Docker Swarm Mode
Docker v1.12 是一个非常重要的版本,Docker 重新实现了集群的编排方式。在此之前,提供集群功能的 Docker Swarm 是一个单独的软件,而且依赖外部数据库(比如 Consul、etcd 或 Zookeeper)。
从 v1.12 开始,Docker Swarm 的功能已经完全与 Docker Engine 集成,要管理集群,只需要启动 Swarm Mode。安装好 Docker,Swarm 就已经在那里了,服务发现也在那里了(不需要安装 Consul 等外部数据库)。
相比 Kubernetes,用 Docker Swarm 创建集群非常简单,不需要额外安装任何软件,也不需要做任何额外的配置。很适合作为学习容器编排引擎的起点。
重要概念
- swarm
swarm 运行 Docker Engine 的多个主机组成的集群。从 v1.12 开始,集群管理和编排功能已经集成进 Docker Engine。当 Docker Engine 初始化了一个 swarm 或者加入到一个存在的 swarm 时,它就启动了 swarm mode。没启动 swarm mode 时,Docker 执行的是容器命令;运行 swarm mode 后,Docker 增加了编排 service 的能力。Docker 允许在同一个 Docker 主机上既运行 swarm service,又运行单独的容器。
- node
swarm 中的每个 Docker Engine 都是一个 node,有两种类型的 node:manager 和 worker。为了向 swarm 中部署应用,我们需要在 manager node 上执行部署命令,manager node 会将部署任务拆解并分配给一个或多个 worker node 完成部署。manager node 负责执行编排和集群管理工作,保持并维护 swarm 处于期望的状态。swarm 中如果有多个 manager node,它们会自动协商并选举出一个 leader 执行编排任务。woker node 接受并执行由 manager node 派发的任务。默认配置下 manager node 同时也是一个 worker node,不过可以将其配置成 manager-only node,让其专职负责编排和集群管理工作。work node 会定期向 manager node 报告自己的状态和它正在执行的任务的状态,这样 manager 就可以维护整个集群的状态。
- service
service 定义了 worker node 上要执行的任务。swarm 的主要编排任务就是保证 service 处于期望的状态下。举一个 service 的例子:在 swarm 中启动一个 http 服务,使用的镜像是 httpd:latest,副本数为 3。manager node 负责创建这个 service,经过分析知道需要启动 3 个 httpd 容器,根据当前各 worker node 的状态将运行容器的任务分配下去,比如 worker1 上运行两个容器,worker2 上运行一个容器。运行了一段时间,worker2 突然宕机了,manager 监控到这个故障,于是立即在 worker3 上启动了一个新的 httpd 容器。这样就保证了 service 处于期望的三个副本状态。
创建swarm 集群
swarm-manager 是 manager node,swarm-worker1 和 swarm-worker2 是 worker node。创建三节点的 swarm 集群。
在 swarm-manager 上执行如下命令创建 swarm。
docker swarm init --advertise-addr 10.10.8.125
--advertise-addr 指定与其他 node 通信的地址。
执行 docker node ls 查看当前 swarm 的 node,目前只有一个 manager。复制前面的 docker swarm join 命令,在 swarm-worker1 和 swarm-worker2 上执行,将它们添加到 swarm 中。命令输出如下:
docker swarm join --token SWMTKN-1-3rx3jnumdxja3rm4k5h8pijqbttoctjvy4p3fo7t0kdxwffcoz-5uwscs6wh2s9lpqg3lclv00y7 10.10.8.125:2377
docker node ls 可以看到两个 worker node 已经添加进来了。如果当时没有记录下 docker swarm init 提示的添加 worker 的完整命令,可以通过 docker swarm join-token worker 查看。
运行service
现在部署一个运行 httpd 镜像的 service,执行如下命令:
docker service create --name web_server httpd
部署 service 的命令形式与运行容器的 docker run 很相似,--name 为 service 命名,httpd 为镜像的名字。
通过 docker service ls 可以查看当前 swarm 中的 service。REPLICAS 显示当前副本信息,0/1 的意思是 web_server 这个 service 期望的容器副本数量为 1,目前已经启动的副本数量为 0。也就是当前 service 还没有部署完成。命令 docker service ps 可以查看 service 每个副本的状态。
可以看到 service 唯一的副本被分派到 swarm-worker1,当前的状态是 Preparing,还没达到期望的状态 Running,我们不仅要问,这个副本在 Preparing 什么呢?其实答案很简单,swarm-worker1 是在 pull 镜像,下载完成后,副本就会处于 Running 状态了。
service伸缩
对于 web 服务,我们通常会运行多个实例。这样可以负载均衡,同时也能提供高可用。swarm 要实现这个目标非常简单,增加 service 的副本数就可以了。在 swarm-manager 上执行如下命令:docker service scale web_server=5。副本数增加到 5,通过 docker service ls 和 docker service ps 查看副本的详细信息。
