摘要:8月24日阿里云数据库技术峰会上,来自阿里数据库事业部高级专家钟宇带来HiTSDB 时序数据库方面的演讲。本文主要从时序数据开始介绍,包括时序序列数据的特点,接着介绍了时序数据业务场景,以及OpenTSDB在HBase上的优化,最后分享了HiTSDB的优化和提高。
时序数据介绍
时序数据就是在时间上分布的一系列数值,时间和数值是两个关键字,时序数据一般指指标型数据,比如股票价格、广告数据、气温变化、网站的PV/UV、个人健康数据、工业传感器数据,还有关于应用程序的性能监控,像服务器系统监控数据,比如cpu和内存占用率,此外还有车联网。
据统计,在大数据领域中时序数据会超过一半。

图为广告的监测数据,可以看到事例中跟踪了三个广告来源,每个来源跟踪了三个指标,包括展示了多少次、点击了多少次以及产生了多少收入。广澳来源是用不同的标签来区分的,比如由谁发布、广告商、针对目标用户的性别和发布在哪个国家等。 大家可以清晰的看到每个指标,在不同的时间点有不同的数值,这就构成了一系列的时间数据。左边成为数据源,中间成为metric,右边称为时间序列,时间序列在时间上具有不同的值,

如果对时间序列建模会有两种方式,一种是单值,一种是多值。单值是把每一个数据源的每一个指标的每一个值当成一行。多值模型是把同一个数据源的不同指标放在不同列中,也就是每个数据源在每个时间点只会产生一行数据。
多值模型一定能用单值模型来模拟,多值模型在处理某些数据时更方便些,但是单值建模可以模拟所有场景。
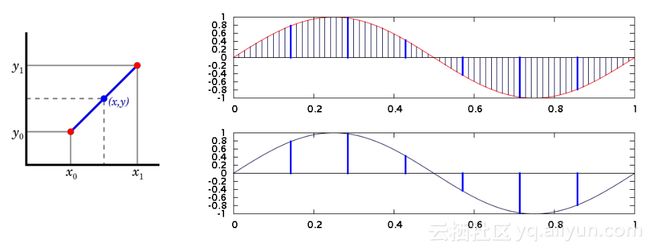
时间序列数据的处理和一般数据库处理有所不同,一般数据库基于行,每一个数据点是一行,时间序列数据是按时间线处理数据。每个时间线上的数据是非常关联的,比如某一个广告源收入在不同时间上就构成时间序列,这些时间序列中的收入可以画成一条变化曲线,针对曲线我们可以做时间序列变化处理,最常见的是插值和降精度。由于数据源采样的原因,往往会丢失一些点,我们用插值在中间插上常见的线性插值或者零值补偿;如果广告数据不一定需要最细时间粒度来看,我们就可以降精度,不同数据降精度的方式不一样。

针对时间数据,还有一个最常见的处理——聚合,我们往往看的不仅仅是从一个数据源来的指标,如果我们要看北美地区某一个广告源在一段时间内产生的所有收入的总和,我们就需要把跟广告源标签对应的时间线全部挑出来,然后将广告收入时间点加和在一起,得到一个新的求和曲线,如图所示,我们找到了非常多的时间线,最后用某种聚合函数聚合在一起。每一种业务需要的聚合方式也是不一样的,比如广告数据算加和,或者按广告源作平均,也有可能找最大最小值,或者作统计性事情,比如99%值都在某个数值以上。
时间序列数据的特点
因此,我们得出时间序列特点包括以下几方面:
1. 持续产生大量数据。不论是广告监控还是传感器、气温,它针对的情况很多。比如监控工业园区中灯的耗电量,每盏灯就会有传感器实时传输灯耗电量,如果采样间隔是一秒钟,每盏灯每一秒就会产生一个数据点,几万盏灯没秒就会有几万次写入,如果涉及楼宇多,就会产生每秒几百万上千万的写入。
2. 数据产生率平稳,无明显的波峰谷。这带来了优化的好处和坏处,好处是不会产生明显的峰值,所以在做容量评估时会比较方便;坏处是没办法在闲暇时间做数据合并和补偿的工作。
3. 近期的数据关注度更高。
4. 时间久远的数据,极少被访问,甚至不再需要。所以时间序列数据一般需要数据回滚功能。
5. 数据存在多个维度的标签。
6. 展示或使用时往往需要对数据做聚合计算。
时序数据业务场景
阿里巴巴鹰眼系统
阿里巴巴鹰眼系统能跟踪一个分布式系统的系统调用情况,其中就有监控应用指标。包括系统内存处理器占用以及应用本身的TPS和QPS,在实际内部的阿里巴巴系统中,去年的写入峰值是570万点/秒,平均写入350万点/秒,产生了上万个不同的metric,几千万个时间序列,每个时间序列平均有5个维度(tags),每秒几百次聚合展示。
阿里巴巴智慧园区
还有物联网方面,物联网数据与系统监控很像,你可以把设备中的传感器想象成服务器应用的不同指标,比如每盏灯、每个空调出风口的温度等都有指标,阿里巴巴接入的数据跨越两个城市,三个园区,有数以万计的设备,每秒产生数百万的采集点,要求数据写入立即可用。
当传统数据库遇到时间序列数据

