来源:https://www.unb.ca/cic/datasets/ids-2018.html
https://github.com/ISCX/CICFlowMeter
注:通信安全机构(CSE)与加拿大网络安全研究所(CIC)合作项目
异常检测因其具有检测新攻击的潜力,一直是许多研究者关注的焦点。然而,由于这些系统在部署之前需要进行大量的测试、评估和调优,因此它在实际应用程序中的应用受到了系统复杂性的限制。将这些系统置于真实标记的网络跟踪之上,并使用一组全面而广泛的入侵和异常行为,是测试和评估的最理想方法。
这本身就是一个巨大的挑战,因为数据集的可用性是极其罕见的,因为一方面,许多这样的数据集是内部的,由于隐私问题而不能共享,另一方面,其他数据集是高度匿名的,不能反映当前的趋势,或者缺乏某些统计特征,所以还没有一个完美的数据集。因此,研究人员必须求助于通常不是最优的数据集。随着网络行为和模式的变化和入侵的发展,从静态和一次性的数据集转向更动态的生成数据集变得非常必要,这些数据集不仅反映了当时的流量组合和入侵,而且是可修改的、可扩展的和可重现的。
为了克服这些缺点,设计了一种系统的方法来生成数据集来分析、测试和评估入侵检测系统,重点是基于网络的异常检测器。本项目的主要目标是开发一种系统的方法,在创建包含网络上所见事件和行为的抽象表示的用户概要的基础上,生成用于入侵检测的多样化和全面的基准数据集。这些概要文件将组合在一起,生成一组不同的数据集,每个数据集都具有一组独特的特性,这些特性涵盖了评估域的一部分。
最后的数据集包括七种不同的攻击场景:暴力攻击、心脏出血、僵尸网络、DoS、DDoS、Web攻击和网络内部的渗透。攻击基础设施包括50台机器,受害者组织有5个部门,包括420台机器和30台服务器。数据集包括每个机器的捕获网络流量和系统日志,以及使用CICFlowMeter-V3从捕获的流量中提取的80个特征。
1. 介绍
在CSE-CIC-IDS2018 dataset中,我们使用profile的概念以系统的方式生成数据集,其中将包含应用程序、协议或较低层网络实体的入侵详细描述和抽象分布模型。代理或人工操作员可以使用这些概要文件生成网络上的事件。由于生成概要文件的抽象性质,我们可以将它们应用于具有不同拓扑结构的各种网络协议。概要文件可以一起用于为特定需求生成数据集。我们将建立两类不同的个人资料:
(1)B-profiles:使用各种机器学习和统计分析技术(如K-Means、Random Forest、SVM和J48)封装用户的实体行为。封装的特性包括协议的包大小、每个流的包数、有效负载中的某些模式、有效负载的大小和协议的请求时间分布。在我们的测试环境中,将模拟以下协议:HTTPS、HTTP、SMTP、POP3、IMAP、SSH和FTP。根据我们最初的观察,大部分流量是HTTP和HTTPS。
(2)M-Profiles:试图描述攻击场景以一种明确的方式。在最简单的情况下,人类可以解释这些概要文件,然后执行它们。理想情况下,将使用自治代理和编译器来解释和执行这些场景。对于攻击,我们考虑了六种不同的场景(表1):

(3)网络内部泄漏:
在此场景中,我们通过电子邮件向受害者发送恶意文件,并利用应用程序漏洞。成功利用后,在受害者的计算机上执行一个后门,然后我们使用他的计算机扫描内部网络,寻找其他易受攻击的盒子,如果可能的话利用它们。
(4)HTTP拒绝服务:
HTTP拒绝服务:在这个场景中,我们使用Slowloris和LOIC作为主要工具,它们已经被证明可以使用一台攻击机器完全访问Web服务器。Slowloris从建立到远程服务器的完整TCP连接开始。该工具通过定期向服务器发送有效的、不完整的HTTP请求来保持连接打开,以防止套接字关闭。由于任何Web服务器提供连接的能力都是有限的,所以使用完所有套接字并不能建立其他连接只是时间问题。此外,HOIC是另一个著名的应用程序,它可以对网站发起DoS攻击。
(5)web应用程序攻击的集合:
web应用程序攻击集合:在这个场景中,我们使用了Damn Vulnerable web App (DVWA)作为我们的受害者web应用程序,该应用程序的开发目的是帮助安全专业人员测试他们的技能。在第一步中,我们通过web应用程序漏洞扫描器扫描网站,然后对易受攻击的网站进行不同类型的web攻击,包括SQL注入、命令注入和无限制的文件上传。
(6)蛮力攻击:
蛮力攻击:蛮力攻击对网络非常常见,因为它们倾向于使用弱用户名和密码组合来入侵帐户。最后一个场景的设计目标是通过对主服务器运行字典暴力攻击来获取SSH和MySQL帐户。
(7)最后更新攻击:
最后更新攻击:有一些基于一些著名的漏洞攻击,可以进行在特定的时间(这些非凡的弱点有时影响数以百万计的服务器或受害者,通常需要几个月补丁所有脆弱的世界各地的计算机),其中最著名的是近年来Heartbleed。
