什么是Data Lake?
Data Lake是一个存储库,可以存储大量结构化,半结构化和非结构化数据。 它是以原生格式存储每种类型数据的地方,对帐户大小或文件没有固定限制。 它提供高数据量以提高分析性能和本机集成。
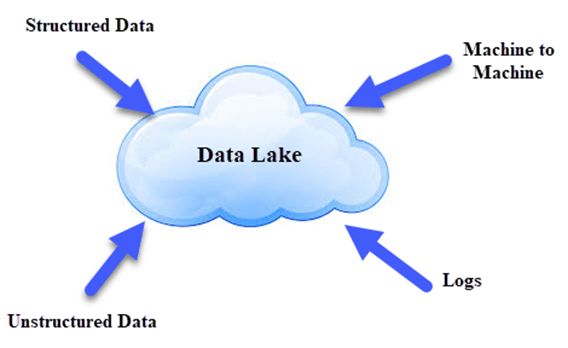
Data Lake就像一个大型容器,与真正的湖泊和河流非常相似。 就像在湖中你有多个支流进来一样,数据湖有结构化数据,非结构化数据,机器到机器,实时流动的日志。
Data Lake使数据民主化,是一种经济有效的方式来存储组织的所有数据以供以后处理。 研究分析师可以专注于在数据中找到意义模式而不是数据本身。
与数据存储在文件和文件夹中的分层数据仓库不同,Data湖具有扁平的架构。 Data Lake中的每个数据元素都被赋予唯一标识符,并标记有一组元数据信息。
为何选择Data Lake?
构建数据湖的主要目标是向数据科学家提供未经定义的数据视图。
使用Data Lake的原因是:
- 随着存储引擎的出现,像Hadoop存储不同的信息变得容易。 无需使用Data Lake将数据建模到企业范围的模式中。
- 随着数据量,数据质量和元数据的增加,分析质量也会提高。
- Data Lake提供业务敏捷性
- 机器学习和人工智能可用于进行有利可图的预测。
- 它为实施组织提供了竞争优势。
- 没有数据孤岛结构。 Data Lake提供360度的客户视图,使分析更加健壮。
数据湖架构
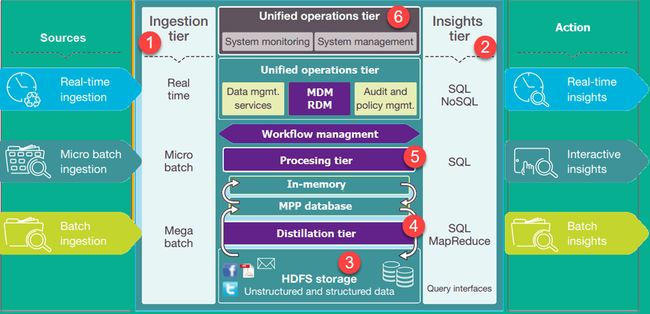
该图显示了Business Data Lake的体系结构。 较低级别表示大部分处于静止状态的数据,而较高级别表示实时交易数据。 此数据流经系统,没有延迟或延迟很小。 以下是Data Lake Architecture的重要层次:
- 1摄取层 :左侧的层描述了数据源。 数据可以批量或实时加载到数据湖中
- 2洞察层:右侧的层代表研究方面,使用系统的见解。 SQL,NoSQL查询甚至excel都可用于数据分析。
- 3HDFS是结构化和非结构化数据的经济高效的解决方案。 它是系统中静止的所有数据的着陆区。
- 4蒸馏层从存储轮胎中获取数据并将其转换为结构化数据以便于分析。
- 5处理层运行分析算法和用户查询,具有不同的实时,交互,批处理以生成结构化数据,以便于分析。
- 6统一操作层管理系统管理和监视。 它包括审计和熟练管理,数据管理,工作流程管理。
关键数据湖概念
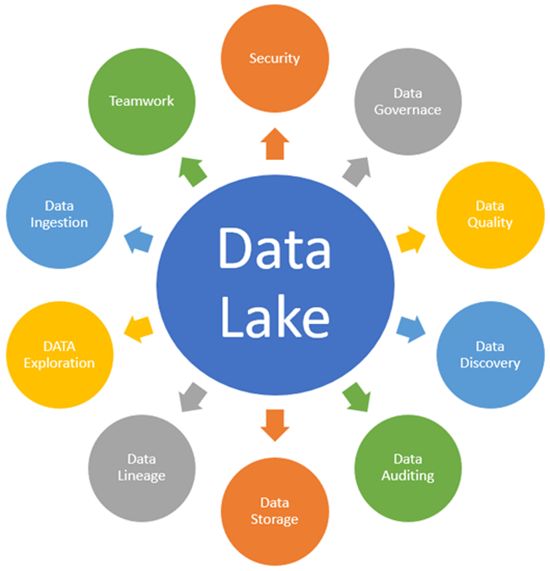
以下是Key Data Lake概念,人们需要了解这些概念才能完全理解Data Lake Architecture
- 数据摄取
数据提取允许连接器从不同的数据源获取数据并加载到Data湖中。
