使用selenium模拟浏览器进行数据抓取无疑是当下最通用的数据采集方案,它通吃各种数据加载方式,能够绕过客户JS加密,绕过爬虫检测,绕过签名机制。它的应用,使得许多网站的反采集策略形同虚设。由于selenium不会在HTTP请求数据中留下指纹,因此无法被网站直接识别和拦截。
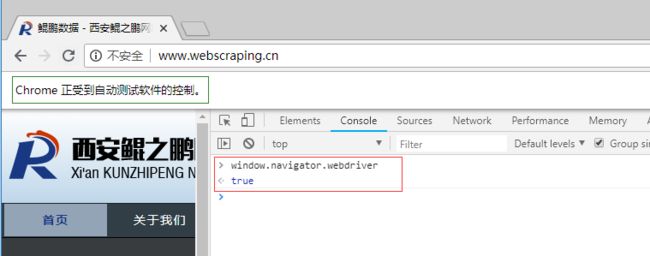
这是不是就意味着selenium真的就无法被网站屏蔽了呢?非也。selenium在运行的时候会暴露出一些预定义的Javascript变量(特征字符串),例如"window.navigator.webdriver",在非selenium环境下其值为undefined,而在selenium环境下,其值为true(如下图所示为selenium驱动下Chrome控制台打印出的值)。
除此之外,还有一些其它的标志性字符串(不同的浏览器可能会有所不同),常见的特征串如下所示:
webdriver
__driver_evaluate
__webdriver_evaluate
__selenium_evaluate
__fxdriver_evaluate
__driver_unwrapped
__webdriver_unwrapped
__selenium_unwrapped
__fxdriver_unwrapped
_Selenium_IDE_Recorder
_selenium
calledSelenium
_WEBDRIVER_ELEM_CACHE
ChromeDriverw
driver-evaluate
webdriver-evaluate
selenium-evaluate
webdriverCommand
webdriver-evaluate-response
__webdriverFunc
__webdriver_script_fn
__$webdriverAsyncExecutor
__lastWatirAlert
__lastWatirConfirm
__lastWatirPrompt
$chrome_asyncScriptInfo
$cdc_asdjflasutopfhvcZLmcfl_
了解了这个特点之后,就可以在浏览器客户端JS中通过检测这些特征串来判断当前是否使用了selenium,并将检测结果附加到后续请求之中,这样服务端就能识别并拦截后续的请求。
下面讲一个具体的例子。
鲲之鹏的技术人员近期就发现了一个能够有效检测并屏蔽selenium的网站应用:验证码表单页,如果是正常的浏览器操作,能够有效的通过验证,但如果是使用selenium就会被识别,即便验证码输入正确,也会被提示“请求异常,拒绝操作”,无法通过验证(如下图所示)。
可以看到它检测了"webdriver", "__driver_evaluate", "__webdriver_evaluate"等等这些selenium的特征串。提交验证码的时候抓包可以看到一个_token参数(很长),selenium检测结果应该就包含在该参数里,服务端借以判断“请求异常,拒绝操作”。
现在才进入正题,如何突破网站的这种屏蔽呢?