默认配置下 manager node 也是 worker node,所以 swarm-manager 上也运行了副本。如果不希望在 manager 上运行 service,可以执行如下命令:docker node update --availability drain swarm-manager
我们还可以 scale down,减少副本数,运行下面的命令:
docker service scale web_server=3
实现failover
创建 service 的时候,我们没有告诉 swarm 发生故障时该如何处理,只是说明了我们期望的状态(比如运行3个副本),swarm 会尽最大的努力达成这个期望状态,无论发生什么状况。
现在swarm-worker1上有两个副本,swarm-worker2上有一个副本,当我们关闭 swarm-worker1。Swarm 会检测到 swarm-worker1 的故障,并标记为 Down。Swarm 会将 swarm-worker1 上的副本调度到其他可用节点。我们可以通过 docker service ps 观察这个 failover 过程。可以看到,web_server.1 和 web_server.2 已经从 swarm-worker1 迁移到了 swarm-worker2,之前运行在故障节点 swarm-worker1 上的副本状态被标记为 Shutdown。
访问service
服务并没有暴露给外部网络,只能在 Docker 主机上访问。换句话说,当前配置下,我们无法访问 service web_server。
要将 service 暴露到外部,方法其实很简单,执行下面的命令:
docker service update --publish-add 8080:80 web_server
如果是新建 service,可以直接用使用 --publish 参数,比如:
docker service create --name web_server --publish 8080:80 --replicas=2 httpd
器在 80 端口上监听 http 请求,--publish-add 8080:80 将容器的 80 映射到主机的 8080 端口,这样外部网络就能访问到 service 了。curl 集群中任何一个节点的 8080 端口,都能够访问到 web_server。
routing mesh
当我们访问任何节点的 8080 端口时,swarm 内部的 load balancer 会将请求转发给 web_server 其中的一个副本。这就是 routing mesh 的作用。
所以,无论访问哪个节点,即使该节点上没有运行 service 的副本,最终都能访问到 service。另外,我们还可以配置一个外部 load balancer,将请求路由到 swarm service。比如配置 HAProxy,将请求分发到各个节点的 8080 端口。
ingress 网络
当我们应用 --publish-add 8080:80 时,swarm 会重新配置 service,之前的所有副本都被 Shutdown,然后启动了新的副本。
查看新副本的容器网络配置:
# docker exec web_server.2.r2d9wt0ik82dmczxy5p2qwnv8 ip r
default via 172.18.0.1 dev eth1
10.255.0.0/16 dev eth0 proto kernel scope link src 10.255.0.7
172.18.0.0/16 dev eth1 proto kernel scope link src 172.18.0.3
容器的网络与 --publish-add 之前已经大不一样了,现在有两块网卡,每块网卡连接不同的 Docker 网络。
实际上:
1、eth0 连接的是一个 overlay 类型的网络,名字为 ingress,其作用是让运行在不同主机上的容器可以相互通信。
2、eth1 连接的是一个 bridge 类型的网络,名字为 docker_gwbridge,其作用是让容器能够访问到外网。
# docker network ls
NETWORK ID NAME DRIVER SCOPE
cffcec359069 bridge bridge local
15a7c1fbba33 docker_gwbridge bridge local
bae92bff8199 host host local
l0usihpnydn3 ingress overlay swarm
b7ec19400b21 mac_net1 macvlan local
cdc188b05e3c mac_net10 macvlan local
870eae5eb0c3 mac_net20 macvlan local
deb4cbe62ba0 none null local
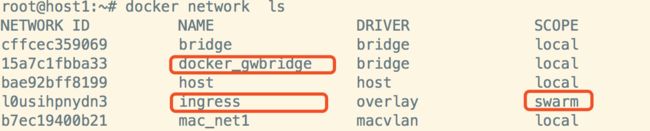
ingress 网络是 swarm 创建时 Docker 为自动我们创建的,swarm 中的每个 node 都能使用 ingress。通过 overlay 网络,主机与容器、容器与容器之间可以相互访问;同时,routing mesh 将外部请求路由到不同主机的容器,从而实现了外部网络对 service 的访问。
service之间通信
微服务架构的应用由若干 service 组成。比如有运行 httpd 的 web 前端,有提供缓存的 memcached,有存放数据的 mysql,每一层都是 swarm 的一个 service,每个 service 运行了若干容器。在这样的架构中,service 之间是必然要通信的。
- 服务发现
一种实现方法是将所有 service 都 publish 出去,然后通过 routing mesh 访问。但明显的缺点是把 memcached 和 mysql 也暴露到外网,增加了安全隐患。
如果不 publish,那么 swarm 就要提供一种机制,能够:
