透视表和交叉表
实现数据分析指标计算的常用操作:
交叉表 -> 透视表 -> 分组聚合 -> 自定义函数
- 交叉表就是聚合函数是len个数的透视表
- 透视表是由聚合函数是mean的分组旋转而成
- 分组聚合就是自定义函数的一种特定操作
越往底层书写越难,应用范围越广。越往上层书写越简单,应用范围越窄
透视表(pivot table)是各种电子表格程序和数据分析软件中一种高级数据汇总表格形式
它根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中
会不会操作透视表,是衡量一个人能否做数据分析项目的基准
- 入门:用Pandas原生的pivot_table方法生成透视表
- 进阶:使用groupby和unstack配合手动构造透视表
常用的crosstab交叉表函数结构
# 常见参数:行索引,列索引,分项小计
pd.crosstab(tips.time, [tips.smoker, tips.day], margins=True)
常用的Pivot_table 透视表函数结构
# 常见参数:需要计算的列,行索引,列索引,分项小计(默认False),自定义计算函数(默认是mean),缺失值填充
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker', margins=True, aggfunc=len, fill_value=0)
# 交叉表只要把 aggfunc参数值改为 len 即可
底层:使用分组聚合和轴向旋转实现透视表
# 分组:行索引,列索引;均值聚合;行索引转列索引;填充缺失值为0
tips.groupby(['time', 'day', 'smoker'])['size', 'tip_pct'].mean().unstack().fillna(0)
# 交叉表只要把聚合函数由.mean()改为.size()即可
In [1]:
import numpy as np
import pandas as pd
文件tips.csv
total_bill,tip,smoker,day,time,size
16.99,1.01,No,Sun,Dinner,2
10.34,1.66,No,Sun,Dinner,3
21.01,3.5,No,Sun,Dinner,3
23.68,3.31,No,Sun,Dinner,2
24.59,3.61,No,Sun,Dinner,4
25.29,4.71,No,Sun,Dinner,4
8.77,2.0,No,Sun,Dinner,2
26.88,3.12,No,Sun,Dinner,4
15.04,1.96,No,Sun,Dinner,2
14.78,3.23,No,Sun,Dinner,2
10.27,1.71,No,Sun,Dinner,2
35.26,5.0,No,Sun,Dinner,4
15.42,1.57,No,Sun,Dinner,2
18.43,3.0,No,Sun,Dinner,4
14.83,3.02,No,Sun,Dinner,2
21.58,3.92,No,Sun,Dinner,2
10.33,1.67,No,Sun,Dinner,3
16.29,3.71,No,Sun,Dinner,3
16.97,3.5,No,Sun,Dinner,3
20.65,3.35,No,Sat,Dinner,3
17.92,4.08,No,Sat,Dinner,2
20.29,2.75,No,Sat,Dinner,2
15.77,2.23,No,Sat,Dinner,2
39.42,7.58,No,Sat,Dinner,4
19.82,3.18,No,Sat,Dinner,2
17.81,2.34,No,Sat,Dinner,4
13.37,2.0,No,Sat,Dinner,2
12.69,2.0,No,Sat,Dinner,2
21.7,4.3,No,Sat,Dinner,2
19.65,3.0,No,Sat,Dinner,2
9.55,1.45,No,Sat,Dinner,2
18.35,2.5,No,Sat,Dinner,4
15.06,3.0,No,Sat,Dinner,2
20.69,2.45,No,Sat,Dinner,4
17.78,3.27,No,Sat,Dinner,2
24.06,3.6,No,Sat,Dinner,3
16.31,2.0,No,Sat,Dinner,3
16.93,3.07,No,Sat,Dinner,3
18.69,2.31,No,Sat,Dinner,3
31.27,5.0,No,Sat,Dinner,3
16.04,2.24,No,Sat,Dinner,3
17.46,2.54,No,Sun,Dinner,2
13.94,3.06,No,Sun,Dinner,2
9.68,1.32,No,Sun,Dinner,2
30.4,5.6,No,Sun,Dinner,4
18.29,3.0,No,Sun,Dinner,2
22.23,5.0,No,Sun,Dinner,2
32.4,6.0,No,Sun,Dinner,4
28.55,2.05,No,Sun,Dinner,3