数据提取支持:所有类型的结构化,半结构化和非结构化数据。批量,实时,一次性负载等多次摄取;许多类型的数据源,如数据库,Web服务器,电子邮件,物联网和FTP。
- 数据存储
数据存储应该是可扩展的,提供经济高效的存储并允许快速访问数据探索。 它应该支持各种数据格式。
- 数据治理
数据治理是管理组织中使用的数据的可用性,可用性,安全性和完整性的过程。
- 安全
需要在Data Lake的每个层中实现安全性。 它始于存储,发掘和消耗。 基本需求是停止未授权用户的访问。 它应该支持不同的工具来访问数据,易于导航GUI和仪表板。
身份验证,会计,授权和数据保护是数据湖安全的一些重要特性。
- 数据质量:
数据质量是Data Lake架构的重要组成部分。 数据用于确定商业价值。 从劣质数据中提取洞察力将导致质量差的洞察力。
- 数据发现
数据发现是您开始准备数据或分析之前的另一个重要阶段。 在这个阶段,标记技术用于表达数据理解,通过组织和解释数据湖中摄取的数据。
- 数据审计
两个主要的数据审计任务是跟踪对关键数据集的更改:跟踪重要数据集元素的更改;捕获如何/何时/以及更改这些元素的人员。
数据审计有助于评估风险和合规性。
- 数据沿袭
该组件处理数据的来源。 它主要涉及随着时间推移它的推动者以及它发生了什么。 它简化了从始发地到目的地的数据分析过程中的错误更正。
- 数据探索
这是数据分析的开始阶段。 在开始数据探索之前,确定正确的数据集是至关重要的。
所有给定的组件需要协同工作,在Data Lake构建中发挥重要作用,轻松演化和探索环境。

- Data Lake的成熟阶段
数据湖成熟阶段的定义不同于教科书。 虽然症结仍然是一样的。 成熟后,阶段定义是从外行的角度出发的。
第1阶段:大规模处理和摄取数据
数据成熟度的第一阶段涉及提高转换和分析数据的能力。 在这里,企业所有者需要根据他们的技能组找到工具,以获取更多数据并构建分析应用程序。
第二阶段:建立分析肌肉
这是第二阶段,涉及提高转换和分析数据的能力。 在这个阶段,公司使用最适合他们技能的工具。 他们开始获取更多数据和构建应用程序。 在这里,企业数据仓库和数据湖的功能一起使用。
第3阶段:EDW和Data Lake齐声协作
这一步涉及将数据和分析交给尽可能多的人。 在此阶段,数据湖和企业数据仓库开始在联合中工作。 两者都在分析中发挥作用。
第四阶段:湖中的企业能力
在数据湖的成熟阶段,企业功能被添加到Data Lake中。 采用信息治理,信息生命周期管理功能和元数据管理。 但是,很少有组织可以达到这种成熟水平,但这种情况将在未来增加。
参考资料
- python测试开发项目实战-目录
- python工具书籍下载-持续更新
- python 3.7极速入门教程 - 目录
- 讨论qq群630011153 144081101
- 原文地址
- 本文涉及的python测试开发库 谢谢点赞!
