#目录
0.LockSupport & AQS
1.公平锁与非公平锁 ReentrantLock & ReadWriteLock
2.可重入锁(递归锁) ReentrantLock及synchronized
3.自旋锁
4.读写锁 ReadWriteLock & StampedLock
5.闭锁 CountDownLatch
6.栅栏 CyclicBarrier
7.信号量 Semaphore
8.Exchanger
9.synchronized
10.synchronized与Lock的区别
11.死锁
12.分布式锁
0.LockSupport & AQS
0.1 java.util.concurrent.locks.LockSupport
在Java多线程中,当需要阻塞或者唤醒一个线程时,都会使用LockSupport工具类来完成相应的工作。
LockSupport定义了一组公共静态方法,这些方法提供了最基本的线程阻塞和唤醒功能,
而LockSupport也因此成为了构建同步组件的基础工具。
实际上LockSupport阻塞和唤醒线程的功能是依赖于sun.misc.Unsafe,
这是一个很底层的类,比如park()方法的功能实现则是靠unsafe.park()方法。
另外在阻塞线程这一系列方法中,每个方法都会新增一个带有Object的阻塞对象的重载方法。
LockSupport定义了一组:
以park开头的方法用来阻塞当前线程,
以unpark(Thread)方法来唤醒一个被阻塞的线程
阻塞线程方法
| 方法 | 描述 |
|---|---|
| void park(): | 阻塞当前线程,如果调用unpark方法或者当前线程被中断,从能从park()方法中返回 |
| void park(Object blocker) | 功能同方法1,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查; |
| void parkNanos(long nanos) | 阻塞当前线程,最长不超过nanos纳秒,增加了超时返回的特性; |
| void parkNanos(Object blocker, long nanos) | 功能同方法3,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查; |
| void parkUntil(long deadline) | 阻塞当前线程,知道deadline; |
| void parkUntil(Object blocker, long deadline) | 功能同方法5,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查; |
唤醒线程方法
| 方法 | 描述 |
|---|---|
| void unpark(Thread thread) | 唤醒处于阻塞状态的指定线程 |
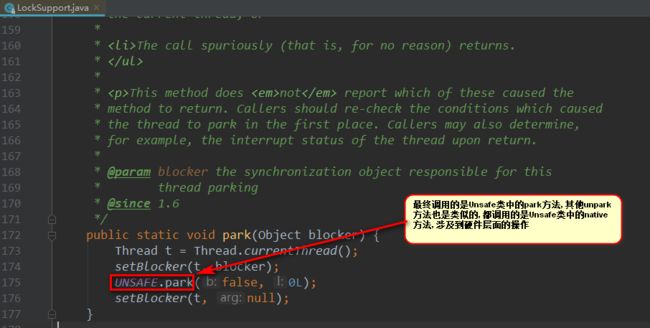
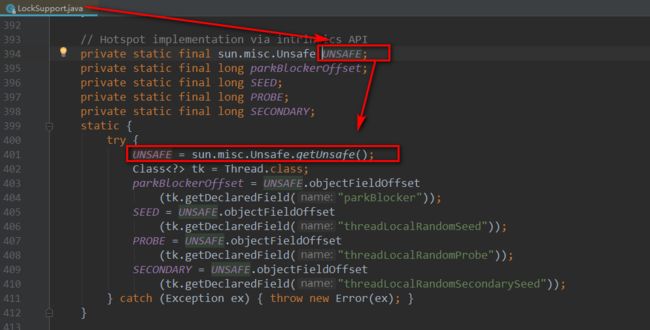
0.2 AQS(AbstractQueuedSynchronizer)
AQS是JDK下提供的一套用于实现基于FIFO等待队列的阻塞锁和相关的同步器的一个同步框架。
这个抽象类被设计为作为一些可用原子int值来表示状态的同步器的基类。
AQS管理一个关于状态信息的单一整数,该整数可以表现任何状态。
#比如
Semaphore 用它来表现剩余的许可数,
ReentrantLock 用它来表现拥有它的线程已经请求了多少次锁;
FutureTask 用它来表现任务的状态(尚未开始、运行、完成和取消)
使用须知(源码)
* Usage
*
* To use this class as the basis of a synchronizer, redefine the
* following methods, as applicable, by inspecting and/or modifying
* the synchronization state using {@link #getState}, {@link
* #setState} and/or {@link #compareAndSetState}:
*
*
* - {@link #tryAcquire}
*
- {@link #tryRelease}
*
- {@link #tryAcquireShared}
*
- {@link #tryReleaseShared}
*
- {@link #isHeldExclusively}
*
*
#以上方法不需要全部实现,根据获取的锁的种类可以选择实现不同的方法:
支持独占(排他)获取锁的同步器应该实现tryAcquire、 tryRelease、isHeldExclusively;
支持共享获取锁的同步器应该实现tryAcquireShared、tryReleaseShared、isHeldExclusively。
AQS浅析
AQS的实现主要在于维护一个"volatile int state"(代表共享资源)和
一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。
队列中的每个节点是对线程的一个封装,包含线程基本信息,状态,等待的资源类型等。
#state的访问方式有三种:
getState()
setState()
compareAndSetState()
#AQS定义两种资源共享方式
Exclusive(独占,只有一个线程能执行,如ReentrantLock)
Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)
不同的自定义同步器争用共享资源的方式也不同。
自定义同步器在实现时只需要实现共享资源state的获取与释放方式即可,
至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。
自定义同步器实现时主要实现以下几种方法:
>> isHeldExclusively():该线程是否正在独占资源。只有用到condition才需要去实现它。
>> tryAcquire(int):独占方式。尝试获取资源,成功则返回true,失败则返回false。
>> tryRelease(int):独占方式。尝试释放资源,成功则返回true,失败则返回false。
>> tryAcquireShared(int):共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
>> tryReleaseShared(int):共享方式。尝试释放资源,如果释放后允许唤醒后续等待结点返回true,否则返回false。
#以ReentrantLock为例
state初始化为0,表示未锁定状态。
A线程lock()时,会调用tryAcquire()独占该锁并将state+1。
此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。
当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。
但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
#以CountDownLatch以例
任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。
这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS减1。
等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
一般来说,自定义同步器要么是独占方法,要么是共享方式,
他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。
但AQS也支持自定义同步器同时实现独占和共享两种方式,如"ReentrantReadWriteLock"。
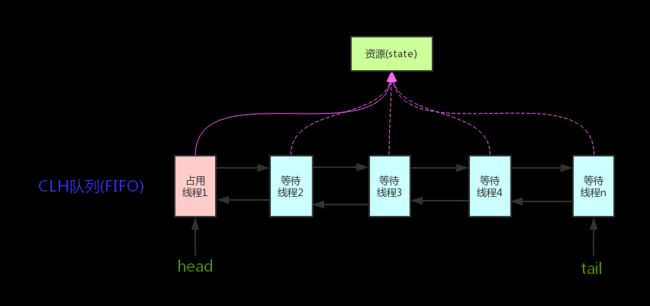
0.3锁基本概念
>> 公平锁/非公平锁
>> 可重入锁
>> 独享锁/共享锁
>> 互斥锁/读写锁
>> 乐观锁/悲观锁
>> 分段锁
>> 偏向锁/轻量级锁/重量级锁
>> 自旋锁
上面是很多锁的名词,这些分类并不是全是指锁的状态,有的指锁的特性,有的指锁的设计。
#公平锁/非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,
有可能后申请的线程比先申请的线程优先获取锁。
有可能,会造成优先级反转或者饥饿现象。
对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。
非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。
由于其并不像ReentrantLock是通过AQS的来实现线程调度,
所以并没有任何办法使其变成公平锁。
#可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。
ReentrantLock, Synchronized都是可重入锁。
可重入锁的一个好处是可一定程度避免死锁。
#独享(排他)锁/共享锁
独享锁是指该锁一次只能被一个线程所持有。
共享锁是指该锁可被多个线程所持有。
对于Java ReentrantLock而言,其是独享锁。
但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。
读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
对于Synchronized而言,当然是独享锁。
#互斥锁/读写锁
上面讲的独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。
互斥锁在Java中的具体实现就是ReentrantLock
读写锁在Java中的具体实现就是ReadWriteLock
#乐观锁/悲观锁
乐观锁与悲观锁不是指具体的什么类型的锁,而是指看待并发同步的角度。
>> 悲观锁 (Synchronized 和 ReentrantLock)
认为对于同一个数据的并发操作,一定是会发生修改的,哪怕没有修改,也会认为修改。
因此对于同一个数据的并发操作,悲观锁采取加锁的形式。
悲观的认为,不加锁的并发操作一定会出问题。
>> 乐观锁 (java.util.concurrent.atomic包)
认为对于同一个数据的并发操作,是不会发生修改的。
在更新数据的时候,会采用尝试更新,不断重新的方式更新数据。
乐观的认为,不加锁的并发操作是没有事情的。
悲观锁适合写操作非常多的场景,乐观锁适合读操作非常多的场景,
不加锁会带来大量的性能提升。
悲观锁在Java中的使用,就是利用各种锁。
乐观锁在Java中的使用,是无锁编程,常常采用的是CAS算法,
典型的例子就是原子类,通过CAS自旋实现原子操作的更新。
#分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,ConcurrentHashMap并发的实现就是通过分段锁的形式来实现高效的并发操作。
ConcurrentHashMap中的分段锁称为Segment,
它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,
即内部拥有一个Entry数组,数组中的每个元素又是一个链表;
同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
当需要put元素的时候,并不是对整个hashmap进行加锁,
而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,
所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。
但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,
就仅仅针对数组中的一项进行加锁操作。
#偏向锁/轻量级锁/重量级锁
这三种锁是指锁的状态,并且是针对Synchronized。
在Java 5通过引入锁升级的机制来实现高效Synchronized。
这三种锁的状态是通过对象监视器在对象头中的字段来表明的。
>> 偏向锁
是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
>> 轻量级锁
是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,
其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
>> 重量级锁
是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,
当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。
重量级锁会让其他申请的线程进入阻塞,性能降低。
#自旋锁
在Java中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,
这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