18.04,3.0,No,Sun,Dinner,2
12.54,2.5,No,Sun,Dinner,2
10.29,2.6,No,Sun,Dinner,2
34.81,5.2,No,Sun,Dinner,4
9.94,1.56,No,Sun,Dinner,2
25.56,4.34,No,Sun,Dinner,4
19.49,3.51,No,Sun,Dinner,2
38.01,3.0,Yes,Sat,Dinner,4
26.41,1.5,No,Sat,Dinner,2
11.24,1.76,Yes,Sat,Dinner,2
48.27,6.73,No,Sat,Dinner,4
20.29,3.21,Yes,Sat,Dinner,2
13.81,2.0,Yes,Sat,Dinner,2
11.02,1.98,Yes,Sat,Dinner,2
18.29,3.76,Yes,Sat,Dinner,4
17.59,2.64,No,Sat,Dinner,3
20.08,3.15,No,Sat,Dinner,3
16.45,2.47,No,Sat,Dinner,2
3.07,1.0,Yes,Sat,Dinner,1
20.23,2.01,No,Sat,Dinner,2
15.01,2.09,Yes,Sat,Dinner,2
12.02,1.97,No,Sat,Dinner,2
17.07,3.0,No,Sat,Dinner,3
26.86,3.14,Yes,Sat,Dinner,2
25.28,5.0,Yes,Sat,Dinner,2
14.73,2.2,No,Sat,Dinner,2
10.51,1.25,No,Sat,Dinner,2
17.92,3.08,Yes,Sat,Dinner,2
27.2,4.0,No,Thur,Lunch,4
22.76,3.0,No,Thur,Lunch,2
17.29,2.71,No,Thur,Lunch,2
19.44,3.0,Yes,Thur,Lunch,2
16.66,3.4,No,Thur,Lunch,2
10.07,1.83,No,Thur,Lunch,1
32.68,5.0,Yes,Thur,Lunch,2
15.98,2.03,No,Thur,Lunch,2
34.83,5.17,No,Thur,Lunch,4
13.03,2.0,No,Thur,Lunch,2
18.28,4.0,No,Thur,Lunch,2
24.71,5.85,No,Thur,Lunch,2
21.16,3.0,No,Thur,Lunch,2
28.97,3.0,Yes,Fri,Dinner,2
22.49,3.5,No,Fri,Dinner,2
5.75,1.0,Yes,Fri,Dinner,2
16.32,4.3,Yes,Fri,Dinner,2
22.75,3.25,No,Fri,Dinner,2
40.17,4.73,Yes,Fri,Dinner,4
27.28,4.0,Yes,Fri,Dinner,2
12.03,1.5,Yes,Fri,Dinner,2
21.01,3.0,Yes,Fri,Dinner,2
12.46,1.5,No,Fri,Dinner,2
11.35,2.5,Yes,Fri,Dinner,2
15.38,3.0,Yes,Fri,Dinner,2
44.3,2.5,Yes,Sat,Dinner,3
22.42,3.48,Yes,Sat,Dinner,2
20.92,4.08,No,Sat,Dinner,2
15.36,1.64,Yes,Sat,Dinner,2
20.49,4.06,Yes,Sat,Dinner,2
25.21,4.29,Yes,Sat,Dinner,2
18.24,3.76,No,Sat,Dinner,2
14.31,4.0,Yes,Sat,Dinner,2
14.0,3.0,No,Sat,Dinner,2
7.25,1.0,No,Sat,Dinner,1
38.07,4.0,No,Sun,Dinner,3
23.95,2.55,No,Sun,Dinner,2
25.71,4.0,No,Sun,Dinner,3
17.31,3.5,No,Sun,Dinner,2
29.93,5.07,No,Sun,Dinner,4
10.65,1.5,No,Thur,Lunch,2
12.43,1.8,No,Thur,Lunch,2
24.08,2.92,No,Thur,Lunch,4
11.69,2.31,No,Thur,Lunch,2
13.42,1.68,No,Thur,Lunch,2
14.26,2.5,No,Thur,Lunch,2
15.95,2.0,No,Thur,Lunch,2
12.48,2.52,No,Thur,Lunch,2
29.8,4.2,No,Thur,Lunch,6
8.52,1.48,No,Thur,Lunch,2
14.52,2.0,No,Thur,Lunch,2
11.38,2.0,No,Thur,Lunch,2
22.82,2.18,No,Thur,Lunch,3
19.08,1.5,No,Thur,Lunch,2
20.27,2.83,No,Thur,Lunch,2
