目录
- 第一章 impala的安装
- 1、impala的介绍
- imala基本介绍
- impala与hive的关系
- impala的优点
- impala的缺点:
- impala的架构以及查询计划
- 2、impala的安装环境准备
- 3、下载impala的所有依赖包
- 4、挂载磁盘
- 第一步:虚拟机关机新增磁盘
- 第二步:开机之后进行磁盘挂载
- 5、上传压缩包并解压
- 6、制作本地yum源
- 7、开始安装impala
- 8、所有节点配置impala
- 第一步:修改hive-site.xml
- 第二步:将hive的安装包发送到node02与node01机器上
- 第三步:node03启动hive的metastor服务
- 第四步:所有hadoop节点修改hdfs-site.xml添加以下内容
- 第五步:重启hdfs
- 第六步:创建hadoop与hive的配置文件的连接
- 第七步:修改impala的配置文件
- 所有节点修改impala默认配置
- 所有节点修改bigtop的java路径
- 第八步:启动impala服务
第一章 impala的安装
通过本地yum源进行安装impala
所有cloudera软件下载地址
http://archive.cloudera.com/cdh5/cdh/5/
http://archive.cloudera.com/cdh5/
1、impala的介绍
imala基本介绍
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sql工具,impala是参照谷歌的新三篇论文(Caffeine、Pregel、Dremel)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应我们即将学的HBase和已经学过的HDFS以及MapReduce
impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点
impala与hive的关系
impala是基于hive的大数据分析查询引擎,直接使用hive的元数据库metadata,意味着impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。所以需要安装impala的话,必须先安装hive,保证hive安装成功,并且还需要启动hive的metastore服务
impala的优点
1、 impala比较快,非常快,特别快,因为所有的计算都可以放入内存当中进行完成,只要你内存足够大
2、 摈弃了MR的计算,改用C++来实现,有针对性的硬件优化
3、 具有数据仓库的特性,对hive的原有数据做数据分析
4、支持ODBC,jdbc远程访问
impala的缺点:
1、基于内存计算,对内存依赖性较大
2、改用C++编写,意味着维护难度增大
3、基于hive,与hive共存亡,紧耦合
4、稳定性不如hive,不存在数据丢失的情况
impala的架构以及查询计划

Impala的架构模块:
- impala-server ==>启动的守护进程,执行我们的查询计划 从节点,官方建议与所有的datanode装在一起,可以通过hadoop的短路读取特性实现数据的快速查询
- impala-statestore ==》 状态存储区 主节点
- impalas-catalog ==》元数据管理区 主节点
查询执行
impalad分为frontend和backend两个层次, frondend用java实现(通过JNI嵌入impalad), 负责查询计划生成, 而backend用C++实现, 负责查询执行。
frontend生成查询计划分为两个阶段:
(1)生成单机查询计划,单机执行计划与关系数据库执行计划相同,所用查询优化方法也类似。
(2)生成分布式查询计划。 根据单机执行计划, 生成真正可执行的分布式执行计划,降低数据移动, 尽量把数据和计算放在一起。
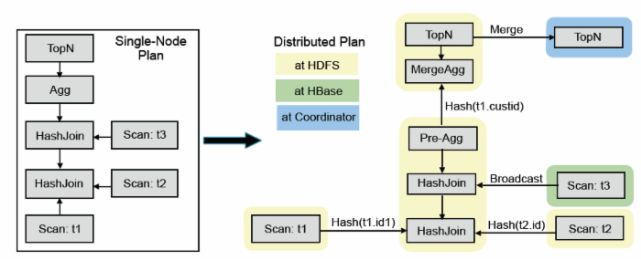
上图是SQL查询例子, 该SQL的目标是在三表join的基础上算聚集, 并按照聚集列排序取topN。
impala的查询优化器支持代价模型: 利用表和分区的cardinality,每列的distinct值个数等统计数据, impala可估算执行计划代价, 并生成较优的执行计划。 上图左边是frontend查询优化器生成的单机查询计划, 与传统关系数据库不同, 单机查询计划不能直接执行, 必须转换成如图右半部分所示的分布式查询计划。 该分布式查询计划共分成6个segment(图中彩色无边框圆角矩形), 每个segment是可以被单台服务器独立执行的计划子树。
impala支持两种分布式join方式, 表广播和哈希重分布:
表广播方式保持一个表的数据不动, 将另一个表广播到所有相关节点(图中t3);
哈希重分布的原理是根据join字段哈希值重新分布两张表数据(譬如图中t1和t2)。
分布式计划中的聚集函数分拆为两个阶段执行。第一步针对本地数据进行分组聚合(Pre-AGG)以降低数据量, 并进行数据重分步, 第二步, 进一步汇总之前的聚集结果(mergeAgg)计算出最终结果。
与聚集函数类似, topN也是分为两个阶段执行, (1)本地排序取topN,以降低数据量; (2) merge sort得到最终topN结果。
Backend从frontend接收plan segment并执行, 执行性能非常关键,impala采取的查询性能优化措施有向量执行。 一次getNext处理一批记录, 多个操作符可以做pipeline。LLVM编译执行, CPU密集型查询效率提升5倍以上。IO本地化。 利用HDFS short-circuit local read功能,实现本地文件读取Parquet列存,相比其他格式性能最高提升5倍。