1、让 service 通过简单的方法访问到其他 service。
2、当 service 副本的 IP 发生变化时,不会影响访问该 service 的其他 service。
3、当 service 的副本数发生变化时,不会影响访问该 service 的其他 service。
这其实就是服务发现(service discovery)。Docker Swarm 原生就提供了这项功能,通过服务发现,service 的使用者不需要知道 service 运行在哪里,IP 是多少,有多少个副本,就能与 service 通信。
- 创建 overlay 网络
要使用服务发现,需要相互通信的 service 必须属于同一个 overlay 网络,所以我们先得创建一个新的 overlay 网络。
docker network create --driver overlay myapp_net
直接使用 ingress 行不行?很遗憾,目前 ingress 没有提供服务发现,必须创建自己的 overlay 网络。
- 部署 service 到 overlay
部署一个 web 服务,并将其挂载到新创建的 overlay 网络。
docker service create --name my_web --replicas=3 --network myapp_net httpd
部署一个 util 服务用于测试,挂载到同一个 overlay 网络。
docker service create --name util --network myapp_net busybox sleep 10000000
sleep 10000000 的作用是保持 busybox 容器处于运行的状态,我们才能够进入到容器中访问 service my_web。
- 验证
通过 docker service ps util 确认 util 所在的节点为node1。登录到 swarm-worker1,在容器 util.1 中 ping 服务 my_web。
# docker exec util.1.irfxosry2tzefrmvchqyanari ping -c 3 my_web
PING my_web (10.0.0.5): 56 data bytes
64 bytes from 10.0.0.5: seq=0 ttl=64 time=0.142 ms
64 bytes from 10.0.0.5: seq=1 ttl=64 time=0.104 ms
64 bytes from 10.0.0.5: seq=2 ttl=64 time=0.092 ms
可以看到 my_web 的 IP 为 10.0.0.2,这是哪个副本的 IP 呢?
其实哪个副本的 IP 都不是。10.0.0.2 是 my_web service 的 VIP(Virtual IP),swarm 会将对 VIP 的访问负载均衡到每一个副本。
我们可以执行下面的命令查看每个副本的 IP。
# docker exec util.1.irfxosry2tzefrmvchqyanari nslookup tasks.my_web
Server: 127.0.0.11
Address: 127.0.0.11:53
Non-authoritative answer:
Name: tasks.my_web
Address: 10.0.0.8
Name: tasks.my_web
Address: 10.0.0.7
Name: tasks.my_web
Address: 10.0.0.6
10.0.0.6、10.0.0.7、10.0.0.8 才是各个副本自己的 IP。不过对于服务的使用者(这里是 util.1),根本不需要知道 my_web副本的 IP,也不需要知道 my_web 的 VIP,只需直接用 service 的名字 my_web 就能访问服务。
滚动更新service
滚动更新降低了应用更新的风险,如果某个副本更新失败,整个更新将暂停,其他副本则可以继续提供服务。同时,在更新的过程中,总是有副本在运行的,因此也保证了业务的连续性。
下面我们将部署三副本的服务,镜像使用 httpd:2.2.31,然后将其更新到 httpd:2.2.32。
创建服务:
docker service create --name my_web --replicas=3 httpd:2.2.31
将 service 更新到 httpd:2.2.32:
docker service update --image httpd:2.2.32 my_web
--image 指定新的镜像。
Swarm 将按照如下步骤执行滚动更新:
1、停止第一个副本。
2、调度任务,选择 worker node。
3、在 worker 上用新的镜像启动副本。
4、如果副本(容器)运行成功,继续更新下一个副本;如果失败,暂停整个更新过程。
docker service ps 查看更新结果。默认配置下,Swarm 一次只更新一个副本,并且两个副本之间没有等待时间。我们可以通过 --update-parallelism 设置并行更新的副本数目,通过 --update-delay 指定滚动更新的间隔时间。
比如执行如下命令:
docker service update --replicas 6 --update-parallelism 2 --update-delay 1m30s my_web
service 增加到六个副本,每次更新两个副本,间隔时间一分半钟。docker service inspect 查看 service 的当前配置。
Swarm 还有个方便的功能是回滚,如果更新后效果不理想,可以通过 --rollback 快速恢复到更新之前的状态。请注意,--rollback 只能回滚到上一次执行 docker service update 之前的状态,并不能无限制地回滚。
docker service update --rollback my_web
管理数据
service 的容器副本会 scale up/down,会 failover,会在不同的主机上创建和销毁,这就引出一个问题,如果 service 有要管理的数据,那么这些数据应该如何存放呢?