重要的是要注意,概要文件需要一个基础设施才能有效地使用。我们的测试平台将由一些相互连接的Windows和基于Linux的工作站组成。对于Windows机器,我们将使用不同的服务包(因为每个包都有一组不同的已知漏洞),对于Linux机器,我们将使用Metasploit-able distribution,它是为被新的渗透测试人员攻击而开发的。
2. 基础设施和实现
2.1 B-Profile
为了产生良性的背景流量,B-Profile被设计用来提取一组人类用户的抽象行为。它试图用机器学习和统计分析技术来封装用户生成的网络事件。封装的特性包括协议的包大小分布、每个流的包数、有效负载中的某些模式、有效负载大小和协议的请求时间分布。一旦从用户派生出b - profile,代理(ic - benigngenerator)或人工操作员就可以使用它们在网络上生成真实的良性事件。组织和研究人员可以使用这种方法轻松地生成真实的数据集;因此,不需要匿名数据集。
2.2 M-Profile
我们实现了七个攻击场景。对于每种攻击,我们都基于实现的网络拓扑定义一个场景,并在目标网络之外的一台或多台机器上执行攻击。图1显示了实现的网络,这是AWS计算平台上常见的LAN网络拓扑。为了拥有与真实网络相似的多种机器,我们安装了5个子网络,分别是研发部(Dep1)、管理部(Dep2)、技术部(Dep3)、秘书和运营部(Dep4)、IT部(Dep5)和服务器室。除了IT部门,我们为所有部门安装了不同的MS Windows OSs (Windows 8.1和Windows 10), IT部门的所有计算机都是Ubuntu。对于服务器室,我们实现了不同的MS Windows服务器,如2012年和2016年。本节的其余部分将介绍七种攻击场景和工具。
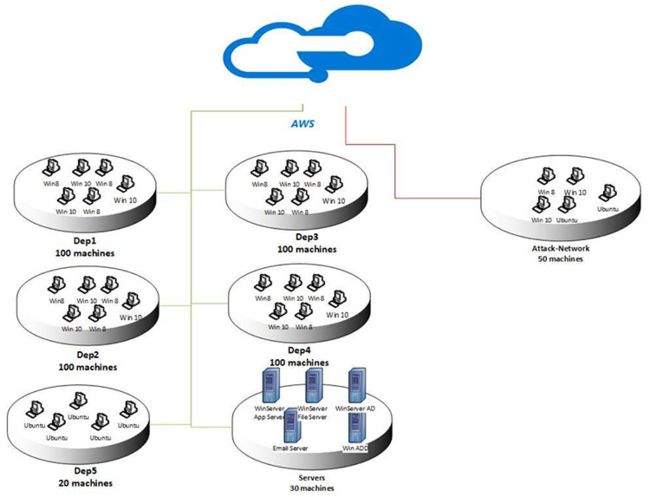
2.2.1 蛮力攻击
有很多工具可以进行强力攻击和密码破解,比如Hydra、Medusa、Ncrack、Metasploit模块和Nmap NSE脚本。此外,还有一些用于密码散列破解的工具,如hashcat和hashpump。但是,最全面的多线程工具之一是Patator,它是用Python编写的,似乎比其他工具更可靠、更灵活。它还可以将每个响应保存在一个单独的日志文件中,供以后查看。在这个数据集中,我们使用两个模块,攻击者是Kali Linux机器上的FTP和SSH,受害者是Ubuntu 14.0系统。对于密码列表,我们使用一个包含9000万个单词的大字典。