2、impala的安装环境准备
需要提前安装好hadoop,hive,这二个框架,并且hive需要在所有的impala安装的节点上面都要有,因为impala需要引用hive的依赖包,hadoop的框架需要支持C程序访问接口,查看下图,如果有该路径下有这么些文件,就证明支持C接口 .
3、下载impala的所有依赖包
由于impala没有提供tar包供我们进行安装,只提供了rpm包,所以我们在安装impala的时候,需要使用rpm包来进行安装,rpm包只有cloudera公司提供了,所以我们去cloudera公司网站进行下载rpm包即可,但是另外一个问题,impala的rpm包依赖非常多的其他的rpm包,可以一个个的将依赖找出来,也可以将所有的rpm包下载下来,制作成我们本地yum源来进行安装。我们这里就选择制作我们本地的yum源来进行安装,所以首先我们需要下载到所有的rpm包,下载地址如下
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/cdh5.14.0-centos6.tar.gz
下载好了之后,保留下,留作备用
4、挂载磁盘
由于我们下载的tar包非常大,大概5个G,解压之后也最少需要5个G的空间,而我们的虚拟机磁盘有限,不够用了,所以我们可以为我们的虚拟机挂载一块磁盘,专门用于存储我们的tar包
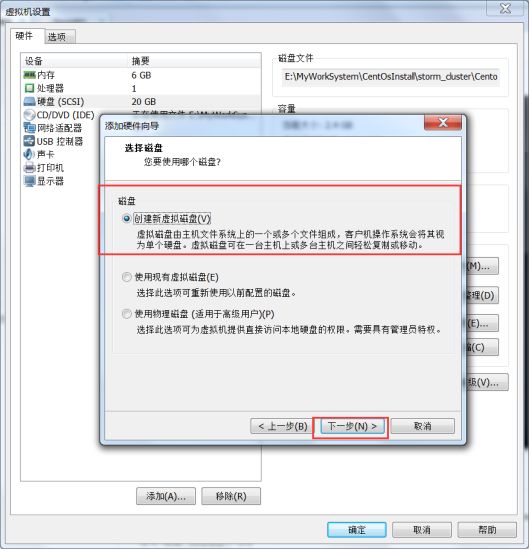
第一步:虚拟机关机新增磁盘
在我们的虚拟机关机的状态下,在VMware当中新增一块磁盘







第二步:开机之后进行磁盘挂载
分区,格式化,挂载新磁盘
磁盘挂载
df -lh
fdisk -l
#开始分区
fdisk /dev/sdb #这个命令执行后依次输 n p 1 回车 回车 w
fdisk -l
#格式化我们的分区
mkfs -t ext4 -c /dev/sdb1 #格式化我们的分区
mkdir /data02
#将我们的分区挂载到/data02目录下
mount -t ext4 /dev/sdb1 /data02
df -lh
#将我们的挂载磁盘设置开机启动,避免开机之后挂载的磁盘就没了
echo "/dev/sdb1 /data02 ext4 defaults 0 0" >> /etc/fstab