时间序列数据存到传统数据库中会遇到一些问题,例如时间序列数据直接保存到关系数据库中(例如MySQL 的InnoDB引擎),使用SQL语句进行分析。这里就会遇到以下一些问题:
1. tag重复存储,存储开销大,如果将模型变成MySQL的行时,每个数据点会产生独立的行,也就是标签会重复存储,在一个时间序列上每个数据点需要保存到标签重复存储一遍,这样才能用标签把这个序列上所有的数据点找出来。
2. 可以用联合索引部分解决多维度的问题,但是进一步增加了存储的开销。
3. B树索引在持续写入的时候产生大量随机IO,写性能迅速下降,多联合索引加剧了写入慢的问题,InnoDB是用B+Tree进行索引的,为了数据查询快,一般会根据标签不同组合建立不同索引,当写入数据时,不同标签写进去的数据排序是不一样的,大部分的标签在写进去时会在索引上产生随机插入。
4. 数据量大导致索引/数据很容易超过内存容量,查找/聚合性能不高。查询时会导致大量的磁盘IO的开销。
5. 降精度的SQL子查询很难被SQL优化器优化。
OpenTSDB在HBase上的优化

OpenTSDB时间序列数据库架构如图所示,它的存储基于HBase,HBase具有高性能,可以线性扩展。TSD被设计为无状态节点,任何一个节点可以随时替换另一个节点进行服务,对外提供的RPC协议是HTTP/Json接口,很方便使用。TSD依赖HBase解决一致性,当TSD产生写时,它一定会将写及时更新到HBase, 而产生读不命中时候,也会从HBase中将数据读回来。

OpenTSDB 存储格式如图所示,它的存储上做了很多针对时序的考虑和优化。
1. 最核心的点是将Tags压缩,将tags分成两个级别,第一个级别有一个表将tags转换成 id,所有的tags id和指标的名称以及时间一起被组合成row key,row key实际上是OpenTSDB保存的行键,每一行中重复存储只有row key,row key 实际上是每一个tags都被转换成了整型,row key 相对来说比较短。
2. 每个row key对应时间序列+一个时间戳,时间序列上的数据一直存在时间序列之上,理论上row key 不需要重复保存,所以一个小时的数据保存在同一行里,OpenTSDB的存储格式中每一行有3600个列,每个列对应一个小时内的点,而这一小时的时间边界、指标名称、id一起构成了row key。row key重复存储的空间就变成了按行设计的1/3600,大大地压缩了row key。
3. Row key的构建也经过了很好的设计,时间位于metric和tags之间,不需要预先定义数据格式,保证了灵活性;tags扫描时候,我们经常遇到的场景是聚合,需要找到某个tags的一系列时间线,OpenTSDB场景中,在tags和搜索条件正好满足前缀规则时可以很好的优化,如果共有三个标签园区、楼、楼层构建row key,如果搜索园区,扫过的数据就是我们要的数据,别的园区数据就会排出掉,HBase常见的问题是产生热点,OpenTSDB用salt机制保证热点。
OpenTSDB的缺点
OpenTSDB也有很多缺点,具体如下:
1. 时间序列的Meta Data以缓存的方式在所有的TSD节点中存在,时间序列太多的时候内存压力很大
2. 以RowScan的方式做多维度查询,当查询条件不满足RowKey的前缀时,会扫过很多无用的RowKey
3. 在固定的Column中保存一小时内的时间点,Qualifier存在额外的开销
4. 单点聚合,容易出现聚合性能瓶颈(cpu&memory)
5. 通用压缩算法,压缩率依然不理想(每个数据点大约消耗20字节,包括了RowKey的开销)
HiTSDB的优化和提高
倒排索引
参考搜索引擎的倒排索引实现,每个时间序列作为一个文档,通过tags的倒排索引到时间序列ID,把timestamp + 时间序列ID作为RowKey,取代由timestamp + metric ID + tag IDs拼接成的RowKey。
使用倒排索引的解决的问题和对比如下:
1. 倒排索引在集群中的分片和一致性问题,解决办法:BinLog写入到HDFS,每个分片一个BinLog文件
2. 分片策略的问题:按metric,按特定的tag,还是按metric+tags?
3. 倒排索引加速了多维度的任意条件查询
4. 倒排索引可以方便的实现metric和tagkey/tag value的输入提示
5. RowScan vs mget
6. 从HBase读取数据是瓶颈,包括网络吞吐率和磁盘IO
高压缩比算法

我们一般认为最近的数据是最热的,我们希望最近的数据能够完全的被内存缓存,但是时序数据量比较大,因此我们需要采用高压缩比算法:平均每个时间点压缩到1.37字节。timestamp采用delta-delta压缩,value采用二进制xor压缩。
高压缩比使得最近一段时间(若干小时)的数据可以完全缓存在内存里,查询的时候避免了HBase的mget操作。解压缩速度很快,而且降精度可以在解压的过程中同时处理,减少内存的开销。
预降精度功能
我们做了预降精度,HiTSDB会在写入之前根据很多预测好的降精度级别将数据计算好,预降精度在逻辑上会有一些问题,包括以下几个方面:
• 数据老化 vs 预降精度
• 预降精度的级别和额外空间开销
• 预降精度和实时降精度结合
• 平均值带来的问题
• 精确计算 vs 概略计算,在预降精度数据上统计P99
• 时间窗口和数据修改