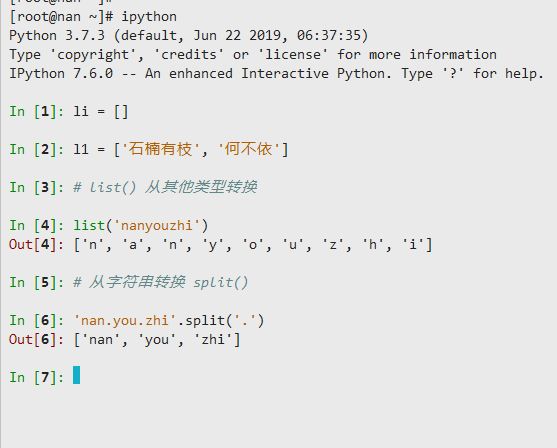
一、 什么是数据结构
在计算机科学中,数据结构(英语:data structure)是计算机中存储、组织数据的方式。
1. Python 中核心数据结构分类
- 序列类型: 字符串、列表、元组
- 泛映射类型: 字典
- 集合: set()
在 Python中列表、元组、字典、集合都称为容器。
2. 序列类型数据结构共有的特点:
偏移量(索引) ---0 --- 1------- 2 ----- 3 ------ 5 ------ 6 --- 7 ------ 8 - ( N-1)
-------------------------1 ---- 2------ 3 ----- 4 ------ 5 ------ 6 --- 7 ------ 8 -----9
-偏移量(索引)(-N)---(-8)--(-7)(-6)(-5)(-4)(-3)(-2)(-1)
二、列表
1. 列表的特性介绍
- 列表内的元素是可变的。
-> 列表的元素可以是 Python 的任何类型的数据和对象如:字符串、列表、元组、字典、集合、函数、类
- 列表中的具有相同值的元素允许出现多次
[1, 2, 1, 1, 1, 1, 3, 3, 2]
2. 创建列表
嵌套的列表
列表中可包含 python 中任何类型的元素(对象),当然也可以包括一个或多个列表
li = [['one', 'two', 'three'], [1, 2, 3]]
3.列表的基本操作
3.1 取值
没有嵌套的列表
li_f = [ 'insert', 'append','extend', 'remove', 'pop', 'sort', 'sorted']
li_f[0] # insert
li_f[2] #extend
嵌套的列表
l2 = [['one', 'two', 'three'], [1, 2, 3]]
l2[0][1] # two
3.2 切片
同字符串的切片一样,详情参考字符串教程中的切片
几点简单示例
li_f = [ 'insert', 'append','extend', 'remove', 'pop', 'sort', 'sorted']
# 获取全部元素
li_f[:]
# 反转
li_f[::-1]
3.3 必会方法
# 先定义一个列表
li = [5, 4, 3, 2, 1, 0]
len()
方法是一个内置函数,可以统计序列类型的数据结构的长度。
n = len(li)
print(n)
in
判断元素是否存在于列表中。
if 5 in li:
print('我思故我在')
append()
向列表的最后位置,添加一个元素,只接收一个参数。
li.append('a')
print(li)
insert()
向原列表的指定位置插入一个元素,接收两个参数,
第一个是索引号,第二个是要插入的元素。
li.insert(0, 'b')
print(li)
extend()
可以把一个序列类型中的每个元素追加到原列表中,接收的参数是一个序列类型的数据(字符串,列表)。
l2 = ['XN','nanyouzhi']
li.extend(l2)
print(li)
remove()
移除列表中某个指定的元素,没有返回值,并且假如有多个相同值的元素存在,每次只会移除排在最前面的那个元素
obj.remove('a') 。
pop()
从原列表中删除一个元素,并且把这个元素返回。
接收零个或一个参数,参数是偏移量,int 类型。
# 删除列表中的最后一个元素
li.pop()
# 删除列表中第二个索引号对应的元素,并且返回这个元素,用变量名`n` 接收。
n = li.pop(2)
''.join() 把列表中的元素拼接起来,返回的是字符串类型
l7 = ['a','b']
s = ''.join(l7)
print(s)
# 输出
'ab'
还可以以指定的字符进行拼接
l7 = ['a','b']
s = '-'.join(l7)
print(s)
# 输出
'a-b'
index 返回指定元素的索引号。
idx = li.index(4)
print(idx)
*count() 是列表的内置方法,可以统计出相同值的元素在列表中总共
出现都少次.
num = obj.count(4)
print(num)
sort()
是列表的内置方法,对列表中元素进行排序。
默认是升序, 这个改变列表自身。
还可以接收一个 reverse (反转) 参数, 其值可以是 True 和 False。
False 是升序,True 是降序。需要是同一种数据类型,比如都是字符串,或都是整型。
示例:
l5 = [2, 4, 23, 34, 100]
l5.sort(reverse=True)
print(l5)
# 输出:
[100, 34, 23, 4, 2]
sorted()
是 python 的内置函数,接受一个参数,参数可以是任意序列类型的数据,但是元素的类型必须相同.
