引言:java中的所有的集合是我们开发中常常会使用到的工具,也是面试中常常出现的考点,这篇文章主要针对List接口下的集合以及Set接口下的集合实现原理进行一个详细的剖析

image.png
一、List接口下的集合
1、ArrayList
1.1、特性
- a:ArrayList熟称动态数组;是一个不允许被序列化的对象数组
private transient Object[] elementData
- b:存储数据时是按照你插入的顺序进行存储的;用于存储一系列的对象引用(references)
- c:由于实现了List接口,底层是通过数组实现的;
- d:实现了RandomAccess接口支持随机访问访问该集合中的元素;
但是向集合中插入元素和删除集合中的元素耗时比较长,因为需要按照顺查找到目标元素进行相关操作; - e:初始容量:10
private static final int DEFAULT_CAPACITY = 10;
- f:关于扩容:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//关键看这一步;通过位运算将其容量扩大了二倍;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
- g:非线程安全的类型,可以通过Collections.synchronizedList(list)方法将ArrayList变成一个线程安全的集合
1.2、实现原理
ArrayList的底层是通过数组实现的,因此具有查找速度快,但是删除和插入速度慢的特性;重点添加元素的方法
public boolean add(E e) {
//确保数组空间是否充足
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//数组容量不足则进行扩容操作
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 新增容量大小为原始用量大小的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
2:LinkedList
2.1、特性
- a:基于链表实现,不支持随机访问,随机查询某个元素不如ArrayList;但是向集合中插入和删除元素缺比ArrayList性能好;不需要移动元素;
- b:存储数据是通过静态内部类Node双向链表实现;
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
- c:链表不存在容量问题
2.2、实现原理
LinkedList底层通过链表实现,作为引导我们也只看LinkedList的添加和删除的代码实现
- 添加实现
public boolean add(E e) {
// 向链表的尾部添加一个元素
linkLast(e);
return true;
}
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
//记录链表的大小
size++;
// 修改次数
modCount++;
}
添加元素到指定位置
public void add(int index, E element) {
// 检查index是否超过数组的长度
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
/**
* Returns the (non-null) Node at the specified element index.
*/
Node node(int index) {
// assert isElementIndex(index);
// 如果index大于链表长度的一半则从链表后面向前查找,否则从链表头部向后查找
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/**
* Inserts element e before non-null Node succ.
在制定节俭的前面插入一个节点
*/
void linkBefore(E e, Node succ) {
// assert succ != null;
final Node pred = succ.prev;
final Node newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
- 删除
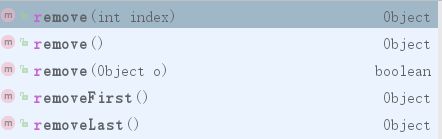 QQ截图20190119130836.png
QQ截图20190119130836.png
共有如上5个方法,我们依次来看
remove(int index)
public E remove(int index) {
// 检查是否越界
checkElementIndex(index);
return unlink(node(index));
}
/**
* Unlinks non-null node x.
*/
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
remove()
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node f) {
// assert f == first && f != null;
final E element = f.item;
final Node next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
remove(Object o)
// 遍历找到对应的节点再调用unlink(Node node)
public boolean remove(Object o) {
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
removeLast()
public E removeLast() {
final Node l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node l) {
// assert l == last && l != null;
final E element = l.item;
final Node prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
二、Set接口下的集合
1、hashSet
1.1、特性
- a、没有重复的元素
- b、底层通过HashMap实现
- c、非线程安全的
public HashSet() {
map = new HashMap<>();
}
1.2、实现原理
hashSet底层是通过hashmap实现,其中map的key我们向hashSet里面添加的元素,value是一个名为PRESENT的Object对象
private static final Object PRESENT = new Object();
还是一样,我们来看看hashset的添加元素和删除元素的方法
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// HashMap类里面的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// hashmap的putval()方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
remove(Object o)删除元素的方法
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
// hashmap的remove方法
public V remove(Object key) {
Node e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
// 先定位到对应的链表中对应的节点,再看节点的key是否是我们要找的key,否则则判断节点是否是红黑树,否则为链表
final Node removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node[] tab; Node p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
2、TreeSet
2.1、特性
- A:底层通过TreeMap实现
public TreeSet() {
this(new TreeMap());
}
- B:不存在重复的元素
- C:能够保证元素的有序性
2.2、实现原理
底层通过TreeMap实现,和HashSet十分相似, 所有的API底层都是调用TreeMap的API,具体参见