1、
jieba.cut(line, cut_all=False) ——精准切割
jieba.cut(line, cut_all=True) ——全切割
2、
去除标点、数字、英/中文符号的文本清洗,正则里[……]超好用!随便连着填什么都可以。
if line != '':
line = line.strip()
pun_num = string.punctuation + string.digits
intab = pun_num
outtab = " "*len(pun_num)
# 去除所有标点和数字
trantab = str.maketrans(intab, outtab)
line = line.translate(trantab)
# 去除文本中的英文和数字
line = re.sub("[a-zA-Z0-9]", "", line)
# 去除文本中的中文符号和英文符号
line = re.sub("[\s+\.\!\/_,$%^*(+\"\';:“”.]+|[+——!==°【】,÷。??、~@#¥%……&*()]+", "", line)
3、TF-IDF

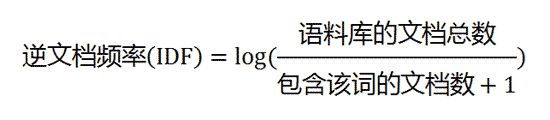
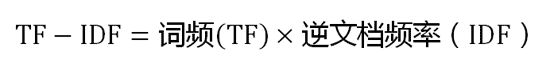
4、关键词提取
【jieba的每个词的idf值该是自己算好记录在一个文件里的,每次直接计算某个词的tf,再直接去它自带的idf词典里找对应的idf值,最后计算tf*idf并返回】
-基于TF-IDF算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
–sentence 为待提取的文本
–topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
–withWeight 为是否一并返回关键词权重值,默认值为 False
–allowPOS 仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法:jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
-基于TextRank算法的关键词提取
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’))
直接使用,接口相同,注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义 TextRank 实例
–基本思想:
1,将待抽取关键词的文本进行分词
2,以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
3,计算图中节点的PageRank,注意是无向带权图
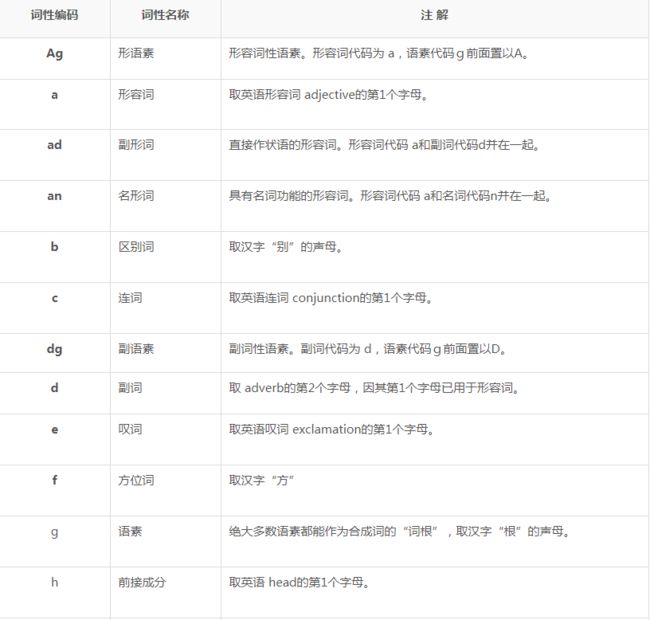
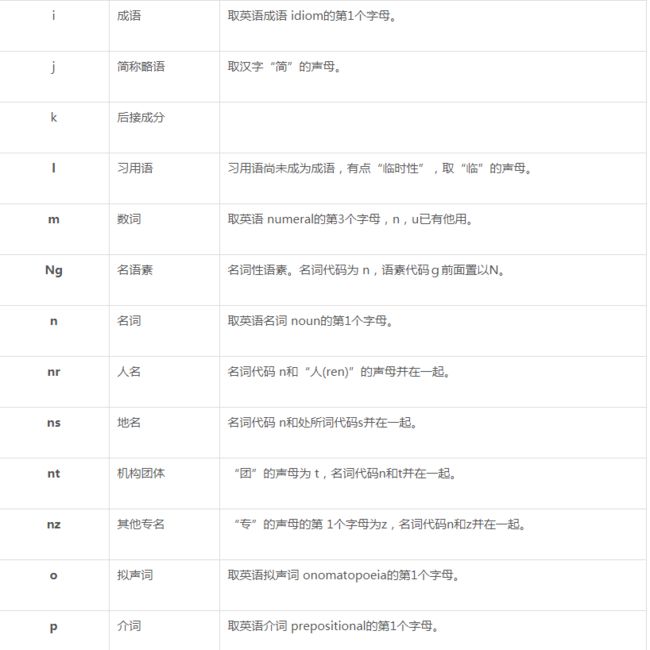