选项一:打包在容器里。
显然不行。除非数据不会发生变化,否则,如何在多个副本直接保持同步呢?
选项二:数据放在 Docker 主机的本地目录中,通过 volume 映射到容器里。
位于同一个主机的副本倒是能够共享这个 volume,但不同主机中的副本如何同步呢?
选项三:利用 Docker 的 volume driver,由外部 storage provider 管理和提供 volume,所有 Docker 主机 volume 将挂载到各个副本。
这是目前最佳的方案。volume 不依赖 Docker 主机和容器,生命周期由 storage provider 管理,volume 的高可用和数据有效性也全权由 provider 负责,Docker 只管使用。
replicated mode VS global mode
Swarm 可以在 service 创建或运行过程中灵活地通过 --replicas 调整容器副本的数量,内部调度器则会根据当前集群的资源使用状况在不同 node 上启停容器,这就是 service 默认的 replicated mode。在此模式下,node 上运行的副本数有多有少,一般情况下,资源更丰富的 node 运行的副本数更多,反之亦然。
除了 replicated mode,service 还提供了一个 globalmode,其作用是强制在每个 node 上都运行一个且最多一个副本。
此模式特别适合需要运行 daemon 的集群环境。比如要收集所有容器的日志,就可以 global mode 创建 service,在所有 node 上都运行 gliderlabs/logspout 容器,即使之后有新的 node 加入,swarm 也会自动在新 node 上启动一个 gliderlabs/logspout 副本。
docker service create \
> --mode global \
> --name logspout \
> --mount type=bind,source=/var/run/docker.sock,destination=/var/run/docker.sock \
> gliderlabs/logspout
可以通过 docker service inspect 查看 service 的 mode。
# docker service inspect logspout --pretty
ID: bj4kj5c2egao5zu7c42tjc7uz
Name: logspout
Service Mode: Global
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: gliderlabs/logspout:latest@sha256:90847ec896aa9f96cd558afc80e690a48d4861f4a54f92f1d56efd3ade1e5b3a
Init: false
Mounts:
Target: /var/run/docker.sock
Source: /var/run/docker.sock
ReadOnly: false
Type: bind
Resources:
Endpoint Mode: vip
这里是 Global,如果创建 service 时不指定,默认是 Replicated。
使用Label控制service的位置
使用 label可以精细控制 Service 的运行位置呢。
逻辑分两步:
1、为每个 node 定义 label。
2、设置 service 运行在指定 label 的 node 上。
label 可以灵活描述 node 的属性,其形式是 key=value,用户可以任意指定,例如将 swarm-worker1 作为测试环境,为其添加 label env=test:
docker node update --label-add env=test swarm-worker1
对应的,将 swarm-worker2 作为生产环境,添加 label env=prod:
docker node update --label-add env=prod swarm-worker2
现在部署 service 到测试环境:
docker service create \
--constraint node.labels.env==test \
--replicas 3 \
--name my_web \
--publish 8080:80 \
httpd
--constraint node.labels.env==test 限制将 service 部署到 label=test 的 node,即 swarm-worker1。
更新 service,将其迁移到生产环境:
docker service update --constraint-rm node.labels.env==test my_web
docker service update --constraint-add node.labels.env==prod my_web
