
大概流程
一段对SQL执行完整的一套代码。分为四个步骤:
总结来说Calcite有以下主要功能:
- SQL 解析
- SQL 校验
- 查询优化
- SQL 生成器
-
数据连接
Calcite 解析SQl的步骤:
 Calcite 解析步骤
Calcite 解析步骤
如上图中所述,一般来说Calcite解析SQL有以下几步:
- Parser. 此步中Calcite通过Java CC将SQL解析成未经校验的AST
- Validate. 该步骤主要作用是校证Parser步骤中的AST是否合法,如验证SQL scheme、字段、函数等是否存在; SQL语句是否合法等. 此步完成之后就生成了RelNode树(关于RelNode树, 请参考下文)
- Optimize. 该步骤主要的作用优化RelNode树, 并将其转化成物理执行计划。主要涉及SQL规则优化如:基于规则优化(RBO)及基于代价(CBO)优化; Optimze 这一步原则上来说是可选的, 通过Validate后的RelNode树已经可以直接转化物理执行计划,但现代的SQL解析器基本上都包括有这一步,目的是优化SQL执行计划。此步得到的结果为物理执行计划。
- Execute,即执行阶段。此阶段主要做的是:将物理执行计划转化成可在特定的平台执行的程序。如Hive与Flink都在在此阶段将物理执行计划CodeGen生成相应的可执行代码。
Calcite相关组件
Calcite主要有以下概念:
- Catalog: 主要定义SQL语义相关的元数据与命名空间。
- SQL parser: 主要是把SQL转化成AST.
- SQL validator: 通过Catalog来校证AST.
- Query optimizer: 将AST转化成物理执行计划、优化物理执行计划.
- SQL generator: 反向将物理执行计划转化成SQL语句.
Convert query to SqlNode
public class Test {
public static void main(String[] args) throws SqlParseException {
// Convert query to SqlNode
String sql = "select price from transactions";
//构建config,有默认的构造也有带参数的config 返回ConfigImpl 有默认的实现
Config config = SqlParser.configBuilder().build();
//根据config构建sql解析器 reader是SourceStringReader,String流
SqlParser parser = SqlParser.create(sql, config);
//构建parse tree
SqlNode node = parser.parseQuery();
}
}
上述代码流程:
调用SqlParser将SQL语句生成SQL Tree。这部分是Java CC基于Parser.jj文件模板来实现的,输出为SqlNode的Tree。
详细分解
/** Implementation of
* {@link Config}.
* Called by builder; all values are in private final fields. */
private static class ConfigImpl implements Config {
private final int identifierMaxLength; //最大长度标识
private final boolean caseSensitive;
//有效SQL兼容模式的枚举
private final SqlConformance conformance;
private final Casing quotedCasing; //Casing是枚举类型,大小写,未改变
private final Casing unquotedCasing;
private final Quoting quoting; //引用
private final SqlParserImplFactory parserFactory; //
//私有构造函数
private ConfigImpl(int identifierMaxLength, Casing quotedCasing,
Casing unquotedCasing, Quoting quoting, boolean caseSensitive,
SqlConformance conformance, SqlParserImplFactory parserFactory) {
this.identifierMaxLength = identifierMaxLength;
this.caseSensitive = caseSensitive;
this.conformance = Objects.requireNonNull(conformance);
this.quotedCasing = Objects.requireNonNull(quotedCasing);
this.unquotedCasing = Objects.requireNonNull(unquotedCasing);
this.quoting = Objects.requireNonNull(quoting);
this.parserFactory = Objects.requireNonNull(parserFactory);
}
追溯Config,有默认的ConfigImpl实现,ConfigImpl是SqlParser的内部类,通过builder来构建。ConfigBuilder里边都有默认的Config配置。
/** Builder for a {@link Config}. */
public static class ConfigBuilder {
private Casing quotedCasing = Lex.ORACLE.quotedCasing;
private Casing unquotedCasing = Lex.ORACLE.unquotedCasing;
private Quoting quoting = Lex.ORACLE.quoting;
private int identifierMaxLength = DEFAULT_IDENTIFIER_MAX_LENGTH;
private boolean caseSensitive = Lex.ORACLE.caseSensitive;
private SqlConformance conformance = SqlConformanceEnum.DEFAULT;
private SqlParserImplFactory parserFactory = SqlParserImpl.FACTORY;
在这里讲一下SqlParserImplFactory
public interface SqlParserImplFactory {
/**
* Get the underlying parser implementation.