我们已经知道了屏蔽的原理,只要我们能够隐藏这些特征串就可以了。但是还不能直接删除这些属性,因为这样可能会导致selenium不能正常工作了。我们采用曲线救国的方法,使用中间人代理,比如fidder, proxy2.py或者mitmproxy,将JS文件(本例是yoda.*.js这个文件)中的特征字符串给过滤掉(或者替换掉,比如替换成根本不存在的特征串),让它无法正常工作,从而达到让客户端脚本检测不到selenium的效果。
下面我们验证下这个思路。这里我们使用mitmproxy实现中间人代理),对JS文件(本例是yoda.*.js这个文件)内容进行过滤。启动mitmproxy代理并加载response处理脚本:
mitmdump.exe -S modify_response.py
其中modify_response.py脚本如下所示:
# coding: utf-8
# modify_response.py
import re
from mitmproxy import ctx
def response(flow):
"""修改应答数据
"""
if '/js/yoda.' in flow.request.url:
# 屏蔽selenium检测
for webdriver_key in ['webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium', '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert', '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_']:
ctx.log.info('Remove "{}" from {}.'.format(webdriver_key, flow.request.url))
flow.response.text = flow.response.text.replace('"{}"'.format(webdriver_key), '"NO-SUCH-ATTR"')
flow.response.text = flow.response.text.replace('t.webdriver', 'false')
flow.response.text = flow.response.text.replace('ChromeDriver', '')
在selnium中使用该代理(mitmproxy默认监听127.0.0.1:8080)访问目标网站,mitmproxy将过滤JS中的特征符串,如下图所示:

经多次测试,该方法可以有效的绕过selenium检测,成功提交验证码表单。
抄自:http://www.site-digger.com/html/articles/20180821/653.html
成功
附上mitmproxy简单介绍(格式渣,可以直接访问原文)
抄自 https://blog.wolfogre.com/posts/usage-of-mitmproxy/
本文是一个较为完整的 mitmproxy 教程,侧重于介绍如何开发拦截脚本,帮助读者能够快速得到一个自定义的代理工具。
本文假设读者有基本的 python 知识,且已经安装好了一个 python 3 开发环境。如果你对 nodejs 的熟悉程度大于对 python,可移步到 anyproxy,anyproxy 的功能与 mitmproxy 基本一致,但使用 js 编写定制脚本。除此之外我就不知道有什么其他类似的工具了,如果你知道,欢迎评论告诉我。
本文基于 mitmproxy v4,当前版本号为 [v4.0.1]
(https://blog.wolfogre.com/redirect/v3/Ax7R98RpJpVlv3sgL6mHzyQSAwM8Cv46xcU7LxImWv3FLS8tPHP6U8UtLy08c_pTxSFXLjbFyDvFbf40bv4wbv4xMRIDAzwK_jrFxVoWBjtuQQYW3Dsh_cU8Bk0KxaQE-cwFzC0vLTxz-lPF)。
顾名思义,mitmproxy 就是用于 MITM 的 proxy,MITM 即中间人攻击(Man-in-the-middle attack)。用于中间人攻击的代理首先会向正常的代理一样转发请求,保障服务端与客户端的通信,其次,会适时的查、记录其截获的数据,或篡改数据,引发服务端或客户端特定的行为。
不同于 fiddler 或 wireshark 等抓包工具,mitmproxy 不仅可以截获请求帮助开发者查看、分析,更可以通过自定义脚本进行二次开发。举例来说,利用 fiddler 可以过滤出浏览器对某个特定 url 的请求,并查看、分析其数据,但实现不了高度定制化的需求,类似于:“截获对浏览器对该 url 的请求,将返回内容置空,并将真实的返回内容存到某个数据库,出现异常时发出邮件通知”。而对于 mitmproxy,这样的需求可以通过载入自定义 python 脚本轻松实现。
但 mitmproxy 并不会真的对无辜的人发起中间人攻击,由于 mitmproxy 工作在 HTTP 层,而当前 HTTPS 的普及让客户端拥有了检测并规避中间人攻击的能力,所以要让 mitmproxy 能够正常工作,必须要让客户端(APP 或浏览器)主动信任 mitmproxy 的 SSL 证书,或忽略证书异常,这也就意味着 APP 或浏览器是属于开发者本人的——显而易见,这不是在做黑产,而是在做开发或测试。
那这样的工具有什么实际意义呢?据我所知目前比较广泛的应用是做仿真爬虫,即利用手机模拟器、无头浏览器来爬取 APP 或网站的数据,mitmproxy 作为代理可以拦截、存储爬虫获取到的数据,或修改数据调整爬虫的行为。
