在GIS开发中,因为系统部署在内网,所以需要地图底图,目前主要是选择OpenStreetMap的地图和谷歌的地图,使用爬虫爬取地图的过程中,当增加线程数量时,OpenStreetMap明显越来越慢,就下载一个市的地图也要耗费很长时间,刚开始一个瓦片可能就0.2-0.5s,随运行时间边长,后面一张图需要10s左右。而google会好很多,google耗费几乎都是0.1s左右非常快,而且我几乎开了10个左右的线程。
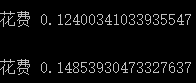
google瓦片请求时间
在下载地图的过程中遇到如下问题:
- 不使用线程时,要下载一个稍微大一点的范围需要下载时间非常长,特别是当层级大于15之后。
改进
修改为每一个层级一个线程。但是没有根本上解决。当在某个层级瓦片数量很大时,下载也会耗费很长时间。
想过根据瓦片数量来开启线程,分段下载,但是感觉计算逻辑复杂,到底多少数量开确认开启一个线程,这个需要不断的试。后来还是想起了java中的zookeeper。
zookeeper中存当前正在下载的瓦片如z1、x1、y1,每一个线程下载Zn,Xn,Yn的时候,都去ZooKeeper中查看一下,是否已经有线程在下载,如果有则下载下一个瓦片。这样可以同一个层上可以起任意个下载线程来满足需求。
以下是python中的步骤
zookeeper下载地址
zookeeper
- 解压zookeeper
- cd conf 修改zoo_sample.cfg 为 zoo.cfg
- 修改 zoo.cfg 中dataDir 路径
- ./zkServer.sh start #启动服务
- ./zkServer.sh status #查看启动状态
出现一下情况,说明启动成功
Client port found: 2181. Client address: localhost.
Mode: standalone
安装zkpython各种报错,切换为安装kazoo
pip install zkpython
pip install kazoo
以下是kazoo官方文档中的摘录
连接zookeeper
from kazoo.client import KazooClient
zk = KazooClient(hosts='127.0.0.1:2181')
zk.start()
zk.stop()
设置监听
from kazoo.client import KazooClient
from kazoo.client import KazooState
zk = KazooClient(hosts='127.0.0.1:2181')
def my_listener(state):
if state == KazooState.LOST:
# Register somewhere that the session was lost
print('Lost')
elif state == KazooState.SUSPENDED:
# Handle being disconnected from Zookeeper
print('SUSPENDED')
else:
# Handle being connected/reconnected to Zookeeper
print('CONNECTED')
zk.add_listener(my_listener)
zk.start()
zk.stop()
输出
CONNECTED
Lost
创建
#创建路径
zk.ensure_path("/my/favorite")
#创建节点
zk.create("/my/favorite/node", b"a value")
读取
# Determine if a node exists
if zk.exists("/my/favorite"):
# Do something
pass
# Print the version of a node and its data
data, stat = zk.get("/my/favorite")
print("Version: %s, data: %s" % (stat.version, data.decode("utf-8")))
# List the children
children = zk.get_children("/my/favorite")
print("There are %s children with names %s" % (len(children), children))
更新
zk.set("/my/favorite", b"some data")
删除
zk.delete("/my/favorite/node", recursive=True)
python实现思路
创建图层路径,用于存放正在下载的图层z、x、y
if not zk.exists('/tile'):
zk.ensure_path('/tile')
判断是否已经在下载
nodeName = '/tile/%s_%s_%s' % (z,x,y)
if zk is not None:
if zk.exists(nodeName):
print("%s %s %s 已经存在线程在下载。" % (z,x,y))
return
try:
zk.create(nodeName, b'1')
except NodeExistsError:
print("%s %s %s 已经被创建。" % (z,x,y))
return