2.2.2 Heartbleed攻击
利用心脏出血最著名的工具之一是心脏水蛭。它可以扫描易受漏洞攻击的系统,然后可以用来利用它们并过滤数据。一些重要的特点:
(1)关于目标是否脆弱的结论性/非结论性判断
(2)批量/快速下载heartbleed数据到一个大文件中,使用多个线程进行离线处理
(3)自动检索私钥,不需要其他步骤
(4)一些有限的IDS规避
(5)STARTTLS支持
(6)IPv6支持
(7)Tor / Socks5n代理支持
(8)广泛连接诊断信息
(9)为了利用这个漏洞,我们编译了OpenSSL version 1.0.1f,这是一个脆弱的版本。然后使用Heartleech检索服务器的内存。
2.2.3僵尸网络
在这个数据集中,我们使用Zeus,它是一个特洛伊木马恶意软件包,运行在Microsoft Windows的不同版本上。虽然它可以用来执行许多恶意和犯罪的任务,但它经常被用来通过人在浏览器中的击键记录和表单抓取来窃取银行信息。它也被用来安装密码柜勒索软件。Zeus主要通过下载和网络钓鱼的方式传播。此外,作为补充,我们使用战神僵尸网络,这是一个开源僵尸网络,具有以下功能:
(1)远程用于cmd . exe壳
(2)持久性
(3)文件上传/下载
(4)截图
(5)关键日志
在这个场景中,我们用两个不同的僵尸网络(Zeus和Ares)感染机器,并且每隔400秒我们就向僵尸请求屏幕截图。
2.2.4拒绝服务
Slowloris是Robert Hansen发明的一种拒绝服务攻击工具,它允许一台机器以最小的带宽和对不相关的服务和端口的副作用来关闭另一台机器的web服务器。在这个场景中,我们使用一个基于Slowloris perl的工具来关闭web服务器。
2.2.5分布式拒绝服务
High Orbit Ion Cannon,通常缩写为HOIC,是一个开源的网络压力测试和拒绝服务攻击应用程序,使用BASIC编写,可以同时攻击多达256个url。它被设计用来取代普拉托克斯技术公司开发的低轨道离子炮。在这种情况下,我们使用免费的HOIC工具,使用4台不同的计算机进行DDoS攻击。
2.2.6网络攻击