比如是含有都是 str 的列表,或者是含有都是 int 的列表
它会返回一个新的类别,原列表不变。
li = [2,10,3,7]
l10 = sorted(li)
print(li)
print(l10)
4. 通过索引和切片修改列表
索引号
In [11]: int_number = [1,2,3,4,5]
In [12]: int_number[2]=20
In [13]: int_number
Out[13]: [1, 2, 20, 4, 5]
切片
li = [1, 2, 3, 4, 5]
li[1:3] = [0]
print(li)
5. 引用赋值
In [192]: a
Out[192]: ['6', '5', '3', '1', '1']
In [193]: b = a
In [194]: b
Out[194]: ['6', '5', '3', '1', '1']
In [195]: a[-2]=2
可以看到,这种用等号将一个列表赋值给多个变量时,使用其中任意一个变量对列表的操作,结果都会同步到其他变量的值。
在这种现象中,就像前面学到的变量的赋值,变量和列表本身之间的关系称作,变量对列表对象的引用,并没有创建一个新的列表。
解决方法
- 使用以下任意一种方法,都可以将原列表的值赋值给一个新的列表
- 列表的内置函数 obj.copy()
- 序列类型函数 list(obj)
- 列表切片
以上方法得到的列表可赋值给一个新的变量, 这变量各自有自己的列表对象,互相之间不会影响
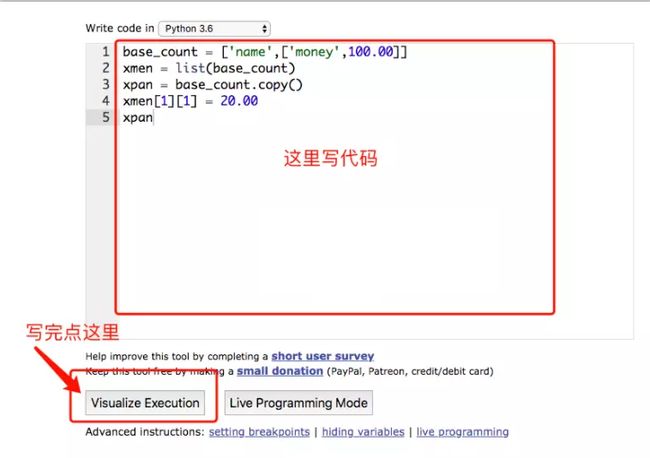
6. 深浅拷贝
In [110]: base_count = ['name',['money',100.00]]
In [111]: xmen = list(base_count)
In [112]: xpan = base_count.copy()
In [113]: xmen[1][1] = 20.00
In [114]: xpan
Out[114]: ['name', ['money', 20.0]]
解决办法
# 导入模块
import copy
base_count = ['name',['money',100.00]]
# 利用模块中的 copy 方法创建一个全新的对象
xmen_new = copy.deepcopy(base_count)
# 利用模块中的 copy 方法创建另一个全新的对象
xpan_new = copy.deepcopy(base_count)
# 改变其中一个对象中的值
xpan_new[1][1] = 50.00
# 分别打印两个对象
print(xmen_new)
print(xpan_new)
让代码有生命
三、元组
1 元组特性介绍
- 元组和列表一样,也是一种序列。
- 唯一的不同是,元组是相对不可变的。
2 高效创建元组
t1 = () # 创建 空 元素的元组
-
你以为这就完了?
单一元素元组怎么搞?
In [168]: v_tp = (3)
In [169]: only_tp = 3,
In [170]: type(v_tp)
Out[170]: int
In [171]: type(only_tp)
Out[171]: tuple
创建非空元素的元组是用
逗号,而不是用小括号
tuple()
可以对其他序列类型的数据转换为元组。
In [173]: s1 = 'car'
In [174]: li = [1,2,3]
In [175]: tuple(s1)
Out[175]: ('c', 'a', 'r')
In [176]: tuple(li)
Out[176]: (1, 2, 3)
In [177]: dl = [1,2,3,['a','b']]
In [178]: tuple(dl)
Out[178]: (1, 2, 3, ['a', 'b'])
In [33]: t1 = (1, 2, 3, ['a', 'b'])
In [34]: t1[3][0]=0
In [35]: t1
Out[35]: (1, 2, 3, [0, 'b'])
3 使用元组的理由
- 占用内存空间小
- 元组内的值不会被意外的修改
- 可作为字典的键
- 函数的参数是以元组形式传递的
- 命名元组有时候可以代替类的对象(面向对象的时候讲)