5、jieba词性
1). 名词 (1个一类,7个二类,5个三类)
名词分为以下子类:
n 名词
nr 人名
nr1 汉语姓氏
nr2 汉语名字
nrj 日语人名
nrf 音译人名
ns 地名
nsf 音译地名
nt 机构团体名
nz 其它专名
nl 名词性惯用语
ng 名词性语素
2). 时间词(1个一类,1个二类)
t 时间词
tg 时间词性语素
3). 处所词(1个一类)
s 处所词
4). 方位词(1个一类)
f 方位词
5). 动词(1个一类,9个二类)
v 动词
vd 副动词
vn 名动词
vshi 动词“是”
vyou 动词“有”
vf 趋向动词
vx 形式动词
vi 不及物动词(内动词)
vl 动词性惯用语
vg 动词性语素
6). 形容词(1个一类,4个二类)
a 形容词
ad 副形词
an 名形词
ag 形容词性语素
al 形容词性惯用语
7). 区别词(1个一类,2个二类)
b 区别词
bl 区别词性惯用语
8). 状态词(1个一类)
z 状态词
9). 代词(1个一类,4个二类,6个三类)
r 代词
rr 人称代词
rz 指示代词
rzt 时间指示代词
rzs 处所指示代词
rzv 谓词性指示代词
ry 疑问代词
ryt 时间疑问代词
rys 处所疑问代词
ryv 谓词性疑问代词
rg 代词性语素
10). 数词(1个一类,1个二类)
m 数词
mq 数量词
11). 量词(1个一类,2个二类)
q 量词
qv 动量词
qt 时量词
12). 副词(1个一类)
d 副词
13). 介词(1个一类,2个二类)
p 介词
pba 介词“把”
pbei 介词“被”
14). 连词(1个一类,1个二类)
c 连词
cc 并列连词
15). 助词(1个一类,15个二类)
u 助词
uzhe 着
ule 了 喽
uguo 过
ude1 的 底
ude2 地
ude3 得
usuo 所
udeng 等 等等 云云
uyy 一样 一般 似的 般
udh 的话
uls 来讲 来说 而言 说来
uzhi 之
ulian 连 (“连小学生都会”)
16). 叹词(1个一类)
e 叹词
17). 语气词(1个一类)
y 语气词(delete yg)
18). 拟声词(1个一类)
o 拟声词
19). 前缀(1个一类)
h 前缀
20). 后缀(1个一类)
k 后缀
21). 字符串(1个一类,2个二类)
x 字符串
xx 非语素字
xu 网址URL
22). 标点符号(1个一类,16个二类)
w 标点符号
wkz 左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { <
wky 右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { >
wyz 左引号,全角:“ ‘ 『
wyy 右引号,全角:” ’ 』
wj 句号,全角:。
ww 问号,全角:? 半角:?
wt 叹号,全角:! 半角:!