典型的自旋锁实现的例子,可以参考自旋锁的实现
1.公平锁与非公平锁
// 公平锁
Lock fairLock = new ReentrantLock(true);
是指多个线程按照申请锁的顺序来获取锁, 类似排队买票, 先到先得
// 非公平锁 (类似于 synchronized )
Lock unFairLock = new ReentrantLock(false);
是指多个线程获取锁的顺序并不是按照申请锁的顺序, 有可能后申请锁的先获取锁
在高并发场景下, 可能导致优先级反转或饥饿现象
可在一定程度上提升性能, 提升吞吐量
2.可重入锁(递归锁) (避免死锁) ReentrantLock及synchronized
指的是同一个线程外层函数获得锁之后, 内层递归函数仍然能获得该锁的代码,
即线程可以进行任何一个他已经获得锁的同步着的代码块。
若一个程序或子程序可以“在任意时刻被中断然后操作系统调度执行另外一段代码,
这段代码又调用了该子程序不会出错”,则称其为可重入(reentrant或re-entrant)的。
即当该子程序正在运行时,执行线程可以再次进入并执行它,仍然获得符合设计时预期的结果。
与多线程并发执行的线程安全不同,可重入强调对单个线程执行时重新进入同一个子程序仍然是安全的。
通俗来说:
当线程请求一个由其它线程持有的对象锁时,该线程会阻塞,
而当线程请求由自己持有的对象锁时,
如果该锁是重入锁,请求就会成功,否则阻塞。
#ReentrantLock版本
package com.zy;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LockFairLock {
public static void main(String[] args) {
ReentrantLockDemo reentrantLockDemo = new ReentrantLockDemo();
new Thread(reentrantLockDemo, "t1").start();
new Thread(reentrantLockDemo, "t2").start();
}
private static class ReentrantLockDemo implements Runnable {
private Lock lock = new ReentrantLock();
@Override
public void run() {
sendMsg();
}
private void sendMsg() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "---invoke sendMsg()");
sendEmail();
} finally {
lock.unlock();
}
}
private void sendEmail() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "---invoke sendEmail()");
} finally {
lock.unlock();
}
}
}
}
#synchronized版本
public static void main(String[] args) {
// ReentrantLockDemo reentrantLockDemo = new ReentrantLockDemo();
SynchronizedDemo synchronizedDemo = new SynchronizedDemo();
new Thread(() -> {
synchronizedDemo.sendMsg();
}, "t1").start();
new Thread(() -> {
synchronizedDemo.sendMsg();
}, "t2").start();
}
private static class SynchronizedDemo {
public synchronized void sendMsg() {
System.out.println(Thread.currentThread().getName() + "---invoke sendMsg()");
sendEmail();
}
private synchronized void sendEmail() {
System.out.println(Thread.currentThread().getName() + "---invoke sendEmail()");
}
}
3.自旋锁
简单来讲, 是指尝试获取锁的线程不会立即阻塞, 而是采用循环的方式去尝试获取锁,
优点是可以减少上下文切换的消耗, 缺点是循环会消耗CPU
自旋锁的原理比较简单,如果持有锁的线程能在短时间内释放锁资源,
那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞状态,
它们只需要等一等(自旋),等到持有锁的线程释放锁之后即可获取,这样就避免了用户进程和内核切换的消耗。
因为自旋锁避免了操作系统进程调度和线程切换,所以自旋锁通常适用在时间比较短的情况下。
由于这个原因,操作系统的内核经常使用自旋锁。
但是,如果长时间上锁的话,自旋锁会非常耗费性能,它阻止了其他线程的运行和调度。
线程持有锁的时间越长,则持有该锁的线程将被 OS(Operating System) 调度程序中断的风险越大。
如果发生中断情况,那么其他线程将保持旋转状态(反复尝试获取锁),
而持有该锁的线程并不打算释放锁,这样导致的是结果是无限期推迟,
直到持有锁的线程可以完成并释放它为止。
解决上面这种情况一个很好的方式是给自旋锁设定一个自旋时间,等时间一到立即释放自旋锁。
自旋锁的目的是占着CPU资源不进行释放,等到获取锁立即进行处理。
但是如何去选择自旋时间呢?
如果自旋执行时间太长,会有大量的线程处于自旋状态占用 CPU 资源,进而会影响整体系统的性能。
因此自旋的周期选的额外重要!
JDK在1.6 引入了适应性自旋锁,适应性自旋锁意味着自旋时间不是固定的了,
而是由前一次在同一个锁上的自旋时间以及锁拥有的状态来决定,
基本认为一个线程上下文切换的时间是最佳的一个时间。
自旋锁的优缺点
#优点
自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,
且占用锁时间非常短的代码块来说性能能大幅度的提升,
因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,
这些操作会导致线程发生两次上下文切换!
#缺点
但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,
这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用 cpu 做无用功,
占着 XX 不 XX,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,
线程自旋的消耗大于线程阻塞挂起操作的消耗,
其它需要 cpu 的线程又不能获取到 cpu,造成 cpu 的浪费。
所以这种情况下我们要关闭自旋锁。
排队自旋锁
// java.util.concurrent.atomic 包下的实现类
这种简单的自旋锁有一个问题:无法保证多线程竞争的公平性。
当多个线程想要获取锁时,可能会造成某些线程一直都未获取到锁造成线程饥饿。
// 解决方案
通常我们会采取排队的方式解决这样的问题,类似地,我们把这种锁叫排队自旋锁(QueuedSpinlock)。
就像我们下课后蜂拥的跑向食堂,下班后蜂拥地挤向地铁。
主要有: TicketLock,MCSLock,CLHLock。
package com.zy.tools.undefined.concurrent.lock.spinlock;
import java.util.concurrent.atomic.AtomicReference;
public class SpinLock {
// AtomicReference,CAS,compareAndSet保证了操作的原子性
private AtomicReference owner = new AtomicReference<>();
public void lock() {
// 如果锁未被占用,则设置当前线程为锁的拥有者,设置成功返回true,否则返回false
// null为期望值,currentThread为要设置的值,如果当前内存值和期望值null相等,替换为currentThread
while (!owner.compareAndSet(null, Thread.currentThread())) {
}
}
public void unlock() {
// 只有锁的拥有者才能释放锁,只有上锁的线程获取到的currentThread,才能和内存中的currentThread相等
owner.compareAndSet(Thread.currentThread(), null);
}
}
3.1 TicketLock
TicketLock 是一种同步机制或锁定算法,它是一种自旋锁,它使用ticket 来控制线程执行顺序。
就像票据队列管理系统一样。
面包店或者服务机构(例如银行)都会使用这种方式来为每个先到达的顾客记录其到达的顺序,
而不用每次都进行排队。
通常,这种地点都会有一个分配器(叫号器,挂号器等等都行),
先到的人需要在这个机器上取出自己现在排队的号码,
这个号码是按照自增的顺序进行的,旁边还会有一个标牌显示的是正在服务的标志,
这通常是代表目前正在服务的队列号,当前的号码完成服务后,标志牌会显示下一个号码可以去服务了。
像上面系统一样,TicketLock 是基于先进先出(FIFO) 队列的机制。
它增加了锁的公平性,其设计原则如下:
TicketLock 中有两个 int 类型的数值,开始都是0,
第一个值是队列ticket(队列票据), 第二个值是 出队(票据)。
队列票据是线程在队列中的位置,而出队票据是现在持有锁的票证的队列位置。
简单来说,就是队列票据是你取票号的位置,出队票据是你距离叫号的位置。
当叫号叫到你的时候,不能有相同的号码同时办业务,
必须只有一个人可以去办,办完后,叫号机叫到下一个人,这就叫做原子性。
你在办业务的时候不能被其他人所干扰,而且不可能会有两个持有相同号码的人去同时办业务。
然后,下一个人看自己的号是否和叫到的号码保持一致,如果一致的话,
那么就轮到你去办业务,否则只能继续等待。
上面这个流程的关键点在于,每个办业务的人在办完业务之后,
他必须丢弃自己的号码,叫号机才能继续叫到下面的人,
如果这个人没有丢弃这个号码,那么其他人只能继续等待。
3.2 CLHLock
3.2.1 前置知识
#SMP(Symmetric Multi-Processor)
即对称多处理器结构,指服务器中多个CPU对称工作,每个CPU访问内存地址所需时间相同。
其主要特征是共享,包含对CPU,内存,I/O等进行共享。
SMP的优点是能够保证内存一致性。
SMP的缺点是这些共享的资源很可能成为性能瓶颈,随着CPU数量的增加,
每个CPU都要访问相同的内存资源,可能导致内存访问冲突,可能会导致CPU资源的浪费。
常用的PC机就属于这种。
#NUMA(Non-Uniform Memory Access)
非一致存储访问,将CPU分为CPU模块,每个CPU模块由多个CPU组成,
并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问,
访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,
这也是非一致存储访问NUMA的由来。
优点是可以较好地解决原来SMP系统的扩展问题,
缺点是由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。
#CLH
>> CLH队列锁的优点
空间复杂度低。
如果有n个线程,L个锁,每个线程每次只获取一个锁,
那么需要的存储空间是O(L+n),n个线程有n个myNode,L个锁有L个tail,
CLH的一种变体被应用在了JAVA并发框架AQS中。
>> CLH队列锁的缺点
在NUMA系统结构下性能很差,在这种系统结构下,每个线程有自己的内存,
如果前趋结点的内存位置比较远,自旋判断前趋结点的locked域,
性能将大打折扣,但是在SMP系统结构下该法还是非常有效的。
一种解决NUMA系统结构的思路是MCS队列锁。
3.2.2 CLH Lock
package com.zy.tools.undefined.concurrent.lock.spinlock;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicReference;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
/**
* CLH锁是自旋锁的一种,AQS源代码中使用了CLH锁的一个变种
* CLH Lock是独占式锁的一种,并且是不可重入的锁
*
* CLH的算法定义
* CLH lock is Craig, Landin, and Hagersten (CLH) locks,
* CLH lock is a spin lock, can ensure no hunger, provide fairness first come first service.
