前言
互联网发展至今,搜索引擎仍然是获取信息最重要的途径之一,而搜索结果的排序是搜索引擎的核心技术之一,常见的排序算法有 PageRank、向量空间模型( 如:TF-IDF)、概率模型(如:BM25)、机器学习排序等,今天准备通过实例介绍一下人工神经网络在搜索结果排序中的应用。
人工神经网络
人工神经网络是一种模仿生物神经网络(动物的中枢神经系統,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。深入的概念以及定义读者可以自行谷歌,在本文中用到的神经网络成为多层感知器网络,它由多层的神经元组成,每一层的神经元输入是上一层的输出,本层的输出是下一层的输入,依次相连,理论上可以有 N 层,通常采用三层网络,即:输入层、隐藏层、输出层。在搜索排序中,输入层为查询的词,输出层为结果文档,如图:
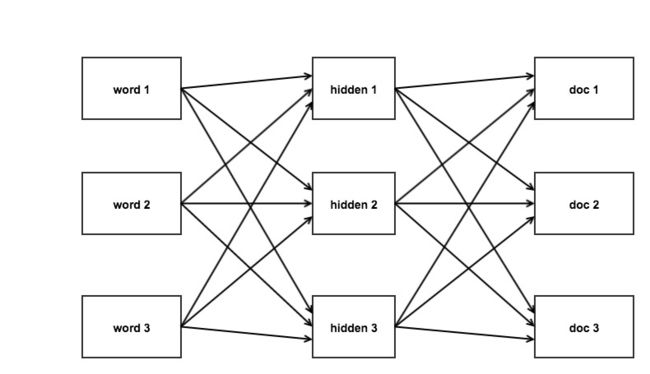
如图 1-1 所示,输入层传入查询词,经过隐藏层转化后输出,上图中每个线条有不同的强度,因此输出层的每个文档也有不同的强度,即相关度。如图:
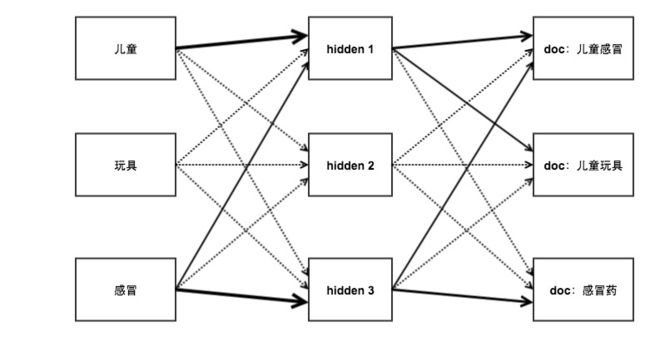
图 1-2 是一个训练后的神经网络的实例,每个输入节点到隐藏节点、隐藏节点到输出节点之间都有一个不同强弱的权重,对于任意的输入,根据自身的权重游走到隐藏层,隐藏层累加所有的输入后经过特定函数转化,游走到输出层,输出层累加所有的输入即为结果。
训练神经网络的核心工作就是创建一个隐藏层,并训练出输入节点到隐藏节点、隐藏节点到输出节点之间的权重关系。有了该网络后,对于任意的输入,模型都能给出一个合理的预测结果。
数据准备
数据结构
为了训练神经网络,我们需要以下几方面的数据
- 用于训练的数据,包含查询词—查询结果—期望值,如:
//格式:查询词,查询结果,结果期望
儿童 感冒,[doc:儿童感冒,doc:玩具,doc:感冒药],[1.0,0.0,1.0]
玩具,[doc:儿童感冒,doc:玩具,doc:感冒药],[0.0,1.0,0.0]
......
一般会把数据映射成 id,假设映射关系如下:
查询词 id 映射:
1 <-> 儿童
2 <-> 感冒
3 <-> 玩具
查询结果 id 映射:
1 <-> doc:儿童感冒
2 <-> doc:玩具
3 <-> doc:感冒药
则训练数据最终为:
//格式:查询词,查询结果,结果期望
1 2,[1,2,3],[1.0,0.0,1.0]
2,[1,2,3],[0.0,1.0,0.0]
......