- 本文相关海量书籍下载
- https://www.tutorialspoint.com/sqoop/sqoop_installation.htm
- https://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html
- https://www.softwaretestinghelp.com/top-4-etl-testing-tools/
Data Lake实施的最佳实践:
- 架构组件,它们的交互和已识别的产品应该支持本机数据类型
- Data Lake的设计应该由可用的而不是所需的驱动。 在查询之前,不会定义架构和数据要求
- 设计应遵循与服务API集成的一次性组件。
- 应独立管理数据发现,摄取,存储,管理,质量,转换和可视化。
- Data Lake架构应针对特定行业量身定制。 它应确保该域所需的功能是设计的固有部分
- 更快地加入新发现的数据源非常重要
- Data Lake帮助定制管理以提取最大价值
- Data Lake应该支持现有的企业数据管理技术和方法
建立数据湖的挑战:
- 在Data Lake中,数据量较高,因此该过程必须更依赖于程序化管理
- 处理稀疏,不完整,易变的数据很困难
- 更广泛的数据集和来源范围需要更大的数据治理和支持
数据湖和数据仓库之间的区别
| 参数 | 数据湖 | 数据仓库 |
|---|---|---|
| 数据 | 数据湖存储一切。 | 数据仓库仅关注业务流程。 |
| 处理 | 数据主要是未处理的 | 高度处理的数据。 |
| 数据类型 | 它可以是非结构化,半结构化和结构化的。 | 它主要以表格形式和结构。 |
| 任务 | 共享数据管理 | 针对数据检索进行了优化 |
| 敏捷 | 高度灵活,根据需要进行配置和重新配置。 | 与Data湖相比,它不那么灵活,并且具有固定的配置。 |
| 用户 | Data Lake主要由Data Scientist使用 | 商务人士广泛使用数据仓库 |
| 存储 | 数据湖设计用于低成本存储。 | 使用提供快速响应时间的昂贵存储 |
| 安全 | 提供较少的控制。 | 允许更好地控制数据。 |
| 更换EDW | 数据湖可以作为EDW的来源 | EDW的补充(不替代) |
| 架构 | 读取模式(没有预定义的模式) | 写入模式(预定义模式) |
| 数据处理 | 有助于快速摄取新数据。 | 引入新内容非常耗时。 |
| 数据粒度 | 数据细节或粒度较低。 | 摘要或汇总详细程度的数据。 |
| 工具 | 可以使用像Hadoop / Map Reduce这样的开源/工具 | 主要是商业工具。 |
使用Data Lake的好处和风险:
以下是使用Data Lake的一些主要好处:
- 充分利用产品离子化和高级分析
- 提供经济高效的可扩展性和灵活性
- 提供无限数据类型的价值
- 降低长期拥有成本
- 允许经济存储文件
- 快速适应变化
- 数据湖的主要优点是不同内容源的集中化
- 来自各个部门的用户可能分散在全球各地,可以灵活地访问数据
使用Data Lake的风险:
- 一段时间后,Data Lake可能会失去相关性和动力
- 设计Data Lake时涉及的风险较大
- 非结构化数据可能会导致无法使用的超级数据,无法使用的数据,不同的复杂工具,企业范围的协作,统一,一致和通用
- 它还增加了存储空间并计算成本
- 没有办法从其他使用过数据的人那里获得洞察力,因为之前的分析师没有考虑过调查结果
- 数据湖的最大风险是安全性和访问控制。 有时,数据可以放入湖中而不受任何疏忽,因为某些数据可能具有隐私和监管需求
小结:
- Data Lake是一个存储库,可以存储大量结构化,半结构化和非结构化数据。
- 构建数据湖的主要目标是向数据科学家提供未经定义的数据视图。
- 统一操作层,处理层,蒸馏层和HDFS是Data Lake Architecture的重要层
- 数据提取,数据存储,数据质量,数据审计,数据探索,数据发现是Data Lake Architecture的一些重要组成部分
- Data Lake的设计应该由可用的而不是所需的驱动。
- Data Lake降低了长期拥有成本并允许经济地存储文件
- 数据湖的最大风险是安全性和访问控制。 有时,数据可以放入湖中而不受任何疏忽,因为某些数据可能具有隐私和监管需求。