* The CLH lock is a scalable, high performance, fairness and spin lock based on the list,
* the application thread spin only on a local variable,
* it constantly polling the precursor state, if it is found that the pre release lock end spin.
*
*/
public class ClhSpinLock implements Lock {
private final ThreadLocal prev;
private final ThreadLocal node;
// step1.初始状态 tail指向一个node(head)节点
private final AtomicReference tail = new AtomicReference<>(new QNode());
public ClhSpinLock() {
this.node = ThreadLocal.withInitial(QNode::new);
this.prev = ThreadLocal.withInitial(() -> null);
}
/**
* 1.初始状态 tail 指向一个node(head)节点
* +------+
* | head | <---- tail
* +------+
*
* 2.lock-thread 加入等待队列: tail指向新的Node,同时Prev指向tail之前指向的节点
* +----------+
* | Thread-A |
* | := Node | <---- tail
* | := Prev | -----> +------+
* +----------+ | head |
* +------+
*
* +----------+ +----------+
* | Thread-B | | Thread-A |
* tail ----> | := Node | --> | := Node |
* | := Prev | ----| | := Prev | -----> +------+
* +----------+ +----------+ | head |
* +------+
* 3.寻找当前node的prev-node然后开始自旋
*
*/
@Override
public void lock() {
final QNode qNode = this.node.get();
qNode.locked = true;
// step2.thread 加入等待队列: tail指向新的Node,同时 prev 指向 tail 之前指向的节点
QNode pred = this.tail.getAndSet(qNode);
this.prev.set(pred);
// step3.自旋: 寻找当前线程对应的node的前驱node然后开始自旋前驱node的status判断是否可以获取lock
while (pred.locked);
}
@Override
public void unlock() {
// 获取当前线程的node,设置lock status,将当前node指向前驱node(这样操作tail指向的就是前驱node等同于出队操作).
QNode qNode = this.node.get();
qNode.locked = false;
this.node.set(this.prev.get());
}
@Override
public boolean tryLock() {
return false;
}
@Override
public boolean tryLock(long time, TimeUnit unit) {
return false;
}
@Override
public void lockInterruptibly() throws InterruptedException {
}
@Override
public Condition newCondition() {
return null;
}
private static class QNode {
public volatile boolean locked;
}
}
3.2.3 MCS Lock
4.读写锁ReadWriteLock(乐观锁) (共享锁, 及独占锁)
ReadWriteLock 维护了一对相关的锁,
一个用于只读操作,另一个用于写入操作。
只要没有 writer,读取锁可以由多个 reader 线程同时保持。
写入锁是独占的。
ReadWriteLock
读取操作通常不会改变共享资源,
但执行写入操作时,必须独占方式来获取锁。
对于读取操作占多数的数据结构。
ReadWriteLock 能提供比独占锁更高的并发性。
而对于只读的数据结构,其中包含的不变性可以完全不需要考虑加锁操作。
package com.zy.lock;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReadWriteLockDemo {
private volatile Map map = new HashMap<>();
private ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
public void put(String key, Object value) {
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "线程正在写入key--" + key);
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "线程写入key--" + key + "完成");
} finally {
readWriteLock.writeLock().unlock();
}
}
public void get(String key) {
readWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "线程正在读取key--" + key);
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "线程读取key--" + key + "完成, value是" + map.get(key));
} finally {
readWriteLock.readLock().unlock();
}
}
public static void main(String[] args) {
ReadWriteLockDemo demo = new ReadWriteLockDemo();
for (int i = 0; i < 5; i ++) {
int finalI = i;
new Thread(() -> {
demo.put(String.valueOf(finalI), UUID.randomUUID().toString().substring(0, 3));
demo.get(String.valueOf(finalI));
}).start();
}
}
}
5.CountDownLatch(闭锁-->减法计数)
CountDownLatch是通过AbstractQueuedSynchronizer来实现的,
构造器有一个计数器, 计数器的初始值为线程的数量。
每当一个线程完成了自己的任务后,计数器的值就会减1。
当计数器值到达0时,它表示所有的线程已经完成了任务,
然后在闭锁上等待的线程就可以恢复执行任务。
构造器中的计数值(count)实际上就是闭锁需要等待的线程数量。
这个值只能被设置一次,而且CountDownLatch没有提供任何机制去重新设置这个计数值。
#举例
期末考试要开始了,监考老师发下去试卷,然后坐在讲台旁边玩着手机等待着学生答题,有的学生提前交了试卷,并约起打球了,等到最后一个学生交卷了,老师开始整理试卷,贴封条,下班,陪老婆孩子去了。
应用场景
(1)开启多个线程分块下载一个大文件,
每个线程只下载固定的一截,最后由另外一个线程来拼接所有的分段。
(2)应用程序的主线程希望在负责启动框架服务的线程已经启动所有的框架服务之后再执行。
(3)确保一个计算不会执行,直到所需要的资源被初始化。
package com.zy.concurrent;
import java.util.concurrent.CountDownLatch;
public class CountDownLatchDemo {
/**
* 递减的计数器, 若未能到达预定值, 则一直阻塞
*
* @param args
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException {
// 可以通过修改构造参数中的 count 的值, 来观察控制台打印的结果的情况
CountDownLatch latch = new CountDownLatch(5);
for (int i = 0; i < 5; i++) {
new Thread(() -> {
latch.countDown();
System.out.println(Thread.currentThread().getName() + "-->is running");
}, "thread" + i).start();
}
latch.await();
System.out.println("main thread ---");
}
}
6.CyclicBarrier(栅栏-->加法计数)
栅栏类似于闭锁,它能阻塞一组线程直到某个事件的发生。
栅栏与闭锁的关键区别在于,所有的线程必须同时到达栅栏位置,才能继续执行。
闭锁用于等待事件,而栅栏用于等待其他线程。
CyclicBarrier可以使一定数量的线程反复地在栅栏位置处汇集。
当线程到达栅栏位置时将调用await方法,这个方法将阻塞直到所有线程都到达栅栏位置。
如果所有线程都到达栅栏位置,那么栅栏将打开,此时所有的线程都将被释放,而栅栏将被重置以便下次使用。
#举例
长途汽车站提供长途客运服务。
当等待坐车的乘客到达20人时,汽车站就会发出一辆长途汽车,让这20个乘客上车走人。
否则(如只有15个人时), 这些人要一直等到等到下次等待的乘客又到达20人时,才会发下一辆长途汽车。
与CountDownLatch的对比
CountDownLatch的计数器只能使用一次,
CyclicBarrier的计数器可以使用reset()方法重置,可以使用多次,
所以CyclicBarrier能够处理更为复杂的场景
CyclicBarrier还提供了一些其他有用的方法,
比如getNumberWaiting()方法可以获得CyclicBarrier阻塞的线程数量,
isBroken()方法用来了解阻塞的线程是否被中断;
CountDownLatch一般用于某个线程A(如主线程)等待若干个其他线程执行完任务之后,它才执行;
CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
应用场景
CyclicBarrier常用于多线程分组计算。
package com.zy.concurrent;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierDemo {
/**
* 用于多组资源的分别计算, 之后整合
* 只有当任务数是构造参数的整数倍时, 所有任务才可能全部执行
* 否则, 只能执行构造参数值的最大整数倍个任务, 其余的任务一直等待 ...
