 --port 27017 --db testdb --type jpg