- 隐藏层节点,用 mysql 存储,表结构为:
create table `ann`.`hidden_node` (
`id` int(11) NOT NULL auto_increment primary key,
`node_name` varchar(255) NOT NULL
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 输入节点与隐藏节点的关系表,用 mysql 存储,表结构为:
create table `ann`.`word2hidden` (
`fromid` int(11) NOT NULL, //输入节点 id,这里为词 id
`toid` int(11) NOT NULL, //目标节点 id,这里为隐藏节点的 id
`strength` double NOT NULL //信号强度
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 隐藏节点与输出节点的关系表,用 mysql 存储,表结构为:
create table `ann`.`hidden2doc` (
`fromid` int(11) NOT NULL, //输入节点 id,这里为隐藏节点的 id
`toid` int(11) NOT NULL, //目标节点 id,这里为结果文档 id
`strength` double NOT NULL
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
数据操作 API
建立好数据结构之后。还需要写对数据操作的 API,主要是两个操作:
- 获取两个节点间的信号强度,称为 getStrength 方法,主要负责从数据库中查询出信号强度,如果这两个节点还未建立任何的关系,则赋予一个默认值,如果是第 0 层(layer=0,即输入节点与隐藏节点之间的联系),则赋默认值 -0.2;如果是第 1 层(layer=0,即隐藏节点与输出节点之间的联系)则赋默认值 0.0,java 实现代码如下:
private double getStrength(int fromid, int toid, int layer) throws SQLException {
String table = layer == 0 ? "word2hidden" : "hidden2doc";
double default_strength = layer == 0 ? -0.2 : 0.0;
String sql = "select strength from " + table + " where fromid=? and toid=?";
PreparedStatement pstat = conn.prepareStatement(sql);
pstat.setInt(1, fromid);
pstat.setInt(2, toid);
ResultSet rs = pstat.executeQuery();
if (rs.next()) {
return rs.getDouble(1);
} else {
return default_strength;
}
}
- 设置两个节点间的信号强度,称为 setStrength 方法,java 实现代码如下:
private void setStrength(int fromid, int toid, int layer, double strength) throws SQLException {
String table = layer == 0 ? "word2hidden" : "hidden2doc";
String sql = "select strength from " + table +
" where fromid=" + fromid +
" and toid=" + toid;
ResultSet rs = conn.createStatement().executeQuery(sql);
if (rs.next()) {
conn.createStatement().execute("update " + table +
" set strength=" + strength +
" where fromid=" + fromid +
" and toid=" + toid);
} else {
conn.createStatement().execute("insert into " + table +
" (fromid, toid, strength)" +
" values(" + fromid + "," + toid + "," + strength + ")");
}
}
模型训练
隐藏层建立
一般情况下,在构建神经网络时,我们会预先建立好所有的节点。不过在本例中,我们只在需要的时候建立新的隐藏节点,更为简单高效。
每当我们传入以前从未见过的查询时,我们就建立一个隐藏节点,随后,给每个查询中从词与该隐藏节点之间、隐藏节点与输出节点之间赋予默认值。
我们用一个名为 generateHiddenNode 的方法来实现此功能,java 代码如下:
private void generateHiddenNode(List queryWordIds,
List docIds) throws SQLException {
if (queryWordIds.size() > 3) { //暂不支持过长的查询词组
return;
}
//判断该查询是否已经存在隐藏节点
String key = queryWordIds.stream()
.map(id -> String.valueOf(id))
.sorted()
.collect(Collectors.joining("_"));
ResultSet rs = conn.createStatement()
.executeQuery("select id from hidden_node where node_name='" + key + "'");
if (!rs.next()) {
//新建隐藏节点
PreparedStatement ps = conn.prepareStatement("insert into hidden_node values (NULL,?)",