* @param args
*/
public static void main(String[] args) {
// 可以通过修改构造参数中的 count 的值来观察控制台结果打印情况
CyclicBarrier cyclicBarrier = new CyclicBarrier(2);
for (int i = 0; i < 4; i ++) {
new Thread(() -> {
try {
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + " is running");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}, "thread" + i).start();
}
System.out.println("main thread....");
}
}
7.Semaphore(信号量, 用于共享资源互斥or并发线程数控制)
#应用场景:
有一个停车场只有5个车位,现在有100辆车要去抢这个5个车位,
理想情况下最多只有五辆车同时可以抢到车位,
那么没有抢到车位的车只能等到,其他的车让出车位,才有机会去使用该车位。
Semaphore可以用于做流量控制,特别公用资源有限的应用场景,比如数据库连接。
假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,
我们可以启动几十个线程并发的读取,但是如果读到内存后,还需要存储到数据库中,
而数据库的连接数只有10个,这时我们必须控制只有十个线程同时获取数据库连接保存数据,
否则会报错无法获取数据库连接。
这个时候,我们就可以使用Semaphore来做流控。
package com.zy.concurrent;
import java.util.concurrent.Semaphore;
public class SemaphoreDemo {
/**
* 用于作为线程的信号量或者是计数器
* 如: 停车场有3个车位, 但是来了8辆车, 则先进3辆, 待有车离开后, 再进后几辆
* @param args
*/
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3, true); // 模拟3个停车位
for (int i = 0; i < 8; i ++) { // 模拟8辆车
new Thread(() -> {
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + " is running");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 可以通过注释本行代码, 来观察控制台结果打印情况
semaphore.release();
}
}, "thread " + i).start();
}
System.out.println("main thread ...");
}
}
8.Exchanger
#用法:
此类提供对外的操作是同步的;
用于成对出现的线程之间交换数据;
可以视作双向的同步队列;
可应用于基因算法、流水线设计等场景。
Exchanger类仅可用作两个线程的信息交换,
当超过两个线程调用同一个exchanger对象时,得到的结果是随机的,
exchanger对象仅关心其包含的两个“格子”是否已被填充数据,
当两个格子都填充数据完成时,该对象就认为线程之间已经配对成功,然后开始执行数据交换操作。
package com.zy.tools.undefined.concurrent.lock;
import java.util.concurrent.Exchanger;
public class ExchangerDemo {
public static void main(String[] args) {
Exchanger exchanger = new Exchanger<>();
new Thread(() -> {
try {
int a = 3;
a = exchanger.exchange(a);
System.out.println("a------" + a); // 10
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
int b = 10;
b = exchanger.exchange(b);
System.out.println("b-----" + b); // 3
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
9.synchronized
#sychronized 应用方式
>> 1.作用于实例方法,当前实例加锁,进入同步代码块时需要获得当前实例的锁;
>> 2.作用于静态方法,当前类加锁,进去同步代码前需要获取当前类的锁;
>> 3.作用于代码块,这需要指定加锁对象,对所给的指定对象加锁,进入同步代码块前要获得指定对象的锁;
9.3 sychronized底层原理
java虚拟机中的同步Synchronization基于进入和退出管程Monitor对象实现。
在java中,sychronized可以修饰同步方法,
同步方法不是由monitorenter和moniterexit指令来实现同步,而是由方法调用指令读取运行时常量池中的ACC_SYNCHRONIZED标注来隐式调用的。
在java中,对象在内存中的布局分为三块区域,对象头,实例数据和填充数据。
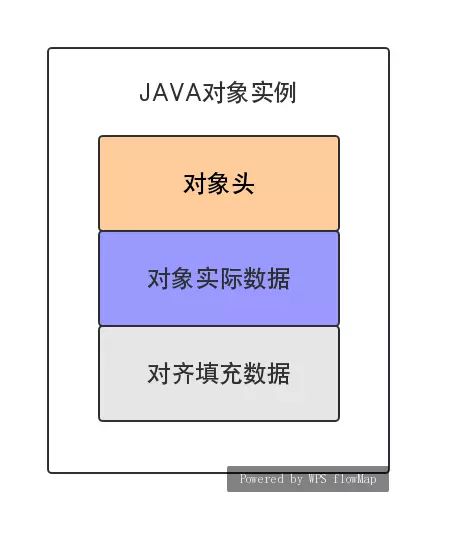
#1、对象头
HotSpot虚拟机的对象头包括markword和klass,数组长度;
>> markword
用于存储对象自身的运行时数据,如哈希码(HashCode)、
GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,
这部分数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为32bit和64bit。
>> klass类型指针
即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
>> 数组长度
如果对象是一个数组, 那在对象头中还必须有一块数据用于记录数组长度。
#2、实例数据
实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。
无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。
#3、对象填充
对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。
由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,
换句话说,就是对象的大小必须是8字节的整数倍。
而对象头部分正好是8字节的倍数(1倍或者2倍),
因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
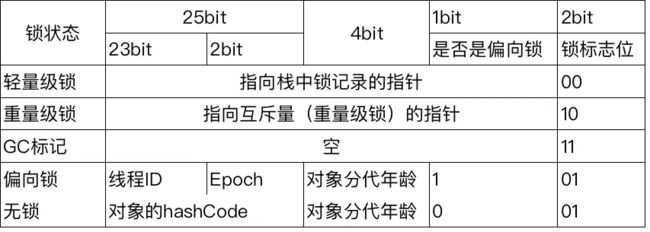
重量级锁就是sychronized的对象锁,锁标识为10,其中指针指向的是monitor对象的起始地址。
每个对象都存在着一个monitor与之关联,对象与其monitor之间的关系有存在多重实现方式,
如monitor可以与对象一起创建销毁或线程试图获取对象锁时自动生成,
但当一个monitor被某个线程持有后,它便处于锁定状态。
在java虚拟机中(hotSpot),monitor是由ObjectMonitor实现的。

ObjectMonitor中有两个队列,_WaitSet和_EntryList,用来保存ObjectWaiter列表,
每个等待锁的线程都会封装成ObjectWaiter对象,_owner指向持有ObjectMonitor对象的线程,
当多个线程同时访问同一段同步代码时,首先会进入_EntryList集合,
当线程获取到对象的monitor后进入_Owner区域并把monitor中的_owner变量设置为当前线程,
同时monitor的计数器_count加1,若先写调用wait()方法,
将释放当前持有的monitor,_owner变量恢复为null,count自减1,
同时该线程进入_waitSet集合等待被唤醒。
若当前线程执行完毕也将释放monitor,并复位变量的值,以便于其他线程获取monitor锁。
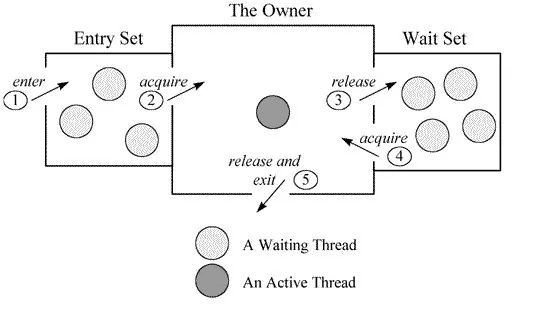
monitor对象存在每个java对象的对象头中(存储的指针的指向),
synchronized锁便是用过这种方式获取锁的,这也是为什么java的任意对象都可以作为锁的原因,
同时也是notify/notifyAll/wait方法存在object方法中的原因。
9.4 同步方法的实现原理
同步方法和静态同步方法是依赖方法修饰符ACC_SYNCHRONIZED实现,
当方法调用时,调用指令将会检查方法的ACC_SYNCHRONIZED访问标志是否被设置,
如果设置了,执行时将先获取monitor,获取成功够才能执行方法体,
方法执行完成后再释放monitor,在方法执行期间,其他任何线程都无法在获得同一个monitor对象。
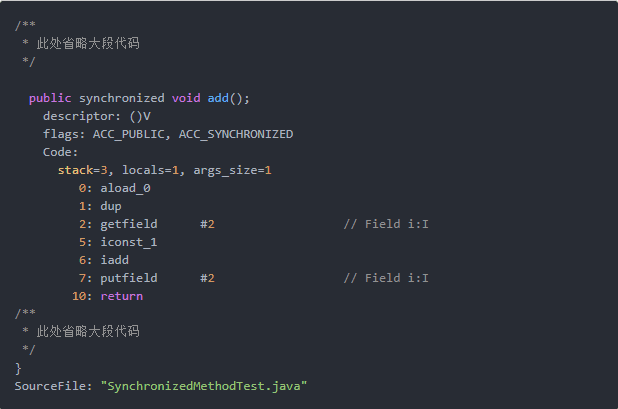
9.5 同步代码块的实现原理
同步代码块是使用monitorenter和moniterexist指令实现的,
会在同步块的区域通过监听器对象去获取锁和释放锁。
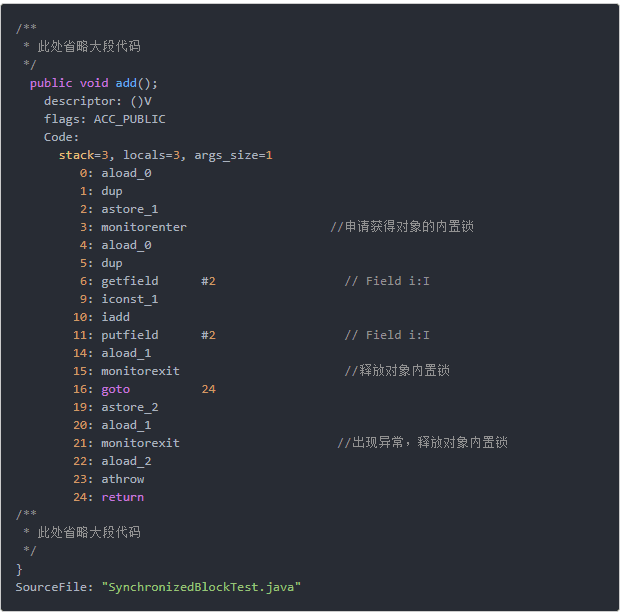
9.6 JDK1.6后的sychronized关键字底层做了哪些优化?
引入了偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术减少所操作的开销。
#锁主要存在四种状态:
无锁状态,偏向锁状态,轻量级锁状态,重量级锁状态,
锁可以升级不能降级,这种策略是为了提高获得锁和释放锁的效率。
• 一个对象里面如果有多个synchronized方法,某一个时刻内,只要一个线程去调用
其中的一个synchronized方法了,其它的线程都只能等待,换句话说,某一个时刻
内,只能有唯一一个线程去访问这些synchronized方法
• 锁的是当前对象this,被锁定后,
其它的线程都不能进入到当前对象的其它的synchronized方法
• 加个普通方法后发现和同步锁无关
• 换成两个对象后,不是同一把锁了,情况立刻变化。
• 都换成静态同步方法后,情况又变化
• 所有的非静态同步方法用的都是同一把锁——实例对象本身(this),也就是说如果一个实
例对象的非静态同步方法获取锁后,该实例对象的其他非静态同步方法必须等待获
取锁的方法释放锁后才能获取锁,可是别的实例对象的非静态同步方法因为跟该实
例对象的非静态同步方法用的是不同的锁,所以毋须等待该实例对象已获取锁的非
静态同步方法释放锁就可以获取他们自己的锁。
• 所有的静态同步方法用的也是同一把锁——类对象本身(XXX.Class),这两把锁是两个不同的对
象,所以静态同步方法与非静态同步方法之间是不会有竞态条件的。但是一旦一个
静态同步方法获取锁后,其他的静态同步方法都必须等待该方法释放锁后才能获取
锁,而不管是同一个实例对象的静态同步方法之间,还是不同的实例对象的静态同
步方法之间,只要它们同一个类的实例对象!