删除并添加新的 constraint,设置 node.labels.env==prod,最终所有副本都迁移到了 swarm-worker2。
label 还可以跟 global 模式配合起来使用,比如只收集生产环境中容器的日志。
docker service create \
--mode global \
--constraint node.labels.env==prod \
--name logspout \
--mount type=bind,source=/var/run/docker.sock,destination=/var/run/docker.sock \
gliderlabs/logspout
只有 swarm-worker2 节点上才会运行 logspout。
配置Health Check
Docker 只能从容器启动进程的返回代码判断其状态,而对于容器内部应用的运行情况基本没有了解。
执行 docker run 命令时,通常会根据 Dockerfile 中的 CMD 或 ENTRYPOINT 启动一个进程,这个进程的状态就是 docker ps STATUS 列显示容器的状态。
命令显示:
1、有的容器正在运行,状态为 UP。
2、有的容器已经正常停止了,状态是 Exited (0)。
3、有的则因发生故障停止了,退出代码为非 0,例如 Exited (137)、Exited (1) 等。
Docker 支持的 Health Check 可以是任何一个单独的命令,Docker 会在容器中执行该命令,如果返回 0,容器被认为是 healthy,如果返回 1,则为 unhealthy。
对于提供 HTTP 服务接口的应用,常用的 Health Check 是通过 curl 检查 HTTP 状态码,比如:
curl --fail http://localhost:8080/ || exit 1
如果 curl 命令检测到任何一个错误的 HTTP 状态码,则返回 1,Health Check 失败。
下面我们通过例子来演示 Health Check 在 swarm 中的应用。
docker service create --name my_db \
--health-cmd "curl --fail http://localhost:8091/pools || exit 1" \
couchbase
--health-cmd Health Check 的命令,还有几个相关的参数:
--timeout 命令超时的时间,默认 30s。
--interval 命令执行的间隔时间,默认 30s。
--retries 命令失败重试的次数,默认为 3,如果 3 次都失败了则会将容器标记为 unhealthy。swarm 会销毁并重建 unhealthy 的副本。
使用Secret
我们经常要向容器传递敏感信息,最常见的莫过于密码了。比如:
docker run -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql
在启动 MySQL 容器时我们通过环境变量 MYSQL_ROOT_PASSWORD 设置了 MySQL 的管理员密码。不过密码是以明文的形式写在 docker run 命令中,有潜在的安全隐患。
为了解决这个问题,docker swarm 提供了 secret 机制,允许将敏感信息加密后保存到 secret 中,用户可以指定哪些容器可以使用此 secret。
如果使用 secret 启动 MySQL 容器,方法是:
1、在 swarm manager 中创建 secret my_secret_data,将密码保存其中。
echo "my-secret-pw" | docker secret create my_secret_data -
2、启动 MySQL service,并指定使用 secret my_secret_data。
docker service create \
--name mysql \
--secret source=my_secret_data,target=mysql_root_password \
-e MYSQL_ROOT_PASSWORD_FILE="/run/secrets/mysql_root_password" \
mysql:latest
① source 指定容器使用 secret 后,secret 会被解密并存放到容器的文件系统中,默认位置为 /run/secrets/。--secret source=my_secret_data,target=mysql_root_password 的作用就是指定使用 secret my_secret_data,然后把器解密后的内容保存到容器 /run/secrets/mysql_root_password 文件中,文件名称 mysql_root_password 由 target 指定。