Statement.RETURN_GENERATED_KEYS);
ps.setString(1, key);
ps.executeUpdate();
rs = ps.getGeneratedKeys();
rs.next();
int id = rs.getInt(1);
for (int queryWordId : queryWordIds) {
//查询词组与该隐藏节点的默认权重为 1.0 / 词个数
setStrength(queryWordId, id, 0, 1.0 / queryWordIds.size());
}
for (int docId : docIds) {
//隐藏节点与查询结果的默认权重为 0.1
setStrength(id, docId, 1, 0.1);
}
}
}
前馈法预测结果
建立隐藏层后,其实我们已经拥有了一个最基本的神经网络(虽然此时所有值都是默认赋值的,不「智能」,这个问题后面会解决),因此,对于任意给定的查询词与查询结果,我们能为每个结果给出一个预测结果,步骤如下:
- 获取与本次查询相关的所有隐藏节点,这是一项性能优化措施,因为在本例中,只有跟查询词或者查询结果相关的隐藏节点才会对最终的预测结果又影响,因此我们只需要找出相关的因此节点进行后续的计算皆可以了,具体实现为 getAllRelatedHiddens 方法:
private List getAllRelatedHiddens(List queryWordIds,
List docIds) throws SQLException {
Set hidden_ids = new HashSet<>();
//与输入节点相关的隐藏节点
String queryWordIds_str = queryWordIds.stream()
.map(id -> String.valueOf(id))
.collect(Collectors.joining(","));
ResultSet rs = conn.createStatement()
.executeQuery("select toid from word2hidden where fromid in (" + queryWordIds_str + ")");
while (rs.next()) {
hidden_ids.add(rs.getInt(1));
}
//与输出节点相关的隐藏节点
String resultIds_str = docIds.stream()
.map(id -> String.valueOf(id))
.collect(Collectors.joining(","));
rs = conn.createStatement()
.executeQuery("select toid from hidden2doc where fromid in (" + resultIds_str + ")");
while (rs.next()) {
hidden_ids.add(rs.getInt(1));
}
return new ArrayList<>(hidden_ids);
}
- 构建本次查询的神经网络的权重矩阵
现在我们已经有了输入节点(查询词组)、相关的隐藏节点、输出节点(查询结果)、输入节点与隐藏节点的信号强度,隐藏节点与输出节点的信号强度,我们可以以此构建两个权重矩阵,分别为:
- 输入权重矩阵:记录第 i 个查询词与第 j 个隐藏节点之间的信号强度
- 输出权重矩阵:记录第 j 个隐藏节点与第 k 个查询结果之间的信号强度
代码实现如下:
private List queryWordIds;//查询词组
private List hidden_ids;//相关隐藏节点
private List docIds;//查询结果
private double[][] input_weight;//输入层的权重矩阵
private double[][] output_weight;//输出层的权重矩阵
private double[] word_val;//每个词的输出信号
private double[] hidden_val;//每个隐藏层的输出信号
private double[] doc_val;//每个输出文档的输出信号
private void setupNetWork(List queryWordIds, List docIds) throws SQLException {
//初始化参数,供后续使用
this.queryWordIds = queryWordIds;
this.docIds = docIds;
hidden_ids = getAllRelatedHiddens(queryWordIds, docIds);
word_val = new double[queryWordIds.size()];
hidden_val = new double[hidden_ids.size()];
doc_val = new double[docIds.size()];
//构造 word -> hidden 权重矩阵
input_weight = new double[queryWordIds.size()][hidden_ids.size()];
for (int i = 0; i < queryWordIds.size(); i++) {
for(int j=0;j docid 权重矩阵
output_weight = new double[hidden_ids.size()][docIds.size()];
for(int j=0;j - 构造前馈算法
有了权重矩阵后,我们就可以一层一层地依次往下计算,直到得到最终结果。在这里为: - 查询单词依据输入权重矩阵,向隐藏节点输出信号,隐藏节点汇总所有输入信号强度,并通过S 型函数反馈输入,输出反馈后自身节点的信号
- 依据输出权重矩阵,隐藏节点向输出层输出信号,输出节点汇总所有输入信号强度,并通过S 型函数反馈输入,形成结果预测
整个前馈算法进行结果预测的过程如图:

其中:默认查询词的信号强度是 1.0
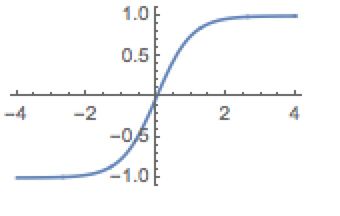