10.synchronized与Lock的区别与联系
10.1 区别
#a.原始构成
synchronized: 属于JVM层面的锁, JDK1.6 为 synchronized 关键字进行了很多的优化, monitorenter, monitorexit
Lock: 是API层面的锁
#b.使用方法
synchronized:
>> 不需要手动释放锁
>> 结合 wait() 和 notify()/notifyAll() 方法使用,可以实现等待/通知机制
Lock:
>> 需要手动去释放锁, 放在try..finally..块中, 否则会死锁
>> 需要借助于 Condition 接口与 newCondition() 方法。
#c.等待是否可中断
synchronized: 不可中断, 除非抛出异常或任务完成
ReentrantLock: 可中断:(设置超时时间lock.tryLock(), 或直接中断lock.lockInterruptibly())
#d. 锁是否公平
synchronized: 是非公平锁
ReentrantLock: 默认非公平锁, 支持公平和非公平锁
#e. 锁绑定多个条件
synchronized没有, 只能要么全部唤醒, 要么唤醒一个
ReentrantLock用来实现分组唤醒需要唤醒的线程们, 可以精确唤醒,
10.2 相同点
#1.两者都是可重入锁
两者都是同一个线程没进入一次,锁的计数器都自增1,
所以要等到锁的计数器下降为0时才能释放锁。
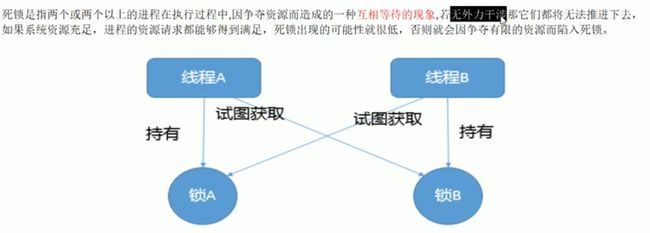
11.死锁
package com.zy.tools.undefined.concurrent.deadLock;
public class DeadLockDemo {
public static void main(String[] args) {
LockDemo demoA = new LockDemo(true);
LockDemo demoB = new LockDemo(false);
new Thread(demoA, "demoA").start();
new Thread(demoB, "demoB").start();
}
}
class LockDemo implements Runnable {
private final static Object lockA = new Object();
private final static Object lockB = new Object();
private boolean isA;
public LockDemo(boolean isA) {
this.isA = isA;
}
@Override
public void run() {
if (isA) {
methodA();
} else {
methodB();
}
}
public void methodA() {
synchronized (lockA) {
System.out.println(Thread.currentThread().getName() + "获取lockA, 尝试获得lockB");
synchronized (lockB) {
System.out.println(Thread.currentThread().getName() + "获取lockB");
}
}
}
public void methodB() {
synchronized (lockB) {
System.out.println(Thread.currentThread().getName() + "获取lockB, 尝试获得lockA");
synchronized (lockA) {
System.out.println(Thread.currentThread().getName() + "获取lockA");
}
}
}
}
# 分析思路:
1.在当前代码工程下, 执行: jps -l, 找到可疑的进程号如14060
2.执行jstack 14060, 查看是否有死锁现象
12.分布式锁
12.1 概述
12.1.1 什么是分布式
#保证最终一致性与高可用性
分布式的 CAP 理论告诉我们:
任何一个分布式系统都无法同时满足一致性(Consistency), 可用性(Availability)和分区容错性(Partition tolerance), 最多只能同时满足两项。
目前很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。
基于 CAP理论,很多系统在设计之初就要对这三者做出取舍。
在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证最终一致性。
有些场景例外(如金融场景)。
#分布式场景
此处主要指集群模式下,多个相同服务同时开启。
在许多的场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,
比如分布式事务、分布式锁等。
很多时候我们需要保证一个方法在同一时间内只能被同一个线程执行。
1) 在单机环境中,通过 Java 提供的并发 API 我们可以解决,但是在分布式环境下,复杂的多。
2) 分布式与单机情况下最大的不同在于其不是多线程而是"多进程"。
多线程由于可以共享堆内存,因此可以简单的采取内存作为标记存储位置。
而进程之间甚至可能都不在同一台物理机上,因此需要将标记存储在一个所有进程都能看到的地方。
12.1.2 什么是锁
1.在单进程的系统中,当存在多个线程可以同时改变某个变量(可变共享变量)时,
就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行消除并发修改变量。
2.而同步的本质是通过锁来实现的。
为了实现多个线程在一个时刻同一个代码块只能有一个线程可执行,
那么需要在某个地方做个标记,这个标记必须每个线程都能看到,当标记不存在时可以设置该标记,
其余后续线程发现已经有标记了则等待拥有标记的线程结束同步代码块取消标记后再去尝试设置标记。
这个标记可以理解为锁。
3.不同地方实现锁的方式也不一样,只要能满足所有线程都能看得到标记即可。
如 Java 中 synchronized 是在对象头设置标记,
Lock 接口的实现类基本上都只是某一个 volatile 修饰的 int 型变量其保证每个线程都能拥有对该 int 的可见性和原子修改,
linux 内核中也是利用互斥量或信号量等内存数据做标记。
4.除了利用内存数据做锁其实任何互斥的都能做锁(只考虑互斥情况),
如流水表中流水号与时间结合做幂等校验可以看作是一个不会释放的锁,
或者使用某个文件是否存在作为锁等。
只需要满足在对标记进行修改能保证原子性和内存可见性即可。
12.1.3 什么是分布式锁
1.当在分布式模型下,数据只有一份(或有限制), 此时需要利用锁的技术控制某一时刻修改数据的进程数。
2.与单机模式下的锁不同, 分布式锁不仅需要保证进程可见,还需要考虑进程与锁之间的网络问题。
分布式情况下之所以问题变得复杂,主要就是需要考虑到网络的延时和不可靠。
3.分布式锁还是可以将标记存在内存,只是该内存不是某个进程分配的内存而是公共内存如 Redis, Memcache。
至于利用数据库、文件等做锁与单机的实现是一样的,只要保证标记能互斥就行。
12.1.4 分布式锁的要求
1.可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
2.这把锁要是一把可重入锁(避免死锁)
3.这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
4.这把锁最好是一把公平锁(根据业务需求考虑要不要这条)
5.有高可用的获取锁和释放锁功能
6.获取锁和释放锁的性能要好
12.2 几种实现方式
12.2.1 基于数据库
https://www.jianshu.com/p/f65efc4cd860 (关于数据库锁可参考该文)
12.2.1.1 基于数据库的乐观锁
#基于表字段版本号做分布式锁
---- 为每个表设计一个版本号字段 ----
这个策略源于 mysql 的 mvcc 机制,使用这个策略其实本身没有什么问题,
唯一的问题就是对数据表侵入较大,在高并发的要求下,对数据库连接的开销也是无法忍受的。
#基本流程
当我们要从数据库中读取数据的时候,同时把这个version字段也读出来,
如果要对读出来的数据进行更新后写回数据库,则需要将version加1,
同时将新的数据与新的version更新到数据表中,
且必须在更新的时候同时检查目前数据库里version值是不是之前的那个version,
如果是,则正常更新。
如果不是,则更新失败,说明在这个过程中有其它的进程去更新过数据了。
#具体demo
1.设计tb_test表有id, money, version三个字段
2.更新时:
1) 先读tb_test表的数据, 得到 id=id1, version=v1
select id, name, money from tb_test
2) 每次更新task表中的value字段时, 为了防止发生冲突, 需要这样操作
update tb_test set money=newMoney,version=v1+1 where id=id1 and version=v1
成功, 则成功, 失败则表明失败.
#缺点
1.这种操作方式,使原本一次的update操作,必须变为2次操作:
select版本号一次;update一次。增加了数据库操作的次数。
2.如果业务场景中的一次业务流程中,多个资源都需要用保证数据一致性,
那么如果全部使用基于数据库资源表的乐观锁,就要让每个资源都有一张资源表,
这个在实际使用场景中肯定是无法满足的。
而且这些都基于数据库操作,在高并发的要求下,对数据库连接的开销一定是无法忍受的。
3.乐观锁机制往往基于系统中的数据存储逻辑,因此可能会造成脏数据被更新到数据库中。
在系统设计阶段,我们应该充分考虑到这些情况出现的可能性,并进行相应调整,
如将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据更新途径,
而不是将数据库表直接对外公开。
12.2.1.2 基于数据库的悲观锁
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁
(注意:
InnoDB 引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。
这里我们希望使用行级锁,就要给要执行的方法字段名添加索引,
值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。
重载方法的话建议把参数类型也加上。)
当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排他锁的线程即可获得分布式锁,当获取到锁之后,
可以执行方法的业务逻辑,执行完方法之后,通过connection.commit()操作来释放锁。
#具体demo
/**
* 超时获取锁
* @param lockID
* @param timeOuts
* @return
* @throws InterruptedException
*/
public boolean acquireByUpdate(String lockID, long timeOuts) throws InterruptedException, SQLException {
String sql = "SELECT id from test_lock where id = ? for UPDATE ";
long futureTime = System.currentTimeMillis() + timeOuts;
long ranmain = timeOuts;
long timerange = 500;
connection.setAutoCommit(false);
while (true) {
CountDownLatch latch = new CountDownLatch(1);
try {
PreparedStatement statement = connection.prepareStatement(sql);
statement.setString(1, lockID);
statement.setInt(2, 1);
statement.setLong(1, System.currentTimeMillis());
boolean ifsucess = statement.execute();//如果成功,那么就是获取到了锁
if (ifsucess)
return true;
} catch (SQLException e) {
e.printStackTrace();
}
latch.await(timerange, TimeUnit.MILLISECONDS);
ranmain = futureTime - System.currentTimeMillis();
if (ranmain <= 0)
break;
if (ranmain < timerange) {
timerange = ranmain;
}
continue;
}
return false;
}
/**
* 释放锁
* @param lockID
* @return
* @throws SQLException
*/
public void unlockforUpdtate(String lockID) throws SQLException {
connection.commit();
}
12.2.2 基于Redis
12.2.2.1 基于 redisson 框架(ReLock算法)做分布式锁
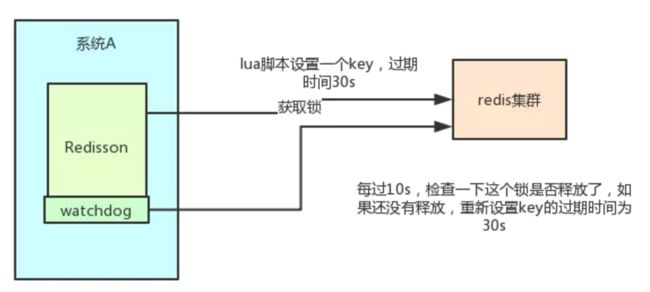
redisson 是 redis 官方的分布式锁组件。
失效时间设置多长时间为好?