*
* @return {@link SqlAbstractParserImpl} object.
*/
SqlAbstractParserImpl getParser(Reader stream);
}
SqlAbstractParserImpl的代理,Parse的代理,这里可以自定义Parse的实现
接下来是生成SQLParser
public static SqlParser create(Reader reader, Config config) {
SqlAbstractParserImpl parser =
//config里边得到Factory
config.parserFactory().getParser(reader);
return new SqlParser(parser, config);
}
SqlParserImplFactory.java
/**
* Get the underlying parser implementation.
*
* @return {@link SqlAbstractParserImpl} object.
*/
SqlAbstractParserImpl getParser(Reader stream);
这里会返回SqlAbstractParserImpl具体的实现类。
然后
//解析select语句
public SqlNode parseQuery() throws SqlParseException {
return parser.parseSqlStmtEof();
//略过
}
构建parse tree SqlNode即为生成的AST的根节点,代表了整个抽象语法树。
我们来看看Parser.jj的具体的解析过程源码:
在SqlParserImpl.java。读Parser.jj stream的形式读取。SQL解析器,由JavaCC从Parser.jj生成。
/**
* Parses an SQL statement followed by the end-of-file symbol.
* 解析SQL语句,后跟文件结束符号。
*/
final public SqlNode SqlStmtEof() throws ParseException {
SqlNode stmt;
stmt = SqlStmt();
jj_consume_token(0);
{if (true) return stmt;}
throw new Error("Missing return statement in function");
}
接着来看:
SqlStmt();这里会有具体的解析过程,读者可以自行阅读相应源码。代码最终会生成SqlNode
/**
* Parses an SQL statement.
* 解析SQL语句。
*/
final public SqlNode SqlStmt() throws ParseException {
SqlNode stmt;
if (jj_2_34(2)) {
stmt = SqlSetOption(Span.of(), null);
} else if (jj_2_35(2)) {
stmt = SqlAlter();
} else if (jj_2_36(2)) {
stmt = OrderedQueryOrExpr(ExprContext.ACCEPT_QUERY);
} else if (jj_2_37(2)) {
stmt = SqlExplain();
} else if (jj_2_38(2)) {
stmt = SqlDescribe();
} else if (jj_2_39(2)) {
stmt = SqlInsert();
} else if (jj_2_40(2)) {
stmt = SqlDelete();
} else if (jj_2_41(2)) {
stmt = SqlUpdate();
} else if (jj_2_42(2)) {
stmt = SqlMerge();
} else if (jj_2_43(2)) {
stmt = SqlProcedureCall();
} else {
jj_consume_token(-1);
throw new ParseException();
}
{if (true) return stmt;}
throw new Error("Missing return statement in function");
}
Convert SqlNode to RelNode
//VolcanoPlanner会根据动态算法优化查询 cost factory
VolcanoPlanner planner = new VolcanoPlanner();
//行表达式代理 一些常见的字符值会被缓存
RexBuilder rexBuilder = createRexBuilder();
//优化查询期间的环境 RelOptPlanner会把相关的表达式转换成语义上的表达式
RelOptCluster cluster = RelOptCluster.create(planner, rexBuilder);
//创建converter
SqlToRelConverter converter = new SqlToRelConverter(...);
//通常root为tree的根节点
RelRoot root = converter.convertQuery(node, false, true);
上述代码流程
SqlToRelConverter将SQL Tree转化为Calcite中的RelNode。虽然两种Node都是类似于Tree的形式,但是表示的含义不同。SqlNode有很多种,既包括MIN、MAX这种表达式型的,也包括SELECT、JOIN这种关系型的,转化过程中,将这两种分离成RelNode关系型和RexNode表达式型。
详细分解
VolcanoPlanner.java
/**
* Creates a {@code VolcanoPlanner} with a given cost factory.