S 型函数是神经元负责对输入进行反馈的函数,在这里我们使用反双面正切变换函数(tanh),其函数图像为:
前馈算法代码如下:
private void feedForward(){
for(int i=0;i反向传播法调整权重矩阵
在跑完上面的前馈法预测出结果后,我们会发现所有的结果值都相同,因为以上建立的所有权重都是一样的默认值,因此预测的结果也是毫无价值的。接下去的工作就是调整各个节点之间的权重,使之拟合真实情况。
调整权重的核心工作是计算预测值与真实值之间的误差,用这个误差反向调整各个节点连接之间的权重。由于之前我们了 S 型函数进行信号反馈,其特点是结果在 0 附近变化特别快,而结果在 1 或 -1 附近时变化又特别缓慢,因此我们设计了一个 dtanh 函数来进行误差反向调整时加权,用以适应 tanh 函数的特性,dtanh 函数如下:
public static double dtanh(double y){
return 1.0 - y * y;
}
下面我们介绍反向传播法调整权重矩阵的具体步骤:
- 对于输出层的每个节点:
- 计算当前输出结果与期望结果之间的差距
- 利用 dtanh 函数确定节点的总输入需要如何改变
- 根据总输入需要改变的量,调整所有隐藏节点到输出节点间的权重
- 对于隐藏层中的每个节点:
- 计算由该隐藏层导致的输出层每个节点的误差,求和,即隐藏层需要改变的输出结果
- 利用 dtanh 函数确定节点的总输出需要如何改变
- 根据每个隐藏节点总输出需要改变的量,调整所有输入节点到隐藏节点间的权重
画成流程图如下:

如上图所示,红色虚线代表计算本节点需要作出改变的值,红色的实线代表一次权重调整后的值,每经过一次调整,整个网络就向真实情况逼近一点。
代码实现如下:
private void backPropagate(double[] targets){
//输出层误差
double[] output_deltas = new double[docIds.size()];
for(int k=0;k在调整完权重矩阵后,我们还需要将节点间关系数据保存到数据库,代码如下:
private void updateDatabase() throws SQLException {
for(int i=0;i训练流程汇总
首先我们回顾下训练神经网络的所有步骤,依次为:
- 建立隐藏层
- 前馈法预测结果
- 反向传播法调整权重矩阵
下面我们就可以写一个方法,进行一次完整的训练过程,代码如下:
public void train(List queryWordIds, List docIds, double[] targets) throws SQLException {
//增加隐藏节点
generateHiddenNode(queryWordIds, docIds);
//构建神经网络的权重矩阵
setupNetWork(queryWordIds, docIds);
//前馈法预测
feedForward();
//反向传播法调整权重矩阵
backPropagate(targets);
//将新的连接关系存入数据库
updateDatabase();
}
为了方便观察结果,我们添加一个 getResult 方法获取当前神经网络对输入的预测情况,代码如下:
public double[] getResult(List queryWordIds, List docIds) throws SQLException {
setupNetWork(queryWordIds, docIds);
feedForward();
return doc_val;
}
最后,就可以利用历史数据进行神经网络的训练了,如:
public static void main(String[] args) throws Exception {
String[] docs = new String[]{"儿童感冒", "玩具", "感冒药"};
//doc:儿童感冒, doc:玩具, doc:感冒药
List docIds = Arrays.asList(1, 2, 3);
//"儿童 感冒"
List queryWordIds_1 = Arrays.asList(1, 2);
double[] targets_1 = new double[]{1.0, 0.0, 1.0};
//"玩具"
List queryWordIds_2 = Arrays.asList(3);
double[] targets_2 = new double[]{0.0, 1.0, 0.0};
//"感冒"
List queryWordIds_3 = Arrays.asList(2);
double[] targets_3 = new double[]{0.0, 0.0, 1.0};
AnnRank annRank = new AnnRank();
for(int i=0;i<10;i++){
annRank.train(queryWordIds_1, docIds, targets_1);
annRank.train(queryWordIds_2, docIds, targets_2);
annRank.train(queryWordIds_3, docIds, targets_3);
}
//"儿童 玩具"
double[] rs = annRank.getResult(Arrays.asList(3), docIds);
System.out.println("========== query: 儿童 玩具 =========");
for(int i=0;i 输出:
========== query: 儿童 玩具 =========
儿童感冒:-0.04868859068035461
玩具:0.9509734260901455
感冒药:-0.20469923136438772
========== query: 儿童 =========
儿童感冒:0.933995702651645
玩具:-0.37891769815951537
感冒药:0.7154603176065658
总结
本文简单介绍了人工神经网络在搜索排序中的应用,在实际与搜索引擎的结合中,还有一些工程上的问题需要解决(如频繁数据库更新的效率问题),有兴趣的读者可以通过实践进行深入的了解。