挂载完成之后,记得重新启动node03机器上面的mysql服务,datanode服务,nodemanager服务,zookeeper服务
启动mysql的服务命令:
/etc/init.d/mysqld start5、上传压缩包并解压
将我们5个G的压缩文件上传/data02(自己的目录下)目录下,并进行解压
#将我们5个G的压缩文件上传/data02(自己的目录下)目录下,并进行解压
cd /data02/
tar -zxvf cdh5.14.0-centos6.tar.gz
6、制作本地yum源
镜像源是centos当中下载相关软件的地址,我们可以通过制作我们自己的镜像源指定我们去哪里下载impala的rpm包,这里我们使用httpd这个软件来作为服务端,启动httpd的服务来作为我们镜像源的下载地址
这里我们选用第三台机器作为镜像源的服务端
node03机器上执行以下命令
#node03机器上执行以下命令
yum -y install httpd
service httpd start
cd /etc/yum.repos.d
vim localimp.repo
[localimp]
name=localimp
baseurl=http://node03/cdh5.14.0/
gpgcheck=0
enabled=1创建apache httpd的读取链接
ln -s /data02/cdh/5.14.0 /var/www/html/cdh5.14.0页面访问本地yum源,出现这个界面表示本地yum源制作成功
node03/cdh5.14.0
将制作好的localimp配置文件发放到所有需要安装impala的节点上去
#将制作好的localimp配置文件发放到所有需要安装impala的节点上去
cd /etc/yum.repos.d/
scp localimp.repo node02:$PWD
scp localimp.repo node01:$PWD注意:如果需要使用httpd来代理rpm的仓库,发布成为一个http的服务访问
一定要禁用linux的selinux服务
vim /etc/selinux/config # This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
#SELINUX=enforcing
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted7、开始安装impala
安装规划
| 服务名称 | node01 | node02 | node03 |
|---|---|---|---|
| impala-catalog | 不安装 | 不安装 | 安装 |
| impala-state-store | 不安装 | 不安装 | 安装 |
| impala-server | 安装 | 安装 | 安装 |
主节点node03执行以下命令进行安装
yum install impala -y
yum install impala-server -y
yum install impala-state-store -y
yum install impala-catalog -y
yum install impala-shell -y从节点node01与node02安装以下服务
yum install impala-server -y8、所有节点配置impala
第一步:修改hive-site.xml
node03 机器修改hive-site.xml内容如下
hive-site.xml配置
vim /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://node03.hadoop.com:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.cli.print.current.db
true
hive.cli.print.header
true
hive.server2.thrift.bind.host
node03.hadoop.com
-------------------------------------------------------------------------------------------------
#修改部分内容
-------------------------------------------------------------------------------------------------
hive.metastore.uris
thrift://node03.hadoop.com:9083
hive.metastore.client.socket.timeout
3600
-------------------------------------------------------------------------------------------------
#修改部分内容
-------------------------------------------------------------------------------------------------
第二步:将hive的安装包发送到node02与node01机器上
在 node03 机器上面执行
cd /export/servers/
scp -r hive-1.1.0-cdh5.14.0/ node02:$PWD
scp -r hive-1.1.0-cdh5.14.0/ node01:$PWD第三步:node03启动hive的metastor服务
启动hive的metastore服务
node03机器启动hive的metastore服务
cd /export/servers/hive-1.1.0-cdh5.14.0
nohup bin/hive --service metastore &
nohup bin/hive -- service hiveserver2 &有两个RunJar表示启动成功:

注意:一定要保证mysql的服务正常启动,否则metastore的服务不能够启动
第四步:所有hadoop节点修改hdfs-site.xml添加以下内容
所有节点创建文件夹
mkdir -p /var/run/hdfs-sockets修改所有节点的hdfs-site.xml添加以下配置,修改完之后重启hdfs集群生效
vim /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml添加到文件末尾:
dfs.client.read.shortcircuit
true
dfs.domain.socket.path
/var/run/hdfs-sockets/dn
dfs.client.file-block-storage-locations.timeout.millis
10000
dfs.datanode.hdfs-blocks-metadata.enabled
true
注意:root用户不需要这一步操作了,实际工作当中普通用户需要这一步操作
#创建文件夹
/var/run/hdfs-sockets/
#给这个文件夹赋予权限,例如如果我们用的是普通用户,那就直接赋予普通用户的权限
#例如:
chown -R hadoop:hadoop /var/run/hdfs-sockets/
因为我这里直接用的root用户,所以不需要赋权限了
第五步:重启hdfs
重启hdfs文件系统
node01服务器上面执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/stop-dfs.sh
sbin/start-dfs.sh第六步:创建hadoop与hive的配置文件的连接
impala的配置目录为:
/etc/impala/conf 这个路径下面需要把core-site.xml,hdfs-site.xml以及hive-site.xml拷贝到这里来,但是我们这里使用软连接的方式会更好
所有节点 执行以下命令创建链接到impala配置目录下来
ln -s /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
ln -s /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
ln -s /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /etc/impala/conf/hive-site.xml第七步:修改impala的配置文件
所有节点修改impala默认配置
所有节点更改impala默认配置文件以及添加mysql的连接驱动包
vim /etc/default/impalaIMPALA_CATALOG_SERVICE_HOST=node03
IMPALA_STATE_STORE_HOST=node03所有节点创建mysql的驱动包的软连接
ln -s /export/servers/hive-1.1.0-cdh5.14.0/lib/mysql-connector-java-5.1.38.jar
/usr/share/java/mysql-connector-java.jar
所有节点修改bigtop的java路径
所有节点修改bigtop的java_home路径
vim /etc/default/bigtop-utils
export JAVA_HOME=/export/servers/jdk1.8.0_141
第八步:启动impala服务
启动impala服务
主节点node03启动以下三个服务进程
service impala-state-store start
service impala-catalog start
service impala-server start从节点启动node01与node02启动impala-server
service impala-server start查看impala进程是否存在
ps -ef | grep impala 注意:启动之后所有关于impala的日志默认都在/var/log/impala 这个路径下,node03机器上面应该有三个进程,node02与node01机器上面只有一个进程,如果进程个数不对,去对应目录下查看报错日志
浏览器页面访问:
访问impalad的管理界面
http://node03:25000/
访问statestored的管理界面
http://node03:25010/
访问catalog的管理界面
http://node03:25020
下一篇计划:impala使用教程