距离上次发布文章有一段时间了,这次会带来之前答应大家源码剖析系列的文章。这个系列的文章更多的是对自己源码学习的一些总结,希望有共同爱好的同学能跟我一起交流,如果我有错误,向我指正。
这次我要写的源码剖析是近一两年非常火的网络框架---Retrofit2,虽然网上关于它的分析还是比较多的,但是每个人都有自己的一些理解和总结,所以最后我还是决定将它写出来。
我们首先看看Retrofit类,短短几百行的代码,还夹杂着一大堆的注释,可以说它的封装性是特别强的。首先我们看看Retrofit类的几个变量:
// 网络请求配置对象
// 作用:存储网络请求相关的配置,如解析网络请求的方法、数据转换器(Converter)、网络请求适配器(CallAdapter)、网络请求工厂(CallFactory)、基础地址(BaseUrl)等
private final Map> serviceMethodCache = new ConcurrentHashMap<>();
//网络请求器的工厂
//作用:生产网络请求器(Call)
//Retrofit是默认使用okhttp(后面会解释)
final okhttp3.Call.Factory callFactory;
//网络请求的基础url地址
final HttpUrl baseUrl;
//数据转换器工厂的集合
//作用:放置数据转换器工厂
//数据转换器工厂作用:生产数据转换器(converter)
final List converterFactories;
//网络请求适配器工厂的集合
//作用:放置网络请求适配器工厂
//网络请求适配器工厂作用:生产网络请求适配器(CallAdapter)
final List adapterFactories;
//回调方法执行器
final Executor callbackExecutor;
//标志位
//作用:是否提前对业务接口中的注解进行验证转换的标志位
final boolean validateEagerly;
可以看到,Retrofit类的变量并不多,下面我们看看构造函数:
//构造函数
Retrofit(okhttp3.Call.Factory callFactory, HttpUrl baseUrl,
List converterFactories, List adapterFactories,
@Nullable Executor callbackExecutor, boolean validateEagerly) {
this.callFactory = callFactory;
this.baseUrl = baseUrl;
this.converterFactories = unmodifiableList(converterFactories); // Defensive copy at call site.
this.adapterFactories = unmodifiableList(adapterFactories); // Defensive copy at call site.
this.callbackExecutor = callbackExecutor;
this.validateEagerly = validateEagerly;
}
其实就是对Retrofit的几个变量做了赋值。
下面我们来看看整个Retrofit的创建流程:

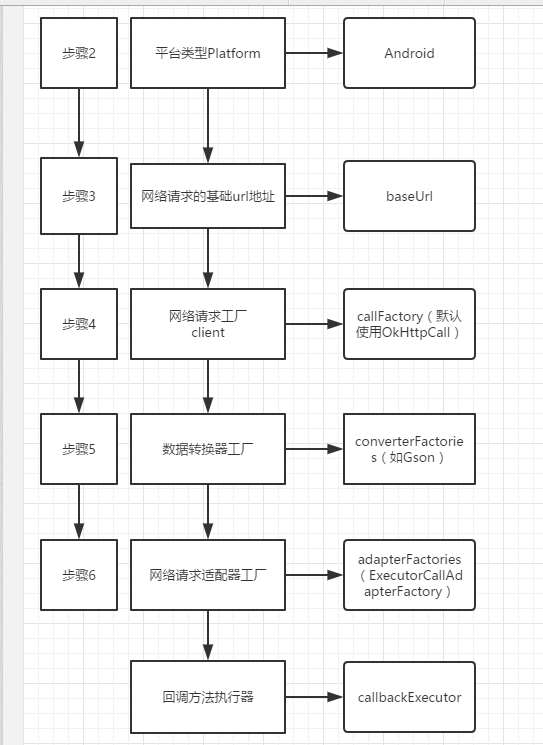
步骤2:

上面我们已经看过Retrofit的构造函数了,所以可以省略步骤1,那下面我们就开始看看步骤2,Retrofit的Builder这个类的构成:
//Builder类
public static final class Builder {
//平台
private final Platform platform;
//一下几个变量与Retrofit的构造函数大致相同
private okhttp3.Call.Factory callFactory;
private HttpUrl baseUrl;
private final List converterFactories = new ArrayList<>();
private final List adapterFactories = new ArrayList<>();
private Executor callbackExecutor;
private boolean validateEagerly;
Builder(Platform platform) {
this.platform = platform;
converterFactories.add(new BuiltInConverters());
}
//构造函数
public Builder() {
this(Platform.get());
}
}
我们可以看到Builder类除了Platform之外,其他几个变量我们都在前面见过,那究竟Platform是什么呢,我们来解密一下,首先我查了一下翻译,Platform是“平台”的意思,查了翻译我们就知道大概了,因为我们知道Retrofit支持不单止Android一个平台,那下面我们就来看看Platform类:
class Platform {
private static final Platform PLATFORM = findPlatform();
static Platform get() {
return PLATFORM;
}
private static Platform findPlatform() {
try {
// Class.forName(xxx.xx.xx)的作用:要求JVM查找并加载指定的类
Class.forName("android.os.Build");
if (Build.VERSION.SDK_INT != 0) {
// 如果是Android平台,就创建并返回一个Android对象