事实上,以上说的仅是 mitmproxy 以正向代理模式工作的情况,通过调整配置,mitmproxy 还可以作为透明代理、反向代理、上游代理、SOCKS 代理等,但这些工作模式针对 mitmproxy 来说似乎不大常用,故本文仅讨论正向代理模式。
安装
“安装 mitmproxy”这句话是有歧义的,既可以指“安装 mitmproxy 工具”,也可以指“安装 python 的 mitmproxy 包”,注意后者是包含前者的。
pip install mitmproxy (windows)
运行
要启动 mitmproxy 用 mitmproxy、mitmdump、mitmweb 这三个命令中的任意一个即可,这三个命令功能一致,且都可以加载自定义脚本,唯一的区别是交互界面的不同。(我一般使用 mitmdump -s 脚本.py 命令运行)
脚本
脚本的编写需要遵循 mitmproxy 规定的套路,这样的套路有两个,使用时选其中一个套路即可。
第一个套路是,编写一个 py 文件供 mitmproxy 加载,文件中定义了若干函数,这些函数实现了某些 mitmproxy 提供的事件,mitmproxy 会在某个事件发生时调用对应的函数,形如:
import mitmproxy.http
from mitmproxy import ctx
num = 0
def request(flow: mitmproxy.http.HTTPFlow):
global num
num = num + 1
ctx.log.info("We've seen %d flows" % num)
第二个套路(我没成功)是,编写一个 py 文件供 mitmproxy 加载,文件定义了变量 addons,addons 是个数组,每个元素是一个类实例,这些类有若干方法,这些方法实现了某些 mitmproxy 提供的事件,mitmproxy 会在某个事件发生时调用对应的方法。这些类,称为一个个 addon,比如一个叫 Counter 的 addon:
import mitmproxy.http
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
def request(self, flow: mitmproxy.http.HTTPFlow):
self.num = self.num + 1
ctx.log.info("We've seen %d flows" % self.num)
addons = [
Counter()
]
事件
上述的脚本估计不用我解释相信大家也看明白了,就是当 request 发生时,计数器加一,并打印日志。这里对应的是 request 事件,那拢共有哪些事件呢?不多,也不少,这里详细介绍一下。
事件针对不同生命周期分为 5 类。“生命周期”这里指在哪一个层面看待事件,举例来说,同样是一次 web 请求,我可以理解为“HTTP 请求 -> HTTP 响应”的过程,也可以理解为“TCP 连接 -> TCP 通信 -> TCP 断开”的过程。那么,如果我想拒绝来个某个 IP 的客户端请求,应当注册函数到针对 TCP 生命周期 的 tcp_start 事件,又或者,我想阻断对某个特定域名的请求时,则应当注册函数到针对 HTTP 声明周期的 http_connect 事件。其他情况同理。
下面一段估计会又臭又长,如果你没有耐心看完,那至少看掉针对 HTTP 生命周期的事件,然后跳到示例。
1,针对 HTTP 生命周期
def http_connect(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 收到了来自客户端的 HTTP CONNECT 请求。在 flow 上设置非 2xx 响应将返回该响应并断开连接。CONNECT 不是常用的 HTTP 请求方法,目的是与服务器建立代理连接,仅是 client 与 proxy 的之间的交流,所以 CONNECT 请求不会触发 request、response 等其他常规的 HTTP 事件。
def requestheaders(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自客户端的 HTTP 请求的头部被成功读取。此时 flow 中的 request 的 body 是空的。
def request(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自客户端的 HTTP 请求被成功完整读取。
def responseheaders(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自服务端的 HTTP 响应的头部被成功读取。此时 flow 中的 response 的 body 是空的。
def response(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自服务端端的 HTTP 响应被成功完整读取。
def error(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 发生了一个 HTTP 错误。比如无效的服务端响应、连接断开等。注意与“有效的 HTTP 错误返回”不是一回事,后者是一个正确的服务端响应,只是 HTTP code 表示错误而已。
- 针对 TCP 生命周期
(懒得抄) - 针对 Websocket 生命周期
(懒得抄) - 针对网络连接生命周期
(懒得抄) - 通用生命周期
(懒得抄)
事实上考虑到 mitmproxy 的实际使用场景,大多数情况下我们只会用到针对 HTTP 生命周期的几个事件。再精简一点,甚至只需要用到 http_connect、request、response 三个事件就能完成大多数需求了