wd 逗号,全角:, 半角:,
wf 分号,全角:; 半角: ;
wn 顿号,全角:、
wm 冒号,全角:: 半角: :
ws 省略号,全角:…… …
wp 破折号,全角:—— -- ——- 半角:--- ----
wb 百分号千分号,全角:% ‰ 半角:%
wh 单位符号,全角:¥ $ £ ° ℃ 半角:$

6、正则
from wzq -- 去掉汉字和英文字母之外的所有字符, 并合并多余空格
def deal(content):
content = repr(content)[1:-1]
pattern = re.compile(r'\<[\s\S]*?\>')
content = pattern.sub('', content)
content = re.sub(r'u200b|u2002|u300b|u3000|quot|&rdquo|&ldquo', ' ', content)
pattern = re.compile(r'[^\u4e00-\u9fa5a-zA-Z]') # 除了汉字和英文字母之外的所有字符
result = re.sub(' +', ' ', re.sub(pattern,' ',content)) # 合并空格
return result
7、正则提取单引号内的内容
string = '13~26度,多云,中度雾霾。;老北京的古老风俗不计其数,其中的民间行业活动有一番风味,说说老北京七十二行,吹糖人儿、耍蝈蝈·····现如今还流传与大街小巷,可大部分却巳被遗忘,甚至有人闻所未闻。现在我们就一起到那古色古香的胡同里去感受一下老北京当年的行行业业。;--珊姐谈天下 早安! 北京·华人一品大厦', '中雨过后还雾霾,机动车真牛逼 北京 ', '赵先生家装修完迟迟不敢入住经朋友推荐找到我们。新装污染记得先做下甲醛治理,为自己和家人缔造一个安全健康的居住环境!北京东城~西营房9号院儿童方案治理中#绿色亿家除甲醛# #除甲醛办法# ', '赵先生家装修完迟迟不敢入住经朋友推荐找到我们。新装污染记得先做下甲醛治理,为自己和家人缔造一个安全健康的居住环境!北京东城~西营房9号院儿童方案治理中#绿色亿家除甲醛# #除甲醛办法# ', '没有昨天的雾霾,就没有今天的晴空万里,没有昨日的勤奋和拼搏,就没有今天的成功,无数的成功人向我们昭示,没有昨天的破茧而出,就没有今天自由飞舞的快乐,艰苦、勤奋、哪怕是煎熬都是憧憬未来的起步,不要抱怨现在苦闷生活,春天来了,夏天还会止步吗! 北京·雍和宫(商圈) '
# 非贪婪匹配,匹配到一个即返回
pattern1 = re.compile(r'\'(.*?)\'')
match = pattern1.match(sum_weibos)
if match:
print(match.group()) # 输出:'13~26度,多云,中度雾霾。;老北京的古老风俗不计其数,其中的民间行业活动有一番风味,说说老北京七十二行,吹糖人儿、耍蝈蝈·····现如今还流传与大街小巷,可大部分却巳被遗忘,甚至有人闻所未闻。现在我们就一起到那古色古香的胡同里去感受一下老北京当年的行行业业。;--珊姐谈天下 早安! 北京·华人一品大厦'
# 循环查找, 法2:
pattern3 = re.compile(r'\'(.*?)\'')
match = pattern3.finditer(sum_weibos)
for i in match:
print("$$$", i.group(), '\n')
# 输出:
$$$ '13~26度,多云,中度雾霾。;老北京的古老风俗不计其数,其中的民间行业活动有一番风味,说说老北京七十二行,吹糖人儿、耍蝈蝈·····现如今还流传与大街小巷,可大部分却巳被遗忘,甚至有人闻所未闻。现在我们就一起到那古色古香的胡同里去感受一下老北京当年的行行业业。;--珊姐谈天下 早安! 北京·华人一品大厦'