return new Android();
}
} catch (ClassNotFoundException ignored) {
}
try {
Class.forName("java.util.Optional");
// 如果是Java平台,就创建并返回一个Java8对象
return new Java8();
} catch (ClassNotFoundException ignored) {
}
return new Platform();
}
Executor defaultCallbackExecutor() {
return null;
}
CallAdapter.Factory defaultCallAdapterFactory(Executor callbackExecutor) {
if (callbackExecutor != null) {
return new ExecutorCallAdapterFactory(callbackExecutor);
}
return DefaultCallAdapterFactory.INSTANCE;
}
// 用于接收服务器返回数据后进行线程切换在主线程显示结果
static class Android extends Platform {
@Override public Executor defaultCallbackExecutor() {
return new MainThreadExecutor();
}
@Override CallAdapter.Factory defaultCallAdapterFactory(Executor callbackExecutor) {
return new ExecutorCallAdapterFactory(callbackExecutor);
}
static class MainThreadExecutor implements Executor {
// 获取与Android 主线程绑定的Handler
private final Handler handler = new Handler(Looper.getMainLooper());
@Override public void execute(Runnable r) {
// 该Handler是上面获取的与Android 主线程绑定的Handler
// 在UI线程进行对网络请求返回数据处理等操作。
handler.post(r);
}
}
}
}
上面看完Platform类的findPlatform()方法之后,我们就很清楚的知道这个版本的Retrofit2.0是支持Android和Java平台的,此外,在Retrofit2其他版本中还会支持IOS的版本,在这个版本被去掉了。看源码重要的是在看完源码后能获取一些收获,所以像Retrofit这个这么成功的框架中我们需要去领会到它一些代码的写法。譬如在Platform这个类中,我们以后想做到分情况考虑的时候,也可以用像findPlatform()方法的这种实现(用了两个Class.forName(xxx.xx.xx)的方法就很好的区分了使用的平台),简洁而且实用。
我们可以看到其实步骤2的Builder类最特别的Platform分析完毕之后,步骤2就基本分析完了。这里的Retrofit使用了建造者模式,我们下面再做详细的分析。
下面我们看看步骤3:
步骤3:

public Builder baseUrl(String baseUrl) {
checkNotNull(baseUrl, "baseUrl == null");
HttpUrl httpUrl = HttpUrl.parse(baseUrl);
if (httpUrl == null) {
throw new IllegalArgumentException("Illegal URL: " + baseUrl);
}
return baseUrl(httpUrl);
}
public Builder baseUrl(HttpUrl baseUrl) {
checkNotNull(baseUrl, "baseUrl == null");
List pathSegments = baseUrl.pathSegments();
//注意点1
if (!"".equals(pathSegments.get(pathSegments.size() - 1))) {
throw new IllegalArgumentException("baseUrl must end in /: " + baseUrl);
}
this.baseUrl = baseUrl;
//注意点2
return this;
}
我们可以看到,代码很简单,就是两个方法,至于看到方法名大家更加清楚明白,这是一个设置基础URL的方法。上面我们只需要关注两个注意点:
1.baseUrl必须要以“/”结束,否则会抛出异常,其实他的源码注释也解释了一些特殊的情况。

2.return一个Builder类型,其实是建造者模式一个常用的手法,以供使用者很好的链式配置你想要的相关配置。
继续,步骤4:
步骤4(可选):

public Builder client(OkHttpClient client) {
//注意点1
return callFactory(checkNotNull(client, "client == null"));
}
public Builder callFactory(okhttp3.Call.Factory factory) {
this.callFactory = checkNotNull(factory, "factory == null");
return this;
}