这个问题在 redisson 的做法是:
每获得一个锁时,只设置一个很短的超时时间,同时起一个线程在每次快要到超时时间时去刷新锁的超时时间。
在释放锁的同时结束这个线程。
#Redisson的一些特点
1.redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
2.redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办?
>> redisson中有一个watchdog的概念,翻译过来就是看门狗,
它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s
>> 这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
3.redisson的“看门狗”逻辑保证了没有死锁发生。
如果机器宕机了,看门狗也就没了。
此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁。
package com.zy.redis5.single;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
@SpringBootTest
@RunWith(SpringRunner.class)
public class RedisSingleDistributedLockTest {
// 这里使用的 redis 单机版, 集群版的用法类似
private static RedissonClient redissonClient;
static {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.0.199:26379");
redissonClient = Redisson.create(config);
}
private static final String REDISSON_LOCK_PREFIX = "lock_";
private static final ExecutorService executor = Executors.newCachedThreadPool();
private static final int num = 20;
private static final CountDownLatch countDownLatch = new CountDownLatch(num);
/**
* 这里模拟库存数量, 假设是 100
*/
private int goodsAmount = 100;
@Test
public void fn01() throws InterruptedException {
for (int i = 0; i < num; i++) {
// executor.submit(this::minusGoods); // 不加锁扣减库存
executor.submit(this::minusGoodsByRedissonLock); // 加分布式锁扣减库存
}
countDownLatch.await();
System.out.println("goodsAmount ---------- " + goodsAmount);
}
/**
* 加分布式锁扣减库存
*/
private void minusGoodsByRedissonLock() {
RLock lock = redissonClient.getLock(REDISSON_LOCK_PREFIX);
try {
lock.lock(30L, TimeUnit.SECONDS);
goodsAmount -= 3;
} finally {
countDownLatch.countDown();
lock.unlock();
}
}
/**
* 不加锁扣减库存
*/
private void minusGoods() {
try {
goodsAmount -= 3;
} finally {
countDownLatch.countDown();
}
}
}
https://github.com/redisson/redisson/wiki/Redisson%E9%A1%B9%E7%9B%AE%E4%BB%8B%E7%BB%8D (redisson官网)
https://www.cnblogs.com/linjiqin/p/8003838.html (jedis 实现分布式锁采坑指南)
Martin Kleppmann 与 antirez 关于 RedLock 算法的互怼
http://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
http://antirez.com/news/101
12.2.2.2 基于 jedis + Lua 做分布式锁 (有问题)
redis的一些基本命令
#SETNX key value
当key不存在时, 设置key-value, 否则, 不做任何操作, SETNX 即 SET if Not eXists
#expire KEY seconds
设置key的过期时间, 如果key已过期, 将会被自动删除
分布式锁探讨
1.基本锁
#原理:
执行 redis 的 SETNX 命令即可.注意: 解锁时要同时验证key和value.
#缺点:
如果获取锁后的进程在没有执行完就挂了, 则锁永远不会释放, 导致死锁
2.改进一下锁
#原理:
执行 redis 的 SETNX 命令后, 设置 expire, 保证超时后也能释放锁
#缺点
SETNX 和 expire 不是一个原子操作, 可能执行完 SETNX, 线程就挂了, 还是会死锁
3.再改进一下锁
#原理:
利用 Lua 脚本, 将 SETNX 和 expire 变成一个原子操作
#缺点:
如果某个线程执行的太慢,导致在有效期内还没有执行完,
那么因为设置了锁超时自动释放机制,此时锁被自动释放,另一个线程进来拿到锁开始执行代码,
就会出现同一时间有两个线程在执行互斥资源代码,可能出现数据不一致。
#如何解决?
设置合理的超时时间 + 监控代码执行情况
自动续期,起一个定时任务,周期性扫描超距离超时间还剩多少时仍没有执行完的线程,自动延长时间。
>>>> 此处可参考上文的 Redisson 的实现分布式锁的原理了.
#终极问题:
单点故障咋办? (搭建 redis 集群)
集群中master挂了, 锁数据尚未同步到 slave 咋办?
https://www.cnblogs.com/williamjie/p/9395659.html (适合单机版 Redis)
12.2.2.3 基于Lettuce实现分布式锁(redis高级客户端)
12.2.3 基于Zookeeper实现分布式锁
#### zookeeper 锁相关基础知识
>> zk 一般由多个节点构成(单数),采用 zab 一致性协议。
因此可以将 zk 看成一个单点结构,对其修改数据其内部自动将所有节点数据进行修改而后才提供查询服务。
>> zk 的数据以目录树的形式,每个目录称为 znode,
znode 中可存储数据(一般不超过 1M),还可以在其中增加子节点。
>> 子节点有三种类型。
序列化节点,每在该节点下增加一个节点自动给该节点的名称上自增。
临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除。
普通节点。
>> Watch 机制,client 可以监控每个节点的变化,当产生变化会给 client 产生一个事件。
#大致思想
每个客户端对某个方法加锁时,在 Zookeeper 上与该方法对应的指定节点的目录下,生成一个唯一的临时有序节点。
判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。
当释放锁的时候,只需将这个临时节点删除即可。
同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
#### zk 基本锁
>> 原理:利用临时节点与 watch 机制。