11.17,1.5,No,Thur,Lunch,2
12.26,2.0,No,Thur,Lunch,2
18.26,3.25,No,Thur,Lunch,2
8.51,1.25,No,Thur,Lunch,2
10.33,2.0,No,Thur,Lunch,2
14.15,2.0,No,Thur,Lunch,2
16.0,2.0,Yes,Thur,Lunch,2
13.16,2.75,No,Thur,Lunch,2
17.47,3.5,No,Thur,Lunch,2
34.3,6.7,No,Thur,Lunch,6
41.19,5.0,No,Thur,Lunch,5
27.05,5.0,No,Thur,Lunch,6
16.43,2.3,No,Thur,Lunch,2
8.35,1.5,No,Thur,Lunch,2
18.64,1.36,No,Thur,Lunch,3
11.87,1.63,No,Thur,Lunch,2
9.78,1.73,No,Thur,Lunch,2
7.51,2.0,No,Thur,Lunch,2
14.07,2.5,No,Sun,Dinner,2
13.13,2.0,No,Sun,Dinner,2
17.26,2.74,No,Sun,Dinner,3
24.55,2.0,No,Sun,Dinner,4
19.77,2.0,No,Sun,Dinner,4
29.85,5.14,No,Sun,Dinner,5
48.17,5.0,No,Sun,Dinner,6
25.0,3.75,No,Sun,Dinner,4
13.39,2.61,No,Sun,Dinner,2
16.49,2.0,No,Sun,Dinner,4
21.5,3.5,No,Sun,Dinner,4
12.66,2.5,No,Sun,Dinner,2
16.21,2.0,No,Sun,Dinner,3
13.81,2.0,No,Sun,Dinner,2
17.51,3.0,Yes,Sun,Dinner,2
24.52,3.48,No,Sun,Dinner,3
20.76,2.24,No,Sun,Dinner,2
31.71,4.5,No,Sun,Dinner,4
10.59,1.61,Yes,Sat,Dinner,2
10.63,2.0,Yes,Sat,Dinner,2
50.81,10.0,Yes,Sat,Dinner,3
15.81,3.16,Yes,Sat,Dinner,2
7.25,5.15,Yes,Sun,Dinner,2
31.85,3.18,Yes,Sun,Dinner,2
16.82,4.0,Yes,Sun,Dinner,2
32.9,3.11,Yes,Sun,Dinner,2
17.89,2.0,Yes,Sun,Dinner,2
14.48,2.0,Yes,Sun,Dinner,2
9.6,4.0,Yes,Sun,Dinner,2
34.63,3.55,Yes,Sun,Dinner,2
34.65,3.68,Yes,Sun,Dinner,4
23.33,5.65,Yes,Sun,Dinner,2
45.35,3.5,Yes,Sun,Dinner,3
23.17,6.5,Yes,Sun,Dinner,4
40.55,3.0,Yes,Sun,Dinner,2
20.69,5.0,No,Sun,Dinner,5
20.9,3.5,Yes,Sun,Dinner,3
30.46,2.0,Yes,Sun,Dinner,5
18.15,3.5,Yes,Sun,Dinner,3
23.1,4.0,Yes,Sun,Dinner,3
15.69,1.5,Yes,Sun,Dinner,2
19.81,4.19,Yes,Thur,Lunch,2
28.44,2.56,Yes,Thur,Lunch,2
15.48,2.02,Yes,Thur,Lunch,2
16.58,4.0,Yes,Thur,Lunch,2
7.56,1.44,No,Thur,Lunch,2
10.34,2.0,Yes,Thur,Lunch,2
43.11,5.0,Yes,Thur,Lunch,4
13.0,2.0,Yes,Thur,Lunch,2
13.51,2.0,Yes,Thur,Lunch,2
18.71,4.0,Yes,Thur,Lunch,3
12.74,2.01,Yes,Thur,Lunch,2
13.0,2.0,Yes,Thur,Lunch,2
16.4,2.5,Yes,Thur,Lunch,2
20.53,4.0,Yes,Thur,Lunch,4
16.47,3.23,Yes,Thur,Lunch,3
26.59,3.41,Yes,Sat,Dinner,3
38.73,3.0,Yes,Sat,Dinner,4
24.27,2.03,Yes,Sat,Dinner,2
12.76,2.23,Yes,Sat,Dinner,2
30.06,2.0,Yes,Sat,Dinner,3
25.89,5.16,Yes,Sat,Dinner,4
48.33,9.0,No,Sat,Dinner,4
13.27,2.5,Yes,Sat,Dinner,2
28.17,6.5,Yes,Sat,Dinner,3
12.9,1.1,Yes,Sat,Dinner,2