*/
public VolcanoPlanner(RelOptCostFactory costFactory, //
Context externalContext) {
super(costFactory == null ? VolcanoCost.FACTORY : costFactory, //
externalContext);
this.zeroCost = this.costFactory.makeZeroCost();
}
RexBuilder.java
行表达式代理 一些常见的字符值会被缓存 (NULL, TRUE, FALSE, 0, 1, '') are cached
public RexBuilder(RelDataTypeFactory typeFactory) {
this.typeFactory = typeFactory;
this.booleanTrue =
makeLiteral(
Boolean.TRUE,
typeFactory.createSqlType(SqlTypeName.BOOLEAN),
SqlTypeName.BOOLEAN);
this.booleanFalse =
makeLiteral(
Boolean.FALSE,
typeFactory.createSqlType(SqlTypeName.BOOLEAN),
SqlTypeName.BOOLEAN);
this.charEmpty =
makeLiteral(
new NlsString("", null, null),
typeFactory.createSqlType(SqlTypeName.CHAR, 0),
SqlTypeName.CHAR);
this.constantNull =
makeLiteral(
null,
typeFactory.createSqlType(SqlTypeName.NULL),
SqlTypeName.NULL);
}
基本都是对于一些常量的初始化。没有多说的。
RelOptCluster.java
优化查询期间的环境 RelOptPlanner会把相关的表达式转换成语义上的表达式
RelOptCluster(RelOptPlanner planner, RelDataTypeFactory typeFactory,
RexBuilder rexBuilder, AtomicInteger nextCorrel,
Map mapCorrelToRel) {
this.nextCorrel = nextCorrel;
this.mapCorrelToRel = mapCorrelToRel;
this.planner = Objects.requireNonNull(planner);
this.typeFactory = Objects.requireNonNull(typeFactory);
this.rexBuilder = rexBuilder;
this.originalExpression = rexBuilder.makeLiteral("?");
// set up a default rel metadata provider,
// giving the planner first crack at everything
//元数据 它提供了标准逻辑代数的一般公式和推导规则
setMetadataProvider(DefaultRelMetadataProvider.INSTANCE);
//特质
this.emptyTraitSet = planner.emptyTraitSet();
assert emptyTraitSet.size() == planner.getRelTraitDefs().size();
}
DefaultRelMetadataProvider构造函数提供很多规则,可以自己去看。
protected DefaultRelMetadataProvider() {
super(
ImmutableList.of(
RelMdPercentageOriginalRows.SOURCE,
RelMdColumnOrigins.SOURCE,
RelMdExpressionLineage.SOURCE,
RelMdTableReferences.SOURCE,
RelMdNodeTypes.SOURCE,
RelMdRowCount.SOURCE,
RelMdMaxRowCount.SOURCE,
RelMdMinRowCount.SOURCE,
RelMdUniqueKeys.SOURCE,
RelMdColumnUniqueness.SOURCE,
RelMdPopulationSize.SOURCE,
RelMdSize.SOURCE,
RelMdParallelism.SOURCE,
RelMdDistribution.SOURCE,
RelMdMemory.SOURCE,
RelMdDistinctRowCount.SOURCE,
RelMdSelectivity.SOURCE,
RelMdExplainVisibility.SOURCE,
RelMdPredicates.SOURCE,
RelMdAllPredicates.SOURCE,
RelMdCollation.SOURCE));
}
回到RelOptCluster,继续往下走
SqlToRelConverter.java
创建converter 完成SqlNode 到 RelNode的转换
@Deprecated // to be removed before 2.0
public SqlToRelConverter(
RelOptTable.ViewExpander viewExpander,
SqlValidator validator, //SQL校验器
Prepare.CatalogReader catalogReader,
RelOptPlanner planner,
RexBuilder rexBuilder,
SqlRexConvertletTable convertletTable) {
this(viewExpander, validator, catalogReader,
RelOptCluster.create(planner, rexBuilder), convertletTable,
Config.DEFAULT);
}
接下来完成SqlNode 到RelNode转换
converter.convertQuery(node, false, true);
这个过程中,有校验的方法,我们一起来看看
public SqlNode validate(SqlNode topNode) {
SqlValidatorScope scope = new EmptyScope(this);
scope = new CatalogScope(scope, ImmutableList.of("CATALOG"));
final SqlNode topNode2 = validateScopedExpression(topNode, scope);
final RelDataType type = getValidatedNodeType(topNode2);
Util.discard(type);
return topNode2;
}
看看怎么具体做validate:
先来看看Scope:
上图
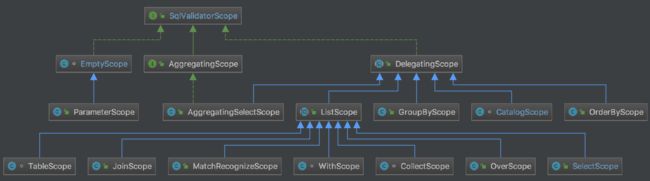
图上,有很多个***Scope。
convertQuery()方法中有
RelNode result = convertQueryRecursive(query, top, null).rel;
得到RelRoot(RelNode树的根节点)
protected RelRoot convertQueryRecursive(SqlNode query, boolean top,
