由于学习Druid的中文资料很少,所以决定翻译官方文档,希望能帮助更多的小伙伴学习Druid,自己英语水平有限,哪里有翻译错的地方请联系我,我会及时修改。谢谢。
感谢优酷土豆张海雷技术大牛的帮助
概述(Overview)
原文链接:http://druid.io/docs/0.9.0/design/design.html
什么是Druid
Druid的创建允许获取大量很少变化的数据集,Druid设计的主要目的是作为一种服务面对代码部署、机器故障或者其他不可预测的事件发生的生产系统,能够保证100%的正常运行。
Druid现在可以做类似Dremel和PowerDrill的单表查询。同时增加了一些新特性:
1.为局部嵌套数据结构提供列式存储格式
2.分布式查询树模型
3.为快速过滤做索引
4.实时摄入数据和查询(摄入的数据是立即可用于查询)
5.高容错的分布式体系架构
至于和其他系统的比较,Druid功能介于Dremel和PowerDrill之间,Druid实现了几乎Dremel的所有功能(Dremel可以处理任意嵌套数据结构,而Druid只能处理单一的数组类型),从PowerDrill借鉴了一下比较实用的数据布局和压缩方法。
Druid是一个大数据流、单一的数据摄取产品的不错的选择。特别是如果你的目标是想构建一个无停机和流入的数据以时间为导向的产品,Druid很适合。当谈查询速度的话题时,要明确一个很重要说明,"fast"的意义是什么:Druid完全有可能实现不到一秒钟完成对数以万亿行数据的查询(官方已经测试成功)。
总体架构
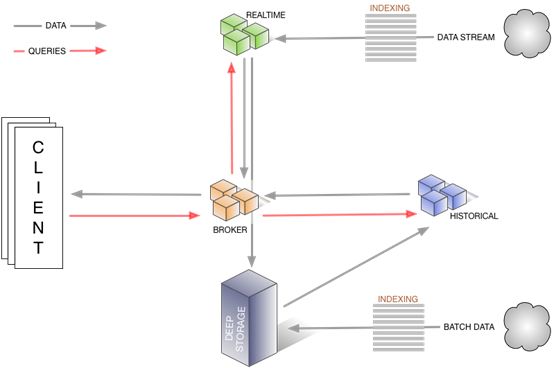
当前存在的节点类型:
1.Historical nodes历史节点负责处理历史数据存储和查询历史数据(非实时),历史节点从“deep storage”下载segments,将结果数据返回给broker节点,historical加载完segment通知Zookeeper,Historical nodes使用Zookeeper监控需要加载或者删除哪些新的segments。
2.Coordinator nodes协调节点对历史节点的分组进行监控,以确保数据可用,和最佳的配置。协调节点通过从元数据存储中读取元数据信息来判断哪些segments是应该加载到集群的,使用Zookeeper去判断哪些历史节点是存活的,在Zookeeper中创建任务条目告诉历史节点去加载和删除segments。
3.Broker nodes代理节点接收来自外部client的查询请求,并转发这些请求给实时节点和历史节点,当代理节点接收到结果时,将来自实时节点和历史节点的结果合并返回给调用方。为了知道整个拓扑结构,代理节点通过使用Zookeeper在确定哪些实时节点和历史节点存活。
4.Indexing Service索引服务节点由多个worker组成的集群,负责为加载批量的和实时的数据创建索引,并且允许对已经存在的数据进行修改。
5.Realtime nodes实时节点负责加载实时的数据到系统中,在生产使用的几个限制成本上实时节点比索引服务节点更容易搭建。
这种分离方式使每个节点只关心怎么才是使它运行的最好。通过把历史和实时处理分离开,我们把对内存的关注分离开,监听实时的流数据并处理它写入系统。我们分离协调节点和代理节点,我们把查询的需求分离开是为了在整个集群中维持良好的数据分布。
下图展示了通过这种架构如何查询数据和数据在这样的架构中是怎么传递的,以及在操作过程涉及到哪些节点。

所有的节点都是以高可用的方式运行,无论是作为无共享集群或者热插拔故障转移节点都是同等的看待。
除了这些节点还有三个外部依赖系统:
1.ZooKeeper集群主要作用是帮助群集服务发现和维护当前数据的拓扑结构
2.一个元数据实例,用户维护系统中segments的元数据
3.一个深度存储系统,负责存储segments(如hdfs、S3)
下图展示了集群的管理层级,显示特定节点和依赖的外部系统是如何通过跟踪和交换元数据的方式管理集群的。
