上一篇文章介绍了如何制作公众号标题的词云图。
这篇文章介绍制作公众号文章词云图
同样的,制作公众号文章词云图,也要先抓取公众号全部文章的内容。
但是 webscraper 无法一次性抓取到每篇文章的内容。
因为公众号网页版的文章链接,用的不是 html 里的 a 标签,而是在 h4 里面自定义了一个 hrefs 属性,它的属性值是真实的文章链接,需要用 Element attribute 选择器。
而 webscraper 不支持 Element attribute 创建子选择器,也就是我们无法在抓取文章链接的同时,跳转到文章内容页抓取内容。
所以,我们抓文章内容的时候,需要先抓取每篇文章的链接,然后把每篇文章的链接当做 start url 来抓取各自的内容。
webscraper 支持同一个 Sitemap 有多个start url,所以我们可以把抓取到所有文章链接,一次放到start url这个位置,如下图所示。
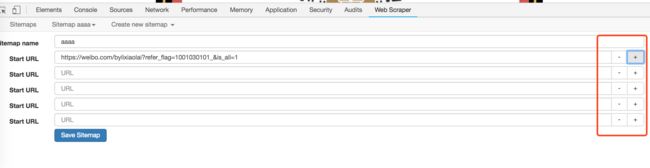
这种虽然可行,但如果文章数量比较大,几百篇的话,手动做这个动作,人可能会崩溃。
咋办呢?
大家记得之前几篇文章里,大家抓取的时候,我有让大家复制一段代码,如下:
{
"_id": "gzh-href",
"startUrl": [
"https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzIxODUxMDM5MQ==&scene=124&#wechat_redirect"
],
"selectors": [
{
"id": "total",
"type": "SelectorElementScroll",
"parentSelectors": [
"_root"
],
"selector": "div.weui_msg_card:nth-of-type(n+2)",
"multiple": true,
"delay": "1000"
},
{
"id": "link",
"type": "SelectorElementAttribute",
"parentSelectors": [
"total"
],
"selector": "h4.weui_media_title",
"multiple": false,
"extractAttribute": "hrefs",
"delay": 0
}
]
}
大家可以仔细看一下,里面有个start url 的参数,后面用中括号包围的,里面用双引号包围着一个 url 指,于是我猜,如果放多个 start url 的话,是不是用双引号包裹起来就行。
试了下,是对的。
那就好办了,复制链接到这个文件里面,比起复制到 webscraper 的界面里要轻松。
有没有更简洁的方法呢?
卧槽,我都差点忘了,我是个程序员了。
这种拼接字符串的活,python 最拿手了。
说干就干。虽然我好久没写代码了,写这个程序的时候,语法都是现查的,还好有些规则有印象,比如 for 循环,终端一提示这里有语法错误,我就能想起来要加冒号。
还有字符串的切片,我知道有某个函数功能,但是忘了怎么用,搜索一下找到例子,改改就OK了。
反正这样试了改,改了试,还是写出了了。
源代码放出来,(技术大佬别骂我):
#!/usr/bin/python
# coding = utf-8
import os
f1 = open('start_url.txt','r')
f2 = open('sitemap.txt','r')
lines = f1.readlines()
lines2 = f2.readlines()
for line in lines:
start_url = ',' + '''"''' + line.strip() +'''"'''
lines2.insert(4, start_url)
f3 = open('new_sitemap.txt','w')
f3.writelines(lines2)
f1.close()
f2.close()
f3.close()
print("finished!")
下面是如何使用这个代码,我已经找好了一个在线 python 编译器
1、用 webscraper 抓取所有文章的链接,需要用到的Sitemap 如下——
{
"_id": "gzh-href",
"startUrl": [
"https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzIxODUxMDM5MQ==&scene=124&#wechat_redirect"
],
"selectors": [
{
"id": "total",
"type": "SelectorElementScroll",
"parentSelectors": [
"_root"
],
"selector": "div.weui_msg_card:nth-of-type(n+2)",
"multiple": true,
"delay": "1000"
},
{
"id": "link",
"type": "SelectorElementAttribute",
"parentSelectors": [
"total"
],
"selector": "h4.weui_media_title",
"multiple": false,
"extractAttribute": "hrefs",
"delay": 0
}
]
}
抓取完成后,把第一列、第二列删掉,把第一行表头删掉。
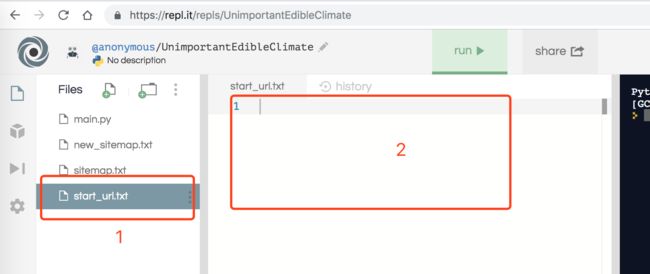
2、进入这个网站:https://repl.it/repls/UnimportantEdibleClimate
3、点击左侧 start_url.txt,然后在右边(标2处)填上第一步处理过的所有文章链接。
如下图
4、点击“run”,如下图
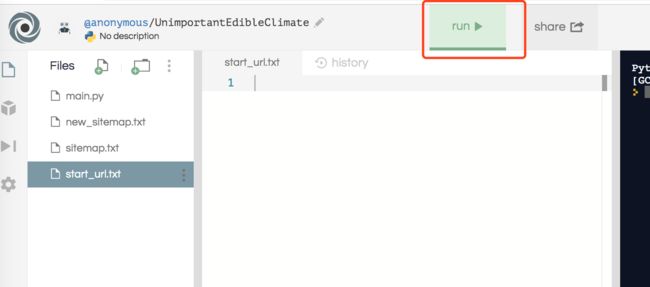
等待几秒钟,右面黑框处会出现一个finished!如下图

5、点击左侧 new_Sitemap.txt,这个文件里面就是抓取所有文章内容的 Sitemap,然后复制,导入到 webscraper就可以了。

剩下就和生成标题词云图的步骤一模一样了。
这里不在赘述。
我写作的一个网站,很好玩:http://www.zsxq100.com/