在这项工作中,我们使用该死的脆弱的网络应用程序(DVWA)进行我们的攻击。DVWA是一个脆弱的PHP/MySQL web应用程序。它的主要目标是帮助安全专业人员在法律环境中测试他们的技能和工具,帮助web开发人员更好地理解保护web应用程序的过程,并帮助教师/学生在教室环境中教授/学习web应用程序安全性。为了自动化XSS和蛮力部分中的攻击,我们开发了一个带有Selenium框架的自动化代码。
2.2.7网络内部渗透
在这个场景中,应该利用一个脆弱的应用程序(如adobeacrobatreader9)。首先,受害者通过电子邮件收到恶意文件。然后,在成功利用Metasploit框架后,将在受害者的计算机上执行一个后门。现在我们可以使用Nmap对受害者的网络进行不同的攻击,包括IP扫描、全端口扫描和服务枚举。
3.捕获数据和最终数据集
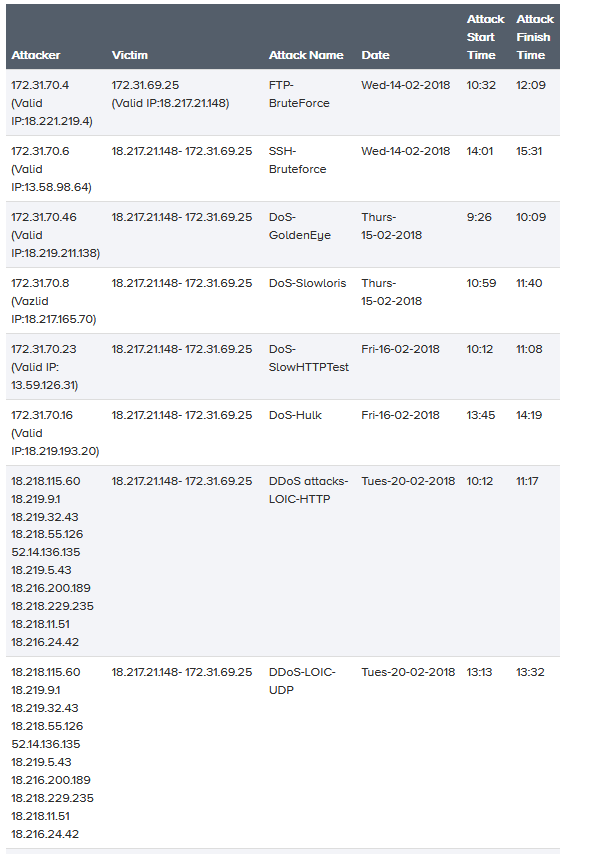
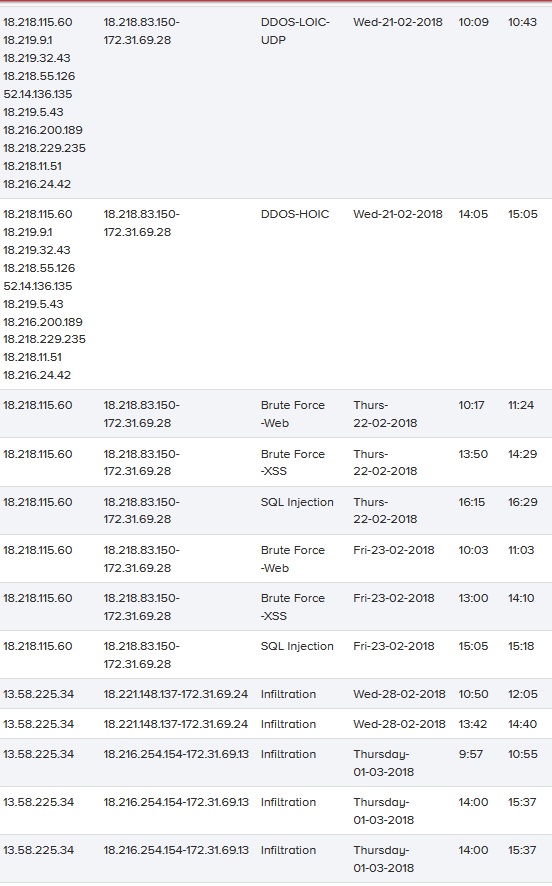
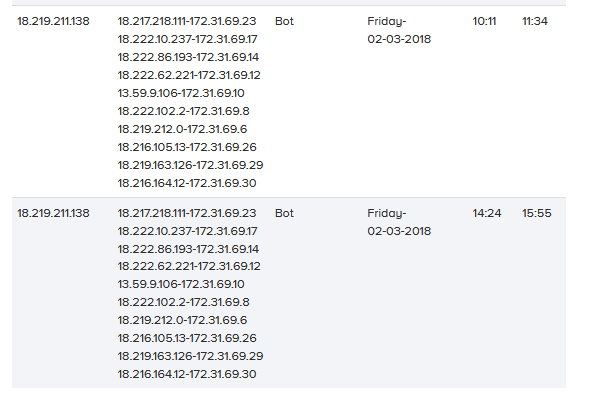
基于上一节中选择的所有攻击和定义的场景,我们实现了基础设施并执行了攻击场景。表2显示了攻击列表、相关攻击者和受害者IP、攻击日期、开始和结束时间。
表2:每日攻击列表、机器ip、攻击开始和结束时间(s)
3.特征提取
CICFlowMeter是一个用Java编写的网络流量生成器,在选择要计算的特性、添加新特性以及更好地控制流超时时间方面提供了更大的灵活性。它产生双向流(Biflow),其中第一个数据包确定正向(源到目的地)和反向(目的地到源)的方向,因此在正向和反向分别计算了持续时间、数据包数量、字节数、数据包长度等83个统计特征。
应用程序的输出是CSV文件格式,为每个流标记了6列,分别是FlowID、SourceIP、DestinationIP、SourcePort、DestinationPort和具有80多个网络流量特性的协议。通常TCP流在连接断开时终止(通过FIN包),UDP流通过流超时终止。流超时值可以由单独的方案任意分配,例如TCP和UDP都是600秒。CICFlowMeter-V3可以提取80多个特征,如下表所示:
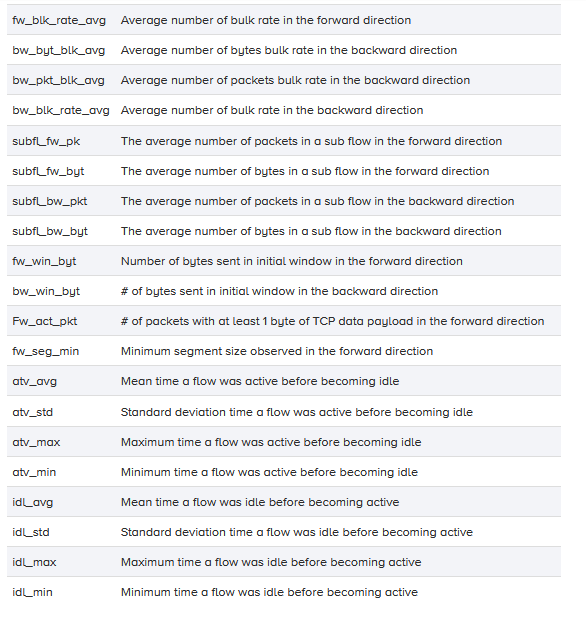
表3:CICFlowMeter-V3提取的流量特征列表


(1)fl_dur
流持续时间
(2)tot_fw_pk(流出方向?)