我们都知道Retrofit其实只是名义上可以称为一个网络框架,但是其实,完成网络请求这块的功能并不是Retrofit,而是我们耳熟能详的OKhttp。关于步骤4,我们看到client()方法传的参数是OkHttpClient 就知道这里是配置一个OkHttp的OkHttpClient,其实Retrofit默认就是使用OKhttp作为他的网络请求的载体,所以如果对OKhttp没有特殊要求(如设置拦截器之类)的同学可以忽略步骤4。
注意点1:我们可以上面两个方法看到其实Retrofit类里面的callFactory指的就是OkHttpClient
步骤5,6:

//设置数据交换器
public Builder addConverterFactory(Converter.Factory factory) {
converterFactories.add(checkNotNull(factory, "factory == null"));
return this;
}
//设置网络请求适配器
public Builder addCallAdapterFactory(CallAdapter.Factory factory) {
adapterFactories.add(checkNotNull(factory, "factory == null"));
return this;
}
我们可以看到步骤5,6其实可以归到同一类去讲,就是添加适配器,我们更值得说的是,“···Factory”用的都是设计模式里面的工厂模式,而“···Adapter”用的就是设计模式里面的适配器模式。
步骤7:
public Retrofit build() {
if (baseUrl == null) {
throw new IllegalStateException("Base URL required.");
}
okhttp3.Call.Factory callFactory = this.callFactory;
if (callFactory == null) {
//注意点1
callFactory = new OkHttpClient();
}
Executor callbackExecutor = this.callbackExecutor;
// 如果没指定,则默认使用Platform检测环境时的默认callbackExecutor
// 即Android默认的callbackExecutor
if (callbackExecutor == null) {
callbackExecutor = platform.defaultCallbackExecutor();
}
List adapterFactories = new ArrayList<>(this.adapterFactories);
adapterFactories.add(platform.defaultCallAdapterFactory(callbackExecutor));
// 在步骤2中已经添加了内置的数据转换器BuiltInConverters()(添加到集合器的首位)
// 在步骤5中又插入了一个Gson的转换器 - GsonConverterFactory(添加到集合器的首二位)
List converterFactories = new ArrayList<>(this.converterFactories);
// 最终返回一个Retrofit的对象,并传入上述已经配置好的成员变量
return new Retrofit(callFactory, baseUrl, converterFactories, adapterFactories,
callbackExecutor, validateEagerly);
}
我们可以看到,步骤7也就是最后一步,是通过前面几步设置的变量,最后返回一个新的Retrofit对象,创建一个Retrofit实例,很明显,通过这几步的配置,是用了设计模式里面的建造者模式,当然在这里我们又学到了,当我们自定义东西的时候,通过建造者模式,我们可以灵活的配置自己想要的东西,而不是一味的把代码写死,每次都是需要触碰到源代码的修改,适当的使用设计模式,会使你的代码更加灵活。
总结:
上面我们看完了Retrofit是怎么配置参数源码,我们大致了解Retrofit是怎么进行初始化的,下面我们看看Retrofit在使用时是怎么运作的:
//步骤1
//Retrofit与很多网络框架不一样,使用前是需要先设置好JavaBean
public class WXItemBean {
}
//步骤2 定义网络请求的接口类
public interface TestApi {
//注解GET:采用Get方法发送网络请求
@GET("wxnew")
rx.Observable>> getWXHot(@Query("key") String key, @Query("num") int num, @Query("page") int page);
}
//步骤3 创建接口类实例
testApi = retrofit.create(TestApi.class);
//步骤4 网络请求
Subscription subscribe = testApi.getWXHot(key, num, page)
.compose(RxUtil.>>rxSchedulerHelper())
.compose(RxUtil.>handleResult1())
.subscribe(new BaseSubscriber1>() {
@Override
public void onNextT(List wxItemBeen) {
mView.testSuccess(wxItemBeen);
}
@Override
public void onErrorT(String msg) {
}
});
addSubscrebe(subscribe);
下面我们主要来分析一下步骤3,也就是create()。在介绍这个方法之前,我先告诉大家这个方法使用了设计模式的外观模式(大大降低了耦合度)和代理模式,其中代理模式用的是动态代理,什么是动态代理?其实Java早已经帮我们封装好了方法,我们来举个栗子:
public interface ITest
{
@GET("/wx")
public void add(int a, int b);
}
public static void main(String[] args)
{
ITest iTest = (ITest) Proxy.newProxyInstance(ITest.class.getClassLoader(), new Class[]{ITest.class}, new InvocationHandler()
{
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable
{
Integer a = (Integer) args[0];
Integer b = (Integer) args[1];
System.out.println("方法名:" + method.getName());
System.out.println("参数:" + a + " , " + b);
GET get = method.getAnnotation(GET.class);
System.out.println("注解:" + get.value());
return null;
}
});
iTest.add(3, 5);
}
结果为:
方法名:add
参数:3 , 5
注解:/wx
是不是觉得很神奇?有了这个例子我们接下来就很好理解create()方法了。
public T create(final Class service) {
Utils.validateServiceInterface(service);
//判断是否需要提前验证
if (validateEagerly) {
eagerlyValidateMethods(service);
}
// 创建了网络请求接口的动态代理对象,即通过动态代理创建网络请求接口的实例 (并最终返回)
// 该动态代理是为了拿到网络请求接口实例上所有注解
return (T) Proxy.newProxyInstance(service.getClassLoader(), new Class[] { service },
new InvocationHandler() {
private final Platform platform = Platform.get();
@Override public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
// If the method is a method from Object then defer to normal invocation.
if (method.getDeclaringClass() == Object.class) {
return method.invoke(this, args);
}
if (platform.isDefaultMethod(method)) {
return platform.invokeDefaultMethod(method, service, proxy, args);
}
//注意点1
ServiceMethod serviceMethod =
(ServiceMethod) loadServiceMethod(method);
//注意点2
OkHttpCall 很明显,我们看到create()方法最核心的东西是使用了动态代理的Proxy.newProxyInstance()方法,通过代理模式中的动态代理模式,动态生成网络请求接口的代理类,并将代理类的实例创建交给InvocationHandler类 作为具体的实现,并最终返回一个动态代理对象。而Proxy.newProxyInstance()方法的核心正正是我们标注的注意点1,2,3。我可以这样说,Retrofit这个框架运作的时候,最核心的就是我们看到的这三句话。
我们首先来看看注意点1:
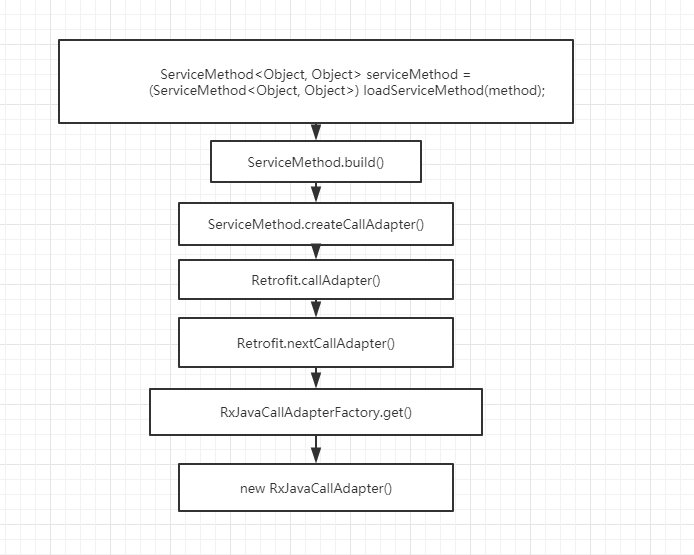
ServiceMethod serviceMethod = (ServiceMethod) loadServiceMethod(method);
我们来看看loadServiceMethod(method)这个方法:
ServiceMethod loadServiceMethod(Method method) {
//获取缓存
ServiceMethod result = serviceMethodCache.get(method);
if (result != null) return result;
设置同步锁
synchronized (serviceMethodCache) {
//获取缓存
result = serviceMethodCache.get(method);
//如果没有缓存,则创建一个新的ServiceMethod实例
if (result == null) {
result = new ServiceMethod.Builder<>(this, method).build();
serviceMethodCache.put(method, result);
}
}
return result;
}
那下面我们来看看ServiceMethod又是怎么创建出来的:
首先看看ServiceMethod的构造函数:
ServiceMethod(Builder builder) {
this.callFactory = builder.retrofit.callFactory();
this.callAdapter = builder.callAdapter;
this.baseUrl = builder.retrofit.baseUrl();