RelDataType targetRowType) {
final SqlKind kind = query.getKind();
switch (kind) {
case SELECT:
return RelRoot.of(convertSelect((SqlSelect) query, top), kind);
case INSERT:
return RelRoot.of(convertInsert((SqlInsert) query), kind);
case DELETE:
return RelRoot.of(convertDelete((SqlDelete) query), kind);
case UPDATE:
return RelRoot.of(convertUpdate((SqlUpdate) query), kind);
case MERGE:
return RelRoot.of(convertMerge((SqlMerge) query), kind);
case UNION:
case INTERSECT:
case EXCEPT:
return RelRoot.of(convertSetOp((SqlCall) query), kind);
case WITH:
return convertWith((SqlWith) query, top);
case VALUES:
return RelRoot.of(convertValues((SqlCall) query, targetRowType), kind);
default:
throw new AssertionError("not a query: " + query);
}
}
我们来看:RelRoot.of(convertSelect((SqlSelect) query, top), kind);
/**
* Converts a SELECT statement's parse tree into a relational expression.
*/
public RelNode convertSelect(SqlSelect select, boolean top) {
final SqlValidatorScope selectScope = validator.getWhereScope(select);
final Blackboard bb = createBlackboard(selectScope, null, top);
convertSelectImpl(bb, select);
return bb.root;
}
中间有一些方法没有看懂,稍后补上。
来看:
RelNode optimized = planner.findBestExp();
public RelNode findBestExp() {
ensureRootConverters();
registerMaterializations();
int cumulativeTicks = 0;
for (VolcanoPlannerPhase phase : VolcanoPlannerPhase.values()) {
setInitialImportance();
RelOptCost targetCost = costFactory.makeHugeCost();
int tick = 0;
int firstFiniteTick = -1;
int splitCount = 0;
int giveUpTick = Integer.MAX_VALUE;
while (true) {
++tick;
++cumulativeTicks;
if (root.bestCost.isLe(targetCost)) {
if (firstFiniteTick < 0) {
firstFiniteTick = cumulativeTicks;
clearImportanceBoost();
}
if (ambitious) {
// Choose a slightly more ambitious target cost, and
// try again. If it took us 1000 iterations to find our
// first finite plan, give ourselves another 100
// iterations to reduce the cost by 10%.
targetCost = root.bestCost.multiplyBy(0.9);
++splitCount;
if (impatient) {
if (firstFiniteTick < 10) {
// It's possible pre-processing can create
// an implementable plan -- give us some time
// to actually optimize it.
giveUpTick = cumulativeTicks + 25;
} else {
giveUpTick =
cumulativeTicks
+ Math.max(firstFiniteTick / 10, 25);
}
}
} else {
break;
}
} else if (cumulativeTicks > giveUpTick) {
// We haven't made progress recently. Take the current best.
break;
} else if (root.bestCost.isInfinite() && ((tick % 10) == 0)) {
injectImportanceBoost();
}
LOGGER.debug("PLANNER = {}; TICK = {}/{}; PHASE = {}; COST = {}",
this, cumulativeTicks, tick, phase.toString(), root.bestCost);
VolcanoRuleMatch match = ruleQueue.popMatch(phase);
if (match == null) {
break;
}
assert match.getRule().matches(match);
match.onMatch();
// The root may have been merged with another
// subset. Find the new root subset.
root = canonize(root);
}
ruleQueue.phaseCompleted(phase);
}
if (LOGGER.isTraceEnabled()) {
StringWriter sw = new StringWriter();
final PrintWriter pw = new PrintWriter(sw);
dump(pw);
pw.flush();
LOGGER.trace(sw.toString());
}
RelNode cheapest = root.buildCheapestPlan(this);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug(
"Cheapest plan:\n{}", RelOptUtil.toString(cheapest, SqlExplainLevel.ALL_ATTRIBUTES));
LOGGER.debug("Provenance:\n{}", provenance(cheapest));
}
return cheapest;
}
细节稍后补上。
来看:

Optimize RelNode
RelNode optimized = planner.findBestExp();