28.15,3.0,Yes,Sat,Dinner,5
11.59,1.5,Yes,Sat,Dinner,2
7.74,1.44,Yes,Sat,Dinner,2
30.14,3.09,Yes,Sat,Dinner,4
12.16,2.2,Yes,Fri,Lunch,2
13.42,3.48,Yes,Fri,Lunch,2
8.58,1.92,Yes,Fri,Lunch,1
15.98,3.0,No,Fri,Lunch,3
13.42,1.58,Yes,Fri,Lunch,2
16.27,2.5,Yes,Fri,Lunch,2
10.09,2.0,Yes,Fri,Lunch,2
20.45,3.0,No,Sat,Dinner,4
13.28,2.72,No,Sat,Dinner,2
22.12,2.88,Yes,Sat,Dinner,2
24.01,2.0,Yes,Sat,Dinner,4
15.69,3.0,Yes,Sat,Dinner,3
11.61,3.39,No,Sat,Dinner,2
10.77,1.47,No,Sat,Dinner,2
15.53,3.0,Yes,Sat,Dinner,2
10.07,1.25,No,Sat,Dinner,2
12.6,1.0,Yes,Sat,Dinner,2
32.83,1.17,Yes,Sat,Dinner,2
35.83,4.67,No,Sat,Dinner,3
29.03,5.92,No,Sat,Dinner,3
27.18,2.0,Yes,Sat,Dinner,2
22.67,2.0,Yes,Sat,Dinner,2
17.82,1.75,No,Sat,Dinner,2
18.78,3.0,No,Thur,Dinner,2
In [3]:
# 小费数据集
tips = pd.read_csv('examples/tips.csv')
# 生成一个新指标,小费占消费总额的百分比
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()
Out[3]:
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
In [4]:
# 抽取一个小表计算:
t2 = tips[['day', 'time', 'tip']]
t2.head()
Out[4]:
| day | time | tip | |
|---|---|---|---|
| 0 | Sun | Dinner | 1.01 |
| 1 | Sun | Dinner | 1.66 |
| 2 | Sun | Dinner | 3.50 |
| 3 | Sun | Dinner | 3.31 |
| 4 | Sun | Dinner | 3.61 |
例子:每周各天(day)的午餐晚餐(time)小费平均值(pivot_table的默认聚合类型)
使用Pandas自带透视表函数 pivot_table 实现
In [10]:
# 透视表
t2.pivot_table('tip', index='day', columns='time')
# 聚合运算列,行索引列,列索引列,缺失值填充
t2.pivot_table('tip', index='day', columns='time', fill_value=0) # 填充缺失值为0
Out[10]:
| time | Dinner | Lunch |
|---|---|---|
| day | ||
| Fri | 2.940000 | 2.382857 |
| Sat | 2.993103 | 0.000000 |
| Sun | 3.255132 | 0.000000 |
| Thur | 3.000000 | 2.767705 |
使用原生使用分组聚合(groupby)和重塑(unstack)功能实现
In [15]:
t2.groupby(['day', 'time'])['tip'].mean().unstack().fillna(0)
Out[15]:
| time | Dinner | Lunch |
|---|---|---|
| day | ||
| Fri | 2.940000 | 2.382857 |
| Sat | 2.993103 | 0.000000 |
| Sun | 3.255132 | 0.000000 |
| Thur | 3.000000 | 2.767705 |
根据day和smoker计算分组平均数,并将day和smoker放到行索引上
In [16]:
tips.head()
Out[16]:
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
In [17]:
# 透视表函数实现
tips.pivot_table(index=['day', 'smoker'])
Out[17]:
| size | tip | tip_pct | total_bill | ||
|---|---|---|---|---|---|
| day | smoker | ||||