this.responseConverter = builder.responseConverter;
this.httpMethod = builder.httpMethod;
this.relativeUrl = builder.relativeUrl;
this.headers = builder.headers;
this.contentType = builder.contentType;
this.hasBody = builder.hasBody;
this.isFormEncoded = builder.isFormEncoded;
this.isMultipart = builder.isMultipart;
this.parameterHandlers = builder.parameterHandlers;
}
我们可以看到在ServiceMethod设置了各种不同的网络参数,然后我们看看Builder<>(this, method)这个方法:
Builder(Retrofit retrofit, Method method) {
this.retrofit = retrofit;
this.method = method;
// 网络请求接口方法里的注释(如@GET("wxnew"))
this.methodAnnotations = method.getAnnotations();
// 网络请求接口方法里的参数类型
this.parameterTypes = method.getGenericParameterTypes();
//网络请求接口方法里的注解内容
this.parameterAnnotationsArray = method.getParameterAnnotations();
}
接下来我们看看建造者模式的最后一步build()方法:
public ServiceMethod build() {
//注意点1,从Retrofit对象中获取对应的网络请求适配器
callAdapter = createCallAdapter();
// 根据网络请求接口方法的返回值和注解类型,从Retrofit对象中获取该网络适配器返回的数据类型
responseType = callAdapter.responseType();
if (responseType == Response.class || responseType == okhttp3.Response.class) {
throw methodError("'"
+ Utils.getRawType(responseType).getName()
+ "' is not a valid response body type. Did you mean ResponseBody?");
}
responseConverter = createResponseConverter();
for (Annotation annotation : methodAnnotations) {
// 解析获取Http请求的方法,如GET、POST、HEAD
parseMethodAnnotation(annotation);
}
int parameterCount = parameterAnnotationsArray.length;
parameterHandlers = new ParameterHandler[parameterCount];
// 为方法中的每个参数创建一个ParameterHandler对象并解析每个参数使用的注解类型
// 该对象的创建过程就是对方法参数中注解进行解析
// 这里的注解包括:Body、PartMap、Part、FieldMap、Field、Header、QueryMap、Query、Path、Url
for (int p = 0; p < parameterCount; p++) {
Type parameterType = parameterTypes[p];
if (Utils.hasUnresolvableType(parameterType)) {
throw parameterError(p, "Parameter type must not include a type variable or wildcard: %s",
parameterType);
}
//最后创建一个新的ServiceMethod实例
return new ServiceMethod<>(this);
}
我们看看注意点1,在ServiceMethod 中是如何创建CallAdapter的:
private CallAdapter createCallAdapter() {
Type returnType = method.getGenericReturnType();
if (Utils.hasUnresolvableType(returnType)) {
throw methodError(
"Method return type must not include a type variable or wildcard: %s", returnType);
}
if (returnType == void.class) {
throw methodError("Service methods cannot return void.");
}
Annotation[] annotations = method.getAnnotations();
try {
//调用Retrofit类里面的callAdapter方法
return (CallAdapter) retrofit.callAdapter(returnType, annotations);
} catch (RuntimeException e) { // Wide exception range because factories are user code.