每个锁占用一个普通节点 /lock,当需要获取锁时在 /lock 目录下创建一个临时节点,
创建成功则表示获取锁成功,失败则 watch/lock 节点,有删除操作后再去争锁。
临时节点好处在于当进程挂掉后能自动上锁的节点自动删除即取消锁。
>> 缺点:所有取锁失败的进程都监听父节点,很容易发生羊群效应,
即当释放锁后所有等待进程一起来创建节点,并发量很大。
#### zk 锁优化
>> 原理:上锁改为创建临时有序节点,每个上锁的节点均能创建节点成功,只是其序号不同。
只有序号最小的可以拥有锁,如果这个节点序号不是最小的则 watch 序号比本身小的前一个节点 (公平锁)。
>> 步骤:
1.在 /lock 节点下创建一个有序临时节点 (EPHEMERAL_SEQUENTIAL)。
2.判断创建的节点序号是否最小,如果是最小则获取锁成功。
不是则取锁失败,然后 watch 序号比本身小的前一个节点。
3.当取锁失败,设置 watch 后则等待 watch 事件到来后,再次判断是否序号最小。
4.取锁成功则执行代码,最后释放锁(删除该节点)。
#优缺点
>> 优点:
有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
>> 缺点:
性能上可能并没有缓存服务那么高,因为每次在创建锁和释放锁的过程中,
都要动态创建、销毁临时节点来实现锁功能。
ZK 中创建和删除节点只能通过 Leader 服务器来执行,然后将数据同步到所有的 Follower 机器上。
12.2.3.1 Zookeeper 如何实现分布式锁
排他锁
排他锁,又称写锁或独占锁。
如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取或更新操作,
其他任务事务都不能对这个数据对象进行任何操作,直到T1释放了排他锁。
排他锁核心是保证当前有且仅有一个事务获得锁,并且锁释放之后,
所有正在等待获取锁的事务都能够被通知到。
Zookeeper 的强一致性特性,能够很好地保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,
即Zookeeper将会保证客户端无法重复创建一个已经存在的数据节点。
可以利用Zookeeper这个特性,实现排他锁。
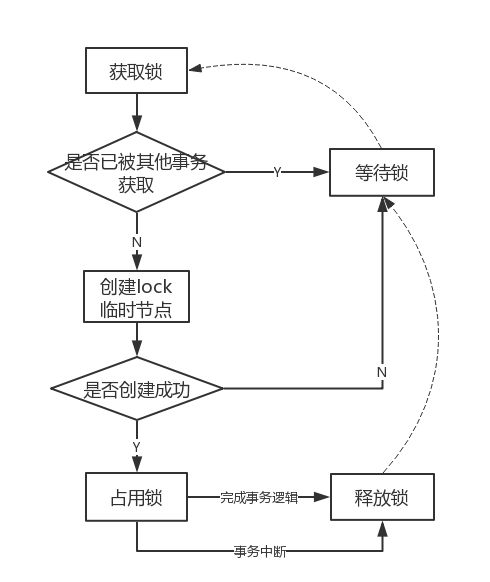
#基本步骤
1.定义锁:
通过Zookeeper上的数据节点来表示一个锁
2.获取锁:
客户端通过调用 create 方法创建表示锁的临时节点,可以认为创建成功的客户端获得了锁,
同时可以让没有获得锁的节点在该节点上注册Watcher监听,以便实时监听到lock节点的变更情况。
3.释放锁:以下两种情况都可以让锁释放
>> 当前获得锁的客户端发生宕机或异常,那么Zookeeper上这个临时节点就会被删除
>> 正常执行完业务逻辑,客户端主动删除自己创建的临时节点
共享锁
共享锁,又称读锁。
如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,
其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都被释放。
共享锁与排他锁的区别在于,
加了排他锁之后,数据对象只对当前事务可见,
而加了共享锁之后,数据对象对所有事务都可见。
#基本步骤
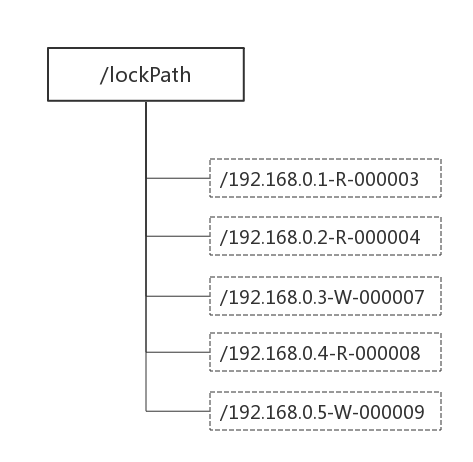
1.定义锁:
通过Zookeeper上的数据节点来表示一个锁,是一个类似于
/lockpath/[hostname]-请求类型-序号 的临时顺序节点。
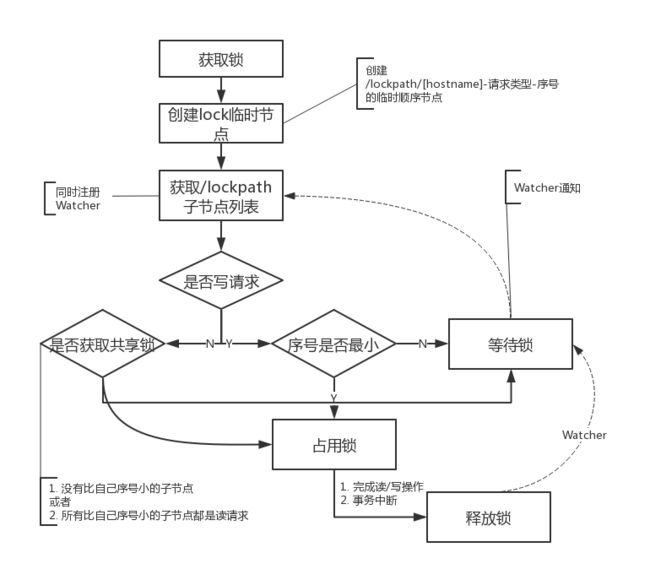
2.获取锁:
客户端通过调用 create 方法创建表示锁的临时顺序节点,
如果是读请求,则创建 /lockpath/[hostname]-R-序号 节点,
如果是写请求则创建 /lockpath/[hostname]-W-序号 节点。
>> 判断读写顺序:大概分为4个步骤
1) 创建完节点后,获取 /lockpath 节点下的所有子节点,并对该节点注册子节点变更的Watcher监听
2) 确定自己的节点序号在所有子节点中的顺序
3.1) 对于读请求:
>> 如果没有比自己序号更小的子节点,或者比自己序号小的子节点都是读请求,
那么表明自己已经成功获取到了共享锁,同时开始执行读取逻辑
>> 如果有比自己序号小的子节点有写请求,那么等待
3.2) 对于写请求,如果自己不是序号最小的节点,那么等待
4) 接收到Watcher通知后,重复步骤1)
3.释放锁:与排他锁逻辑一致
>> 当前获得锁的客户端发生宕机或异常,那么Zookeeper上这个临时节点就会被删除
>> 正常执行完业务逻辑,客户端主动删除自己创建的临时节点
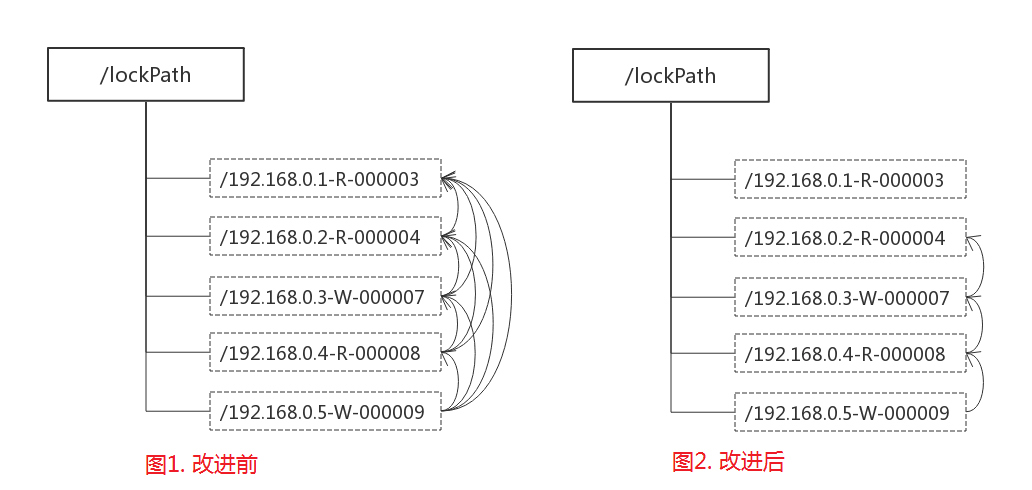
羊群效应
在实现共享锁的 "判断读写顺序" 的第1个步骤是:
创建完节点后,获取 /lockpath 节点下的所有子节点,并对该节点注册子节点变更的Watcher监听。
这样的话,任何一次客户端移除共享锁之后,Zookeeper将会发送子节点变更的Watcher通知给所有机器,
系统中将有大量的 "Watcher通知" 和 "子节点列表获取" 这个操作重复执行,
然后所有节点再判断自己是否是序号最小的节点(写请求)或者判断比自己序号小的子节点是否都是读请求(读请求),
从而继续等待下一次通知。
然而,这些重复操作很多都是 "无用的",
实际上每个锁竞争者只需要关注序号比自己小的那个节点是否存在即可。
当集群规模比较大时,这些 "无用的" 操作不仅会对Zookeeper造成巨大的性能影响和网络冲击,
更为严重的是,如果同一时间有多个客户端释放了共享锁,
Zookeeper服务器就会在短时间内向其余客户端发送大量的事件通知--
这就是所谓的 "羊群效应"。
共享锁: 改进后的分布式锁实现
1.客户端调用 create 方法创建一个类似于 /lockpath/[hostname]-请求类型-序号 的临时顺序节点
2.客户端调用 getChildren 方法获取所有已经创建的子节点列表(这里不注册任何Watcher)
3.如果无法获取任何共享锁,那么调用 exist 来对比自己小的那个节点注册Watcher
>> 读请求:向比自己序号小的最后一个写请求节点注册Watcher监听
>> 写请求:向比自己序号小的最后一个节点注册Watcher监听
4.等待Watcher监听,继续进入步骤2
12.2.3.2 基于Curator客户端实现分布式锁
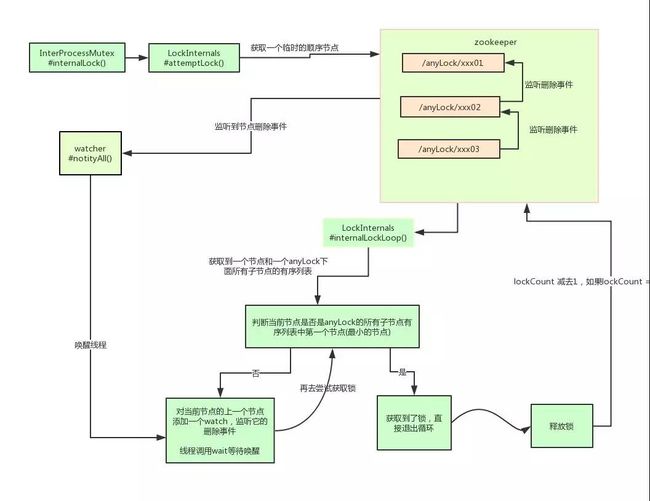
#概述
Apache Curator是一个Zookeeper的开源客户端,它提供了Zookeeper各种应用场景
(Recipe,如共享锁服务、master选举、分布式计数器等)的抽象封装等。
#分布式锁
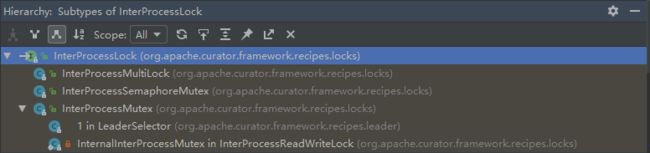
Curator提供的跟分布式锁相关的类有5种,分别是:
>> 1.Shared Reentrant Lock 可重入锁: 可重入锁重入几次需要释放几次
----> InterProcessMutex
>> 2.Shared Lock 共享不可重入锁: 不可重入的锁可能在一些情况导致死锁
----> InterProcessSemaphoreMutex
>> 3.Shared Reentrant Read Write Lock 可重入读写锁
----> InterProcessReadWriteLock & InterProcessMutex
>> 4.Shared Semaphore 信号量 ---->
----> InterProcessSemaphoreV2 - 信号量实现类
----> Lease - 租约(单个信号)
----> SharedCountReader - 计数器,用于计算最大租约数量
>> 5.Multi Shared Lock 多锁
----> InterProcessMultiLock - 对所对象实现类
----> InterProcessLock - 分布式锁接口类
前4种锁都是公平锁...