| Fri | No | 2.250000 | 2.812500 | 0.151650 | 18.420000 |
| Yes | 2.066667 | 2.714000 | 0.174783 | 16.813333 | |
| Sat | No | 2.555556 | 3.102889 | 0.158048 | 19.661778 |
| Yes | 2.476190 | 2.875476 | 0.147906 | 21.276667 | |
| Sun | No | 2.929825 | 3.167895 | 0.160113 | 20.506667 |
| Yes | 2.578947 | 3.516842 | 0.187250 | 24.120000 | |
| Thur | No | 2.488889 | 2.673778 | 0.160298 | 17.113111 |
| Yes | 2.352941 | 3.030000 | 0.163863 | 19.190588 |
In [20]:
# 分组聚合实现
tips.groupby(['day', 'smoker']).mean()
tips.groupby(['day', 'smoker']).mean().sort_index(axis=1) # 按列索引排序
Out[20]:
| size | tip | tip_pct | total_bill | ||
|---|---|---|---|---|---|
| day | smoker | ||||
| Fri | No | 2.250000 | 2.812500 | 0.151650 | 18.420000 |
| Yes | 2.066667 | 2.714000 | 0.174783 | 16.813333 | |
| Sat | No | 2.555556 | 3.102889 | 0.158048 | 19.661778 |
| Yes | 2.476190 | 2.875476 | 0.147906 | 21.276667 | |
| Sun | No | 2.929825 | 3.167895 | 0.160113 | 20.506667 |
| Yes | 2.578947 | 3.516842 | 0.187250 | 24.120000 | |
| Thur | No | 2.488889 | 2.673778 | 0.160298 | 17.113111 |
| Yes | 2.352941 | 3.030000 | 0.163863 | 19.190588 |
如果只想聚合tip_pct和size,而且想根据time进行分组。再将smoker放到列索引上,把day放到行索引上
In [22]:
tips.head()
Out[22]:
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
In [24]:
# 透视表函数实现
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker')
Out[24]:

In [27]:
# 分组聚合实现
# 使用groupby和unstack实现
# 更底层、更基础的实现方式,透视表构造的原理和过程一步一步的展现
# groupby参数是行索引,后面的参数是列索引
tips.groupby(['time', 'day', 'smoker'])['size', 'tip_pct'].mean().unstack()
Out[27]:

pivot_table 其他参数
传入margins=True添加分项小计
这将会添加标签为All的行和列,其值对应于单个等级中所有数据的分组统计
All值为平均数:不单独考虑烟民与非烟民(All列),不单独考虑行分组两个级别中的任何单项(All行)
In [29]:
t2.pivot_table('tip', index='day', columns='time')
Out[29]:
| time | Dinner | Lunch |
|---|---|---|
| day | ||
| Fri | 2.940000 | 2.382857 |
| Sat | 2.993103 | NaN |
| Sun | 3.255132 | NaN |
| Thur | 3.000000 | 2.767705 |
In [30]:
t2.pivot_table('tip', index='day', columns='time', margins=True) # 分项小计,平均值
Out[30]:
| time | Dinner | Lunch | All |
|---|---|---|---|
| day | |||
| Fri | 2.940000 | 2.382857 | 2.734737 |
| Sat | 2.993103 | NaN | 2.993103 |
| Sun | 3.255132 | NaN | 3.255132 |
| Thur | 3.000000 | 2.767705 | 2.771452 |
| All | 3.102670 | 2.728088 | 2.998279 |