$$$ '中雨过后还雾霾,机动车真牛逼 北京 '
$$$ '赵先生家装修完迟迟不敢入住经朋友推荐找到我们。新装污染记得先做下甲醛治理,为自己和家人缔造一个安全健康的居住环境!北京东城~西营房9号院儿童方案治理中#绿色亿家除甲醛# #除甲醛办法# '
$$$ '赵先生家装修完迟迟不敢入住经朋友推荐找到我们。新装污染记得先做下甲醛治理,为自己和家人缔造一个安全健康的居住环境!北京东城~西营房9号院儿童方案治理中#绿色亿家除甲醛# #除甲醛办法# '
……
# 循环查找,匹配多个‘’中的内容 法1:
pattern2 = re.compile(r'(?<=\')(.*?)(?=\')')
match = pattern2.findall(sum_weibos)
for i in match:
if i != ', ':
print('$$$', i, '\n)
"""
输出 :
$$$ 13~26度,多云,中度雾霾。;老北京的古老风俗不计其数,其中的民间行业活动有一番风味,说说老北京七十二行,吹糖人儿、耍蝈蝈·····现如今还流传与大街小巷,可大部分却巳被遗忘,甚至有人闻所未闻。现在我们就一起到那古色古香的胡同里去感受一下老北京当年的行行业业。;--珊姐谈天下 早安! 北京·华人一品大厦
$$$ 中雨过后还雾霾,机动车真牛逼 北京
$$$ 赵先生家装修完迟迟不敢入住经朋友推荐找到我们。新装污染记得先做下甲醛治理,为自己和家人缔造一个安全健康的居住环境!北京东城~西营房9号院儿童方案治理中#绿色亿家除甲醛# #除甲醛办法#
$$$ 赵先生家装修完迟迟不敢入住经朋友推荐找到我们。新装污染记得先做下甲醛治理,为自己和家人缔造一个安全健康的居住环境!北京东城~西营房9号院儿童方案治理中#绿色亿家除甲醛# #除甲醛办法#
……
"""
8、从文件中随机选取20行写入a.txt,剩余10行写入b.txt,该怎么写代码?——用于随机分train/test
import random
with open('input', 'r') as f:
lines = f.readlines()
with open('a.txt', 'w') as fa, open('b.txt', 'w') as fb:
for _ in range(20):
fa.write(lines.pop(random.randint(0, len(lines) - 1))) # list.pop(k)即是list删掉的第k个元素
fb.writelines(lines)
9、样本量问题:
样本量调试方法:
1、复制达到相当量
2、多的样本随机减量
3、文本顺序反向
10、搞清楚反斜杠和raw string的关系,现在感觉有点扯不清楚。。。不是我扯不清楚,是它俩本来就你搅我我搅你的。。。= =,再研究一下吧
11、正则—— \b
精确匹配:eg,\bhi\b只匹配hi, 不匹配him,history,high
1)、\b只能匹配字母、数字、汉字、下划线
2)、\b就近匹配,比如\bAB 匹配A,AB\b 匹配B;但如果只写一个\b或者在两个字母、数字、汉字、下划线之间有\b时就在所有字符或者两个字母、数字、汉字、下划线之间所有字符去逐个匹配
12、正则,match的group() 和 groups()

re.match.groups() 返回的是匹配到表达式里 括号()里的部分

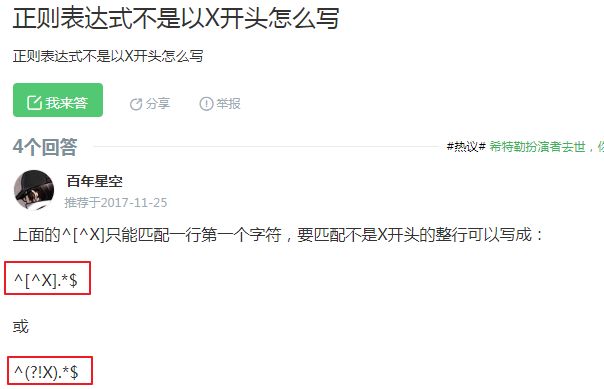
13、正则,匹配字符串以XX开头,或以XX结尾

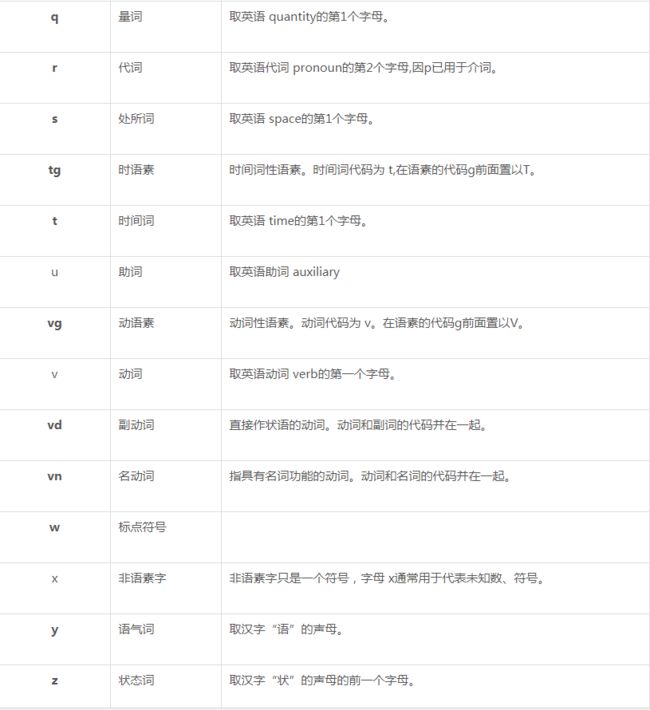
14、正则,不以X开头