#关于错误处理
强烈推荐使用ConnectionStateListener处理连接状态的改变。
当连接LOST时你不再拥有锁。
package com.zy;
import com.zy.mapper.GoodsMapper;
import com.zy.zk.CuratorZkClient;
import com.zy.zk.URI;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.framework.recipes.locks.InterProcessReadWriteLock;
import org.apache.curator.framework.recipes.locks.InterProcessSemaphoreMutex;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
@RunWith(SpringRunner.class)
@SpringBootTest
@MapperScan("com.zy.mapper")
public class SpringBootDemo01ApplicationTests {
@Autowired
private GoodsMapper goodsMapper;
private static final Integer goodsId = 1;
private static final Integer countMinus = 2;
private static final ExecutorService executorService = Executors.newCachedThreadPool();
private static final String lockPath = "/zkLock";
private static final int num = 4;
private static final CountDownLatch countDownLatch = new CountDownLatch(num);
/**
* 减库存: 这里最终 库存数 会 < 0
*
* @throws InterruptedException
*/
@Test
public void fn01() throws InterruptedException {
// 假定 goodsId=1 的商品, 库存数量是 16, 执行完该未加锁方法后, 库存可能小于 0
// 当然, 这里是模拟集群部署(即多台服务器时)的并发场景
// 此处由于是在本机模拟的(一台机器上, 故未加单机下的JVM同步锁, 如 synchronized, Lock 等)
// 这里模拟 10 台 业务服务器 同时发送减库存的请求
// 每次扣减 2 件商品, 因此数据库中设置商品数量 < 8, 这里设为 5, 观察执行完毕后会不会 < 0
for (int i = 0; i < num; i++) {
executorService.submit(() -> {
// 查库存
Integer count = goodsMapper.getCountByGoodsId(goodsId);
if (count - countMinus >= 0) {
// 减库存
goodsMapper.updateGoodsCountByGoodsId(goodsId, countMinus);
}
});
}
TimeUnit.SECONDS.sleep(1);
}
/**
* 减库存: 这里加分布式锁后, 进程(进程!进程!)之间也是安全的
* 即同一时刻, 所有 JVM 中, 最多只有一个线程可执行减库存操作, 库存数不会 < 0
*
* @throws InterruptedException 控制台打印结果显示: InterProcessMutex 是可重入的
* client#2第一次已获取互斥锁
* client#2第二次获取互斥锁
* client#2第二次互斥锁释放
* client#2第一次互斥锁释放org.apache.curator.framework.recipes.locks.InterProcessMutex@18147eac
* client#1第一次已获取互斥锁
* client#1第二次获取互斥锁
* client#1第二次互斥锁释放
* client#1第一次互斥锁释放org.apache.curator.framework.recipes.locks.InterProcessMutex@5744678d
* client#3第一次已获取互斥锁
* client#3第二次获取互斥锁
* client#3第二次互斥锁释放
* client#3第一次互斥锁释放org.apache.curator.framework.recipes.locks.InterProcessMutex@584df218
* client#0第一次已获取互斥锁
* client#0第二次获取互斥锁
* client#0第二次互斥锁释放
* client#0第一次互斥锁释放org.apache.curator.framework.recipes.locks.InterProcessMutex@410177b3
*/
@Test
public void fn02() throws InterruptedException {
// 这里模拟 提供分布式锁服务的 zk 集群, 下述的 10 台 业务服务器连接的同样的 zk 集群
CuratorZkClient client = new CuratorZkClient(new URI("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", null, null));
// 这里模拟 4 台 业务服务器 同时发送减库存的请求
// 每次扣减 2 件商品, 因此数据库中设置商品数量 < 8, 这里设为 5, 观察执行完毕后会不会 < 0
for (int i = 0; i < num; i++) {
final InterProcessMutex lock = new InterProcessMutex(client.getClient(), lockPath);
String clientNo = "client#" + i;
executorService.submit(() -> {
try {
// 加锁
boolean acquire = lock.acquire(10, TimeUnit.SECONDS);
if (!acquire) {
System.out.println(clientNo + "第一次无法获取互斥锁");
return;
}
System.out.println(clientNo + "第一次已获取互斥锁");
// 先查库存
Integer count = goodsMapper.getCountByGoodsId(goodsId);
if (count - countMinus >= 0) {
// 再减库存
goodsMapper.updateGoodsCountByGoodsId(goodsId, countMinus);
}
boolean againAcquire = lock.acquire(300, TimeUnit.MICROSECONDS);
if (!againAcquire) {
System.out.println(clientNo + "第二次无法获取互斥锁");
return;
}
System.out.println(clientNo + "第二次获取互斥锁");
lock.release();
System.out.println(clientNo + "第二次互斥锁释放");
} catch (Exception e) {
System.out.println(clientNo + e.getMessage());
} finally {
countDownLatch.countDown();
try {
lock.release();
System.out.println(clientNo + "第一次互斥锁释放" + lock);
} catch (Exception e) {
System.out.println(clientNo + e.getMessage() + "---");
}
}
});
}
countDownLatch.await();
}
/**
* 减库存: 这里加分布式锁后, 进程(进程!进程!)之间也是安全的
* 即同一时刻, 所有 JVM 中, 最多只有一个线程可执行减库存操作, 库存数不会 < 0
*
* @throws InterruptedException 控制台打印结果显示: InterProcessSemaphoreMutex 是不可重入的
* client#2第一次已获取互斥锁
* client#2第二次无法获取互斥锁
* client#2第一次互斥锁释放
* client#1第一次已获取互斥锁
* client#1第二次无法获取互斥锁
* client#1第一次互斥锁释放
* client#3第一次已获取互斥锁
* client#3第二次无法获取互斥锁
* client#3第一次互斥锁释放
* client#0第一次无法获取互斥锁
* client#0Not acquired---
*/
@Test
public void fn03() throws InterruptedException {
// 这里模拟 提供分布式锁服务的 zk 集群, 下述的 10 台 业务服务器连接的同样的 zk 集群
CuratorZkClient client = new CuratorZkClient(new URI("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", null, null));
// 这里模拟 4 台 业务服务器 同时发送减库存的请求
// 每次扣减 2 件商品, 因此数据库中设置商品数量 < 8, 这里设为 5, 观察执行完毕后会不会 < 0
for (int i = 0; i < 4; i++) {
final InterProcessSemaphoreMutex lock = new InterProcessSemaphoreMutex(client.getClient(), lockPath);
String clientNo = "client#" + i;
executorService.submit(() -> {
try {
// 加锁
boolean acquire = lock.acquire(2, TimeUnit.SECONDS);
if (!acquire) {
System.out.println(clientNo + "第一次无法获取互斥锁");
return;
}
System.out.println(clientNo + "第一次已获取互斥锁");
// 先查库存
Integer count = goodsMapper.getCountByGoodsId(goodsId);
if (count - countMinus >= 0) {
// 再减库存
goodsMapper.updateGoodsCountByGoodsId(goodsId, countMinus);
}
boolean againAcquire = lock.acquire(300, TimeUnit.MICROSECONDS);
if (!againAcquire) {
System.out.println(clientNo + "第二次无法获取互斥锁");
return;
}
System.out.println(clientNo + "第二次获取互斥锁");
lock.release();
System.out.println(clientNo + "第二次互斥锁释放");
} catch (Exception e) {
System.out.println(clientNo + e.getMessage());
} finally {
countDownLatch.countDown();
try {
lock.release();
System.out.println(clientNo + "第一次互斥锁释放");
} catch (Exception e) {
System.out.println(clientNo + e.getMessage() + "---");
}
}
});
}
countDownLatch.await();
}
/**
* 减库存: 这里加分布式锁后, 进程(进程!进程!)之间也是安全的
* 即同一时刻, 所有 JVM 中, 最多只有一个线程可执行减库存操作, 库存数不会 < 0
*
* @throws InterruptedException 控制台打印结果显示如下: (InterProcessReadWriteLock 读写锁, 一波请求, 只有一个能获取写锁)
* client#0已获取写锁
* client#1无法获取写锁
* client#1You do not own the lock: /zkLock-----
* client#2无法获取写锁
* client#2You do not own the lock: /zkLock-----
* client#3无法获取写锁
* client#3You do not own the lock: /zkLock-----
* client#0写锁释放完毕org.apache.curator.framework.recipes.locks.InterProcessReadWriteLock$InternalInterProcessMutex@1c5fbcfe
*/
@Test
public void fn04() throws InterruptedException {
// 这里模拟 提供分布式锁服务的 zk 集群, 下述的 10 台 业务服务器连接的同样的 zk 集群
CuratorZkClient client = new CuratorZkClient(new URI("127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183", null, null));
// 这里模拟 4 台 业务服务器 同时发送减库存的请求
// 每次扣减 2 件商品, 因此数据库中设置商品数量 < 8, 这里设为 5, 观察执行完毕后会不会 < 0
for (int i = 0; i < 4; i++) {
String clientNo = "client#" + i;
final InterProcessReadWriteLock lock = new InterProcessReadWriteLock(client.getClient(), lockPath);
final InterProcessMutex writeLock = lock.writeLock();
final InterProcessMutex readLock = lock.readLock();
executorService.submit(() -> {
try {
// 加锁: 要先加写锁, 再加读锁
boolean writeAcquire = writeLock.acquire(100, TimeUnit.MICROSECONDS);
if (!writeAcquire) {
System.out.println(clientNo + "无法获取写锁");
return;
}
System.out.println(clientNo + "已获取写锁");
/*boolean readAcquire = readLock.acquire(100, TimeUnit.MICROSECONDS);
if (!readAcquire) {
System.out.println(clientNo + "无法获取读锁");
return;
}
System.out.println(clientNo + "已获取读锁");*/
// 先查库存
Integer count = goodsMapper.getCountByGoodsId(goodsId);
if (count - countMinus >= 0) {
// 再减库存
goodsMapper.updateGoodsCountByGoodsId(goodsId, countMinus);
}
} catch (Exception e) {
System.out.println(clientNo + e.getMessage());
} finally {
countDownLatch.countDown();
try {
/*readLock.release();
System.out.println(clientNo + "读锁释放完毕" + readLock);*/
writeLock.release();
System.out.println(clientNo + "写锁释放完毕" + writeLock);
} catch (Exception e) {
System.out.println(clientNo + e.getMessage() + "-----");
}
}
});
}
countDownLatch.await();
}
}
参考链接
https://www.cnblogs.com/waterystone/p/4920797.html (AQS)
https://blog.csdn.net/qq_29519041/article/details/86583945 (可重入锁)
https://www.cnblogs.com/incognitor/p/9894604.html (可重入锁)
https://mp.weixin.qq.com/s/MnbXpKuJWheY5SmnHI8-Ag (分布式锁--非常详细)
http://www.54tianzhisheng.cn/2018/04/24/Distributed_lock/ (分布式锁--较全)
https://blog.csdn.net/lovexiaotaozi/article/details/83819916 (DB实现分布式锁)
https://www.jianshu.com/p/a974eec257e6 (Curator实现分布式锁--已参考)
https://www.jianshu.com/p/d12bf3f4017c (Curator分布式锁源码--已参考)
https://mp.weixin.qq.com/s/gUDMP5FVPfS7Id4IyHp02A (分布式锁)
https://segmentfault.com/a/1190000015808032?utm_source=tag-newest (juc锁综合)
https://segmentfault.com/a/1190000007094429 (CLH Lock)
http://www.cs.tau.ac.il/~shanir/nir-pubs-web/Papers/CLH.pdf (CLH Lock)