欢迎关注我个人公众号:周先生自留地,不定时更新

最开始谈NodeJS的时候写过一篇文章谈了它与Java各自的优缺点。NodeJS最早的定位是什么样的呢?最早开发者Ryan Dahl是想提升自己的工作效率,是为了开发一个高性能服务器,那高性能服务器的要求是什么呢?他觉得一个高性能服务器应该满足“事件驱动,非阻塞I/O模型”。最后,Ryan Dahl基于Chrome的V8引擎开发了NodeJS。正是由于NodeJS的出现,使得类似React/Vue/Angular这类前端框架大放异彩,NodeJS是这些框架开发环境的基础。
而NPM作为NodeJS的模块仓库,到目前为止存放模块已经超过15万个模块。了解过NodeJS的人都知道我们加载一个模块使用require语句去进行加载。那我们有必要去研究require语句的内部运行机制,它究竟是如何去加载一个模块的呢?
首先我们先看看require语句的基本用法:
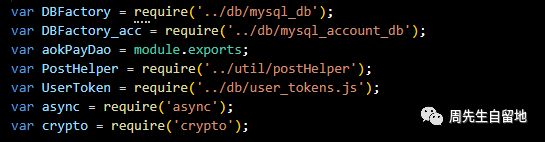
require语句是如何去查询并且加载到我们指定的文件?NodeJS处理require语句时一般有以下三种处理方式:

我们在路径D:\work\work\project\inde.js中引入crypto.js包,代码为:
var crypto =require('crypto');
搜索时首先确定这是属于上述的第三种情况,所以NodeJS内部运行过程是这样滴:
首先,确定crypto可能存在的目录位置:
D:\work\work\project\node_modules\crypto
D:\work\work\node_modules\crypto
D:\work\node_modules\crypto
D:\node_modules\crypto
然后将crypto当作一个文件名,依次进入目录开始搜索,只要搜索一个文件为crypto的文件则立即返回。顺序按照上面所说的逐一拼接文件后缀进行尝试:
cryptocrypto.js
crypto.json
crypto.node
如果在所有目录中都没有找到符合要求的文件,则说明crypto可能是一个目录。再次依次尝试加载crypto中的index文件。依次查找顺序为:
crypto/package.json
crypto/index.js
crypto/index.json
crypto/index.node
如果在所有目录都无法找到crypto对应的文件或者目录中的index文件,则返回异常。那么了解了NodeJS内部执行逻辑以后,我们可以阅读下NodeJS源码,看看require语句究竟是如何进行操作的。
首先我们下载一份NodeJS源码,require语句源码位置:
node\lib\internal\modules\cjs\loader.js
首先NodeJS有定义一个构造函数Module。所有的模块实质上都是构造函数Module的一个实例。
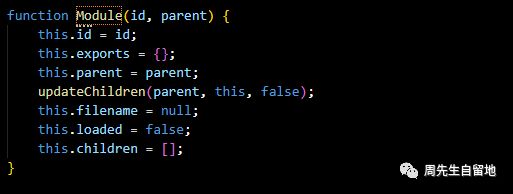
当前模块loader.js实际上也是Module的一个实例,在文件底部定义:
Module.Module = Module;
每一个实例都拥有自己的属性,一般有下列常用属性:
id: 没有父模块则id就是一个。若存在父模块则id和filename都是模块的绝对路径。parent:模块的父模块,模块没有依赖父模块,则parent为空filename:模块所在位置的决定路径loader:模块还未全部加载,则为false。模块全部加载则为true。path:模块可能存在的位置,为一个数组。
每个模块实例都存在一个require方法,所以require命令实质上是每个模块内部提供的一个内部方法。所以只有在模块内部才能使用require语句:

实际上require内部调用的方法为:
Module._load(path,this);
那我们再来看下_load()的源代码部分:

我们来解读一下这段源代码:
1.计算绝对路径,代码为:
varfilename = Module._resolveFilename(request,parent, isMain);
2.判断是否有缓存,有缓存则去除缓存中的数据
var cachedModule = Module._cache[filename];
if(cachedModule)
{
updateChildren(parent, cachedModule,true);
returncachedModule.exports;
}
3.判断模块是否为核心模块
if(NativeModule.nonInternalExists(filename)) {
returnNativeModule.require(filename);
}
4.生成模块的实例,并且将实例存入到缓存中
var module=newModule(filename, parent);
if(isMain) {
process.mainModule =module;
module.id ='.';
}
Module._cache[filename] =module;
5.加载模块
try{
module.load(filename);
threw =false;
}finally{
if(threw) {
deleteModule._cache[filename];
}
}
6.输出模块的属性
returnmodule.exports;
从上面的源码分析可以看出,其实看出Module._load(path, this)其实最主要的两个方法为:
Module._resolveFilename(request,parent,isMain):确定模块的绝对路径
module.load(filename):加载模块
那我们接着去看下_resolveFilename()的源代码:
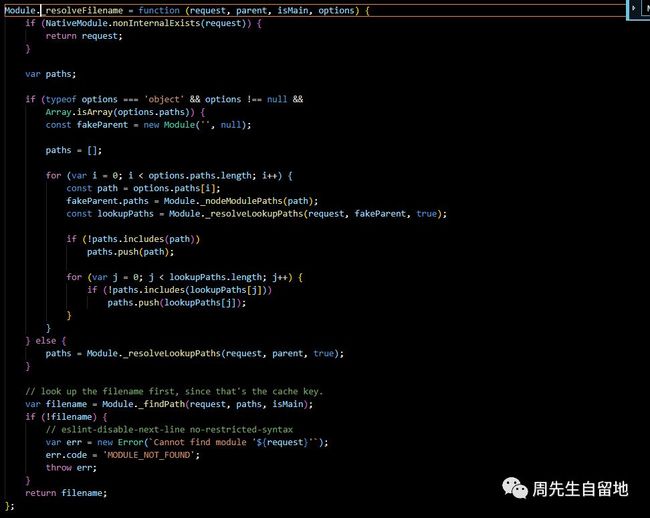
还记得文章开头我讲到的NodeJS文件查找有三种处理方式,内部定义的源码就在这里。接下来我们分析下源码:
如果为核心模块,直接返回模块,查找模块结束:
if(NativeModule.nonInternalExists(request)) {returnrequest;}
2.确定文件可能存在的所有路径
if(typeofoptions ==='object'&& options !==null&&Array.isArray(options.paths)) {
constfakeParent =newModule('',null);
paths = [];for(vari =0; i < options.paths.length; i++) {
constpath = options.paths[i];
fakeParent.paths = Module._nodeModulePaths(path);
constlookupPaths = Module._resolveLookupPaths(request, fakeParent,true);
if(!paths.includes(path))
paths.push(path);for(varj =0; j < lookupPaths.length; j++) {
if(!paths.includes(lookupPaths[j]))
paths.push(lookupPaths[j]);
}
}
}else{
paths = Module._resolveLookupPaths(request, parent,true);
}
3.确定哪一个路径为模块真是路径
var filename = Module._findPath(request, paths, isMain);
if(!filename) {
err.code ='MODULE_NOT_FOUND';
throw err;
}
returnfilename;
而我们可以发现在Module.resolveFilename()方法中最重要的两个方法分别是:
Module._resolveLookupPaths():查找模块所有可能存在的路径
Module._findPath():判断哪一个路径为模块的真实路径
我们继续先看下Module._resolveLookupPaths()源代码,由于本方法内容过多,只截取关键代码部分:

查询思想其实就是从目前所在的相对目录一直往外层递推去查找node_modules目录,最后以数组的形式将所有目录的路径返回;
查找到模块所有可能存在的路径之后,我们再来分析下Module._findPath() 的源码,用来确定到底哪一个是正确路径:
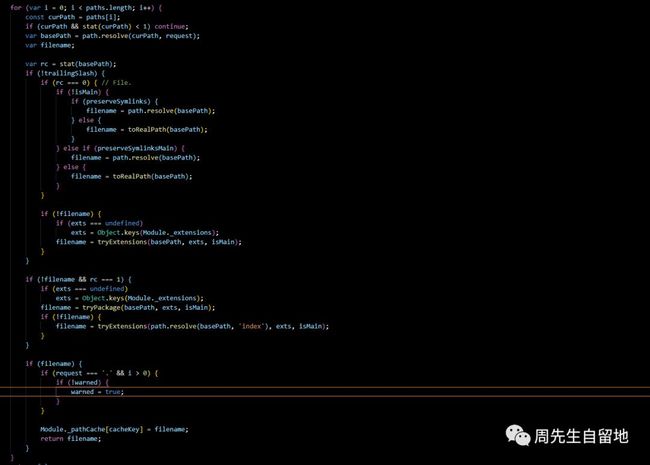
其实就是通过前面实例说过的几根步骤去逐一进行判断文件实际存在于哪个目录中:
1.列出所有可能的后缀名
2.如果是绝对路径,则无需继续搜索。
3.如果当前路径已在缓存中,则直接返回缓存
4.依次遍历所有路径,依次加上后缀看文件是否存在。
5.文件不存在则可能为目录,判断是否有目录/index文件或目录/package.json文件
6.若查找到文件则将文件路径存入缓存,然后返回。
7.若文件所有可能存在的路径遍历结束,未找到文件,则返回false
查找文件的真实路径说完了,那就只剩最后一个重点:关于加载模块的方法module.load()的源代码分析:
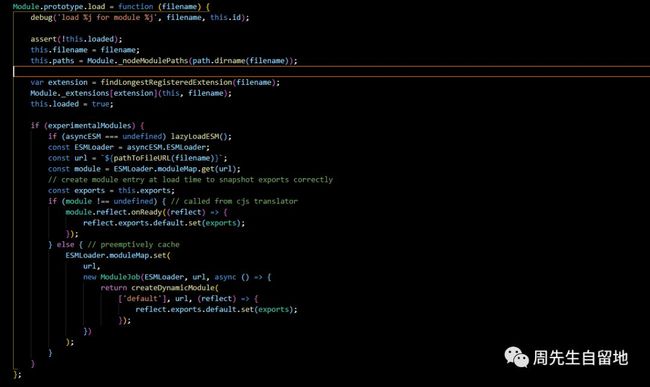
其实就是根据模块后缀名的不同采用不同的加载方式。判断模块后缀名调用了
findLongestRegisteredExtension(filename)
我们可以看下源码:

里面使用了Module._extensions[currentExtension]来针对不同后缀文件进行判断:

最后需要编译模块,用到了Module.prototype._compile()方法:

所以实质上加载模块的完整逻辑就是三个步骤:
1.传参exports,require,module三个全局变量
2.然后编译执行模块的源码
3.将模块的export变量进行输出。
本篇文章到这里对require语句的源码分析就完成了。很多人觉得有事没事扯源码目的就是提高逼格,其实读读源码我们可以学到很多东西,我们可以学习别人优美的代码书写,学习别人对设计模式的熟练使用,或者对整个系统架构的布局。对我们技术提升是有非常大的帮助的。
谢谢大家的观看,如果喜欢我的文章,欢迎关注我的个人公众号: 周先生自留地