在正向上包的数量
(3)tot_bw_pk
在反向上包的数量
(4)tot_l_fw_pkt
正向数据包的总大小
(5)fw_pkt_l_max
包在正向上的最大大小
(6)fw_pkt_l_min
包在正向上的最小大小
(7)fw_pkt_l_avg
数据包在正向的平均大小
(8)fw_pkt_l_std
数据包正向标准偏差大小
(9)Bw_pkt_l_max
包在反向上的最大大小
(10)Bw_pkt_l_min
包在反向上的最小大小
(11)Bw_pkt_l_avg
数据包在反向的平均大小
(12)Bw_pkt_l_std
数据包反向标准偏差大小
(13)fl_byt_s
流字节率,即每秒传输的数据包字节数
(14)fl_pkt_s
流包率,即每秒传输的数据包数
(15)fl_iat_avg
两个流之间的平均时间
(16)fl_iat_std
两个流之间标准差
(17)fl_iat_max
两个流之间的最大时间
(18)fl_iat_min
两个流之间的最小时间
(19)fw_iat_tot
在正向发送的两个包之间的总时间
(20)fw_iat_avg
在正向发送的两个包之间的平均时间
(21)fw_iat_std
在正向发送的两个数据包之间的标准偏差时间
(22)fw_iat_max
在正向发送的两个包之间的最大时间
(23)fw_iat_min
在正向发送的两个包之间的最小时间
(24)bw_iat_tot
反向发送的两个包之间的总时间
(25)bw_iat_avg
反向发送的两个数据包之间的平均时间
(26)bw_iat_std
反向发送的两个数据包之间的标准偏差时间
(27)bw_iat_max
反向发送的两个包之间的最大时间
(28)bw_iat_min
反向发送的两个包之间的最小时间
(29)fw_psh_flag
在正向传输的数据包中设置PSH标志的次数(UDP为0)
(30)bw_psh_flag
在反向传输的数据包中设置PSH标志的次数(UDP为0)
(31)fw_urg_flag
在正向传输的数据包中设置URG标志的次数(UDP为0)
(32)bw_urg_flag
反方向数据包中设置URG标志的次数(UDP为0)
(33)fw_hdr_len
用于前向方向上的包头的总字节数
(34)bw_hdr_len
用于后向方向上的包头的总字节数
(35)fw_pkt_s
每秒前向包的数量
(36)bw_pkt_s
每秒后向包的数量
(37)pkt_len_min
流的最小长度
(38)pkt_len_max
流的最大长度
(39)pkt_len_avg
流的平均长度
(40)pkt_len_std
流长度的方差
(41)pkt_len_va
最小包到达间隔时间
(42)fin_cnt
带有FIN的包数量
(43)syn_cnt
带有SYN的包数量
(44)rst_cnt
带有RST的包数量
(45)pst_cnt
带有PUSH的包数量
(46)ack_cnt
带有 ACK的包数量
(47)urg_cnt
带有URG的包数量
(48)cwe_cnt
带有CWE的包数量
(49)ECE
带有ECE的包数量
(50)down_up_ratio
下载和上传的比例
(51)pkt_size_avg
数据包的平均大小
(52)fw_seg_avg
观察到的前向方向上数据包的平均大小
(53)bw_seg_avg
观察到的后向方向上数据包的平均大小
(54)fw_byt_blk_avg
在正向上的平均字节数块速率
(55)fw_pkt_blk_avg
在正向方向上数据包的平均数量
(56)fw_blk_rate_avg
在正向方向上平均bulk速率
(57)bw_byt_blk_avg
在反向上的平均字节数块速率
(58)bw_pkt_blk_avg
在反向方向上数据包的平均数量
(59)bw_blk_rate_avg
在反向方向上平均bulk速率
(60)subfl_fw_pk
在正向子流中包的平均数量
(61)subfl_fw_byt
子流在正向中的平均字节数
(62)subfl_bw_pkt
反向子流中数据包的平均数量
(63)subfl_bw_byt
子流在反向中的平均字节数
(64)fw_win_byt
在正向的初始窗口中发送的字节数
(65)bw_win_byt
在反向的初始窗口中发送的字节数
(66)Fw_act_pkt
在正向方向上具有至少1字节TCP数据有效负载的包
(67)fw_seg_min
在正方向观察到的最小segment尺寸
(68)atv_avg
流在空闲之前处于活动状态的平均时间
(69)atv_std
流在空闲之前处于活动状态的标准偏差时间
(70)atv_max
流在空闲之前处于活动状态的最大时间
(71)atv_min
流空闲前激活的最小时间
(72)idl_avg
流在激活之前空闲的平均时间
(73)idl_std
流量在激活前处于空闲状态的标准偏差时间
(74)idl_max
流在激活之前空闲的最大时间
(75)idl_min
流在激活之前空闲的最小时间