In [31]:
(2.940000 + 2.382857) / 2 # 对不上
Out[31]:
2.6614285
All统计求的是所有行或所有列的平均值,不是透视表那几行几列的平均值
In [32]:
(1+2+3+4+5)/5
Out[32]:
3.0
In [33]:
(1+2+3)/3
Out[33]:
2.0
In [34]:
(4+5)/2
Out[34]:
4.5
In [35]:
(2 + 4.5) / 2
Out[35]:
3.25
求所有dinner下tip的平均值
In [36]:
(2.940000 + 2.993103 + 3.255132 + 3.000000) / 4 # 对不上All
Out[36]:
3.04705875
In [37]:
t2.head()
Out[37]:
| day | time | tip | |
|---|---|---|---|
| 0 | Sun | Dinner | 1.01 |
| 1 | Sun | Dinner | 1.66 |
| 2 | Sun | Dinner | 3.50 |
| 3 | Sun | Dinner | 3.31 |
| 4 | Sun | Dinner | 3.61 |
In [42]:
# 求所有dinner下tip的平均值,和分项小计相等
t2[t2['time'] == 'Dinner']['tip'].mean()
Out[42]:
3.102670454545454
In [43]:
# 上例透视表,添加分项小计
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker', margins=True)
Out[43]:
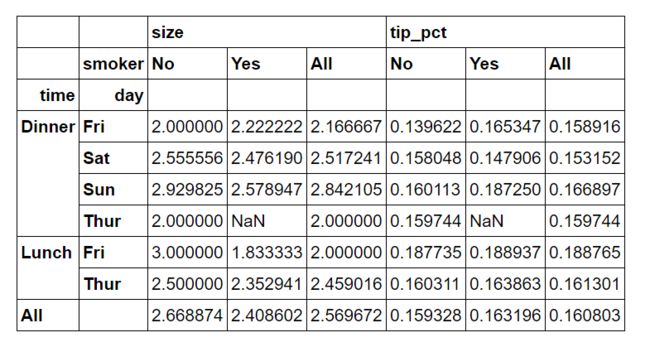
透视表默认聚合函数为mean平均值
如想使用非默认mean的其他的聚合函数,传给aggfunc即可(传入函数名称或函数字符串)
如使用count或len可得到有关分组大小的交叉表(计数或频率)
传入值类型,一般为 函数名字符串,函数名,numpy函数名:
len
'count'
np.max
In [48]:
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker', margins=True, aggfunc=len)
Out[48]:

fill_value参数填充缺失值(NA)
In [50]:
f = tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'], columns='smoker', margins=True, aggfunc=len, fill_value=0)
f
Out[50]:

In [52]:
# astype修改数据类型:np.int np.float
f.astype(np.int) # 改为整型
Out[52]:

交叉表:crosstab
交叉表(cross-tabulation,简称crosstab)是一种用于计算分组频率的特殊透视表
透视表由是分组后聚合函数为平均值的表旋转而成
交叉表就是聚合函数为个数的透视表
In [53]:
data = pd.DataFrame(
{
'Sample': np.arange(1,11),
'Nationality': ["USA", "Japan", "USA", "Japan", "Japan", "Japan", "USA", "USA", "Japan", "USA"],
'Handedness': ["Right-handed", "Left-handed", "Right-handed", "Right-handed", "Left-handed", "Right-handed", "Right-handed", "Left-handed", "Right-handed", "Right-handed"],
},
columns=['Sample', 'Nationality', 'Handedness']
)
data
Out[53]:
| Sample | Nationality | Handedness | |
|---|---|---|---|
| 0 | 1 | USA | Right-handed |
| 1 | 2 | Japan | Left-handed |
| 2 | 3 | USA | Right-handed |
| 3 | 4 | Japan | Right-handed |
| 4 | 5 | Japan | Left-handed |
| 5 | 6 | Japan | Right-handed |
| 6 | 7 | USA | Right-handed |
| 7 | 8 | USA | Left-handed |
| 8 | 9 | Japan | Right-handed |
| 9 | 10 | USA | Right-handed |
In [56]:
# 抽取单列
data['Nationality']
data.loc[:, 'Nationality']
data.Nationality