② 环境变量 MYSQL_ROOT_PASSWORD_FILE 指定从 /run/secrets/mysql_root_password 中读取并设置 MySQL 的管理员密码。
Secret使用场景
我们可以用 secret 管理任何敏感数据。这些敏感数据是容器在运行时需要的,同时我们不又想将这些数据保存到镜像中。
secret 可用于管理:
1、用户名和密码。
2、TLS 证书。
3、SSH 秘钥。
4、其他小于 500 KB 的数据。
secret 只能在 swarm service 中使用。普通容器想使用 secret,可以将其包装成副本数为 1 的 service。
这里我们再举一个使用 secret 的典型场景:
数据中心有三套 swarm 环境,分别用于开发、测试和生产。对于同一个应用,在不同的环境中使用不同的用户名密码。我们可以在三个环境中分别创建 secret,不过使用相同的名字,比如 username 和 password。应用部署时只需要指定 secret 名字,这样我们就可以用同一套脚本在不同的环境中部署应用了。
除了敏感数据,secret 当然也可以用于非敏感数据,比如配置文件。不过目前新版本的 Docker 提供了 config 子命令来管理不需要加密的数据。config 与 secret 命令的使用方法完全一致。
secret的安全性
当在 swarm 中创建 secret 时,Docker 通过 TLS 连接将加密后的 secret 发送给所以的 manager 节点。
secret 创建后,即使是 swarm manager 也无法查看 secret 的明文数据,只能通过 docker secret inspect 查看 secret 的一般信息。
只有当 secret 被指定的 service 使用是,Docker 才会将解密后的 secret 以文件的形式 mount 到容器中,默认的路径为/run/secrets/
当容器停止运行,Docker 会 unmount secret,并从节点上清除。
stack
stack 包含一系列 service,这些 service 组成了应用。stack 通过一个 YAML 文件定义每个 service,并描述 service 使用的资源和各种依赖。
WordPress 的 stack 版本
如果将前面 WordPress 用 stack 来定义,YAML 文件可以是这样:
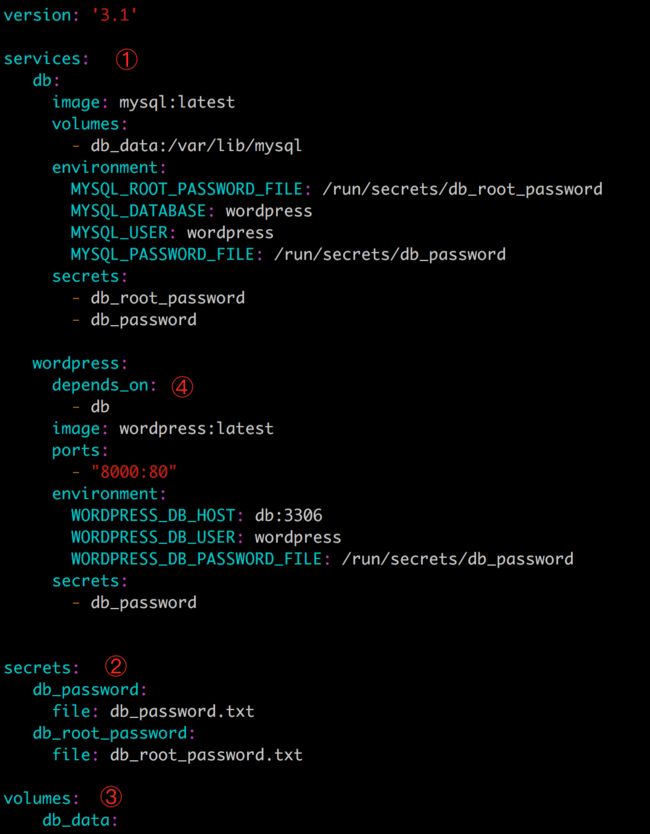
YAML 是一种阅读性很强的文本格式,上面这个 stack 中定义了三种资源:service、secret 和 volume。
① services 定义了两个 service:db 和 wordpress。
② secrets 定义了两个 secret:db_password 和 db_root_password,在 service db 和 wordpress 的定义中引用了这两个 secret。
③ volumes 定义了一个 volume:db_data,service db 使用了此 volume。
④ wordpress 通过 depends_on 指定自己依赖 db 这个 service。Docker 会保证当 db 正常运行后再启动 wordpress。
可以在 YAML 中定义的元素远远不止这里看到的这几个,完整列表和使用方法可参考文档 https://docs.docker.com/compose/compose-file/
stack的优点
stack 将应用所包含的 service,依赖的 secret、voluem 等资源,以及它们之间的关系定义在一个 YAML 文件中。相比较手工执行命令或是脚本,stack 有明显的优势。
1、YAML 描述的是 What,是 stack 最终要达到的状态。
比如 service 有几个副本?使用哪个 image?映射的端口是什么?而脚本则是描述如何执行命令来达到这个状态,也就是 How。显而易见,What 更直观,也更容易理解。至于如何将 What 翻译成 How,这就是 Docker swarm 的任务了,用户只需要告诉 Docker 想达到什么效果。
2、重复部署应用变得非常容易。
部署应用所需要的一切信息都已经写在 YAML 中,要部署应用只需一条命令 docker stack deploy。stack 的这种自包含特性使得在不同的 Docker 环境中部署应用变得极其简单。在开发、测试和生成环境中部署可以完全采用同一份 YAML,而且每次部署的结果都是一致的。
3、可以像管理代码一样管理部署。
YAML 本质上将应用的部署代码化了,任何对应用部署环境的修改都可以通过修改 YAML 来实现。可以将 YAML 纳入到版本控制系统中进行管理,任何对 YAML 的修改都会被记录和跟踪,甚至可以像评审代码一样对 YAML 执行 code review。应用部署不再是一个黑盒子,也不再是经验丰富的工程师专有的技能,所以的细节都在 YAML 中,清晰可见。