throw methodError(e, "Unable to create call adapter for %s", returnType);
}
}
public CallAdapter callAdapter(Type returnType, Annotation[] annotations) {
return nextCallAdapter(null, returnType, annotations);
}
public CallAdapter nextCallAdapter(CallAdapter.Factory skipPast, Type returnType,
Annotation[] annotations) {
checkNotNull(returnType, "returnType == null");
checkNotNull(annotations, "annotations == null");
int start = adapterFactories.indexOf(skipPast) + 1;
for (int i = start, count = adapterFactories.size(); i < count; i++) {
CallAdapter adapter = adapterFactories.get(i).get(returnType, annotations, this);
if (adapter != null) {
return adapter;
}
}
}
在上面这段代码中,通过遍历adapterFactories并根据我们的接口方法所中返回值类型来获取响应的适配器callAdapter。例如上面的例子中返回值是一个Call对象,将会采用默认的适配器,如果我们返回的是RxJava中Observable对象,如果我们添加了RxJavaCallAdapterFactory,那么返回的就是RxJavaCallAdapter。如果没有添加那么此处的adapter为null,便会抛出异常。

当我们初始配置的时候设置多个CallAdapterFactory,Retrofit会根据返回不同的对象,返回相应的CallAdapter。
ConverterFactory和CallAdapterFactory的创建原理基本一样,所以这里不多说。
下面我们看看整个CallAdapter创建的流程图:
注意点1总结:
看完ServiceMethod这个类,我们就发现,这是一个非常非常重要的类,它把所有有关网络请求method,都转换成了Call的信息。
那下面我们看看注意点2
OkHttpCallpublic class OkHttpCall {
private final ServiceMethod serviceMethod; // 含有所有网络请求参数信息的对象
private final Object[] args; // 网络请求接口的参数
private okhttp3.Call rawCall; //实际进行网络访问的类
private Throwable creationFailure;
private boolean executed;
private volatile boolean canceled;
//构造函数
public OkHttpCall(ServiceMethod serviceMethod, Object[] args) {
// 传入ServiceMethod对象和请求参数
this.serviceMethod = serviceMethod;
this.args = args;
}
我们知道Retrofit实际上是用okhttp做网络请求的,所以这句话大家都很清楚,把刚刚配置的ServiceMethod对象传进OkHttpCall,并创建一个事例。
注意点3:
return serviceMethod.callAdapter.adapt(okHttpCall);
看到adapt()这个方法,我们大家都懂,就是用callAdapter去绑定okHttpCall。那下面我们再看adapt()这个方法到底做了什么:
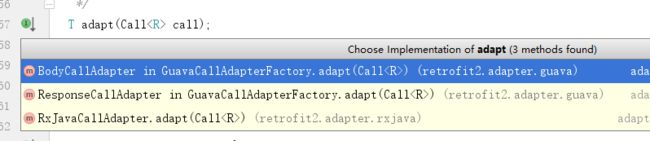
这里有三种不用的CallAdapter,我们使用的是RxJavaCallAdpter,所以点进去看看:
@Override public Object adapt(Call call) {
//判断是同步还是异步请求,创建不同的OnSubscribe
OnSubscribe> callFunc = isAsync
? new CallEnqueueOnSubscribe<>(call)
: new CallExecuteOnSubscribe<>(call);
OnSubscribe func;
if (isResult) {
func = new ResultOnSubscribe<>(callFunc);
} else if (isBody) {
func = new BodyOnSubscribe<>(callFunc);
} else {
func = callFunc;
}
Observable observable = Observable.create(func);
if (scheduler != null) {
observable = observable.subscribeOn(scheduler);
}
···
return observable;
}
最后是返回一个Observable对象。
大致源码我们都看过分析过了,不清楚的流程的同学可以看看下面的流程图:
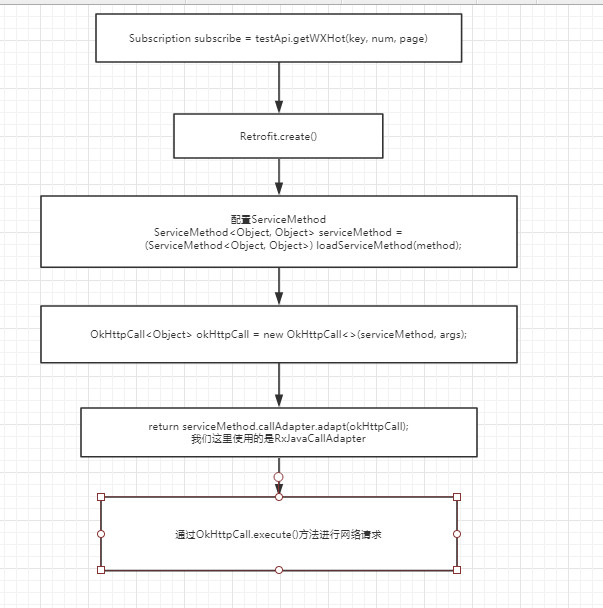
有同学可能最后会觉得有点奇怪,流程图的最后一步调用的是OkHttpCall.execute()(同步)方法,而不是使用OkHttpCall.enqueue()(异步)方法,为什么会这样呢?其实当Retrofit自己单独用的时候,网络请求确实调用的是OkHttpCall.enqueue()方法,但是当与RxJava一起使用的时候,Retrofit将切换线程这个工作交给了RxJava完成,所以Retrofit调用的是OkHttpCall.execute()方法,这点也是自己慢慢断点和一位师兄的提点才发现的。
从源码角度看,Retrofit更多算是一个封装库,把很多各种各样的框架连接在一起的桥梁,其中用了很多设计模式去封装,为大家带来了便捷。对于我来说,看完源码之后发现还是很多细节没弄懂,也促使自己慢慢去学习去探索,第一次发表关于源码的文章可能很多东西都有不足之处,希望大家一起指正我,跟我交流,大家一起成长!
基于以下项目讲解:
手把手为你封装一个MVP+RxJava+Retrofit2+Dagger2+BaseRecyclerView快速开发框架,两周一个版本不是梦
基于以下几位大神的文章编写:
Android:手把手带你深入剖析 Retrofit 2.0 源码
Retrofit2 完全解析 探索与okhttp之间的关系
Retrofit2.0源码解析
几个月前我在一个朋友的毕业照上再次遇到了她,其实我到现在也想不懂当初为什么会去参加。从那时候起,我就有了一种奇怪的感觉,大概那种就叫好感吧?但事以愿为,我来迟了。。。那一刻我在想,之前有多少次机会能拿到她的联系方式呢,最后因为自己的问题一次又一次的错过了。我很懊恼,那一晚我已经数不清重播了多少次《单城双恋》里面陈展鹏唱的那首《差半步》。虽然她平时很少跟我分享她开心、伤心的事,她也从来不告诉我她喜欢什么,但是我觉得能跟她普通的聊聊天我已经很知足了(她经常说知足常乐)。她说过她是一个比较特立独行的女孩,我也知道她外里总给人一种很坚强、独立的感觉,但是我觉得她的内心更需要别人的呵护、关心和督促。我很想成为那个当她迷路彷徨无助时帮助呵护她的人,很想成为那个当她伤心失落时陪伴关心她的人,也很想成为那个当她每晚晚睡督促她早睡的人。重遇她我改变了很多,以前别人都说我闷骚,现在哪怕遇到陌生人我也会慢慢试着表现自己。现在的我也敢于尝试很多东西,因为我不想再错过什么而让自己未来会后悔的事。重遇她,我才发现自己要努力成为一个优秀的人。不管以后怎样,我都希望笨笨的她能得到幸福,每天开开心心,她的学生不要欺负她,惹她生气。虽然昨天才是教师节,可能昨天赶不出文章是一个缩影,但是我也想给她一个迟来的祝福,教师节快乐!