Out[56]:
0 USA
1 Japan
2 USA
3 Japan
4 Japan
5 Japan
6 USA
7 USA
8 Japan
9 USA
Name: Nationality, dtype: object
In [57]:
# 交叉表
pd.crosstab(data.Nationality, data.Handedness) # 1列行索引,1列列索引
Out[57]:
| Handedness | Left-handed | Right-handed |
|---|---|---|
| Nationality | ||
| Japan | 2 | 3 |
| USA | 1 | 4 |
In [58]:
# 添加分项小计
pd.crosstab(data.Nationality, data.Handedness, margins=True)
Out[58]:
| Handedness | Left-handed | Right-handed | All |
|---|---|---|---|
| Nationality | |||
| Japan | 2 | 3 | 5 |
| USA | 1 | 4 | 5 |
| All | 3 | 7 | 10 |
In [64]:
# 使用透视表实现交叉表效果
data.pivot_table('Sample', index='Nationality', columns='Handedness', aggfunc=len, margins=True) # 写法1
pd.pivot_table(data, index='Nationality', columns='Handedness', aggfunc=len, margins=True)['Sample'] # 写法2
Out[64]:
| Handedness | Left-handed | Right-handed | All |
|---|---|---|---|
| Nationality | |||
| Japan | 2 | 3 | 5 |
| USA | 1 | 4 | 5 |
| All | 3 | 7 | 10 |
In [67]:
# 底层实现:分组聚合和轴旋转实现交叉表效果
y = data.groupby(['Nationality', 'Handedness']).size().unstack()
y
Out[67]:
| Handedness | Left-handed | Right-handed |
|---|---|---|
| Nationality | ||
| Japan | 2 | 3 |
| USA | 1 | 4 |
In [69]:
# 增加分项小计行
y.sum()
y.loc['All'] = y.sum()
y
Out[69]:
| Handedness | Left-handed | Right-handed |
|---|---|---|
| Nationality | ||
| Japan | 2 | 3 |
| USA | 1 | 4 |
| All | 3 | 7 |
In [71]:
# 增加分项小计列
y.sum(axis=1)
y['All'] = y.sum(axis=1)
y
Out[71]:
| Handedness | Left-handed | Right-handed | All |
|---|---|---|---|
| Nationality | |||
| Japan | 2 | 3 | 5 |
| USA | 1 | 4 | 5 |
| All | 3 | 7 | 10 |
例子:小费数据 交叉表学习
In [72]:
tips.head()
Out[72]:
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
统计顾客在 每种用餐时间、每个星期下 的 吸烟数量情况
行索引:time,day
列索引:smoker
使用交叉表方法实现
In [75]:
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)
Out[75]:

In [77]:
pd.crosstab(tips.time, [tips.day, tips.smoker], margins=True)
Out[77]:

使用透视表方法实现
In [79]:
tips.head()
Out[79]:
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
In [80]:
pd.pivot_table(tips, index=['time', 'day'], columns='smoker', aggfunc=len, margins=True, fill_value=0)['size']
Out[80]:

使用分组聚合轴旋转实现
In [84]:
tips.groupby(['time', 'day', 'smoker']).size().unstack().fillna(0).astype(np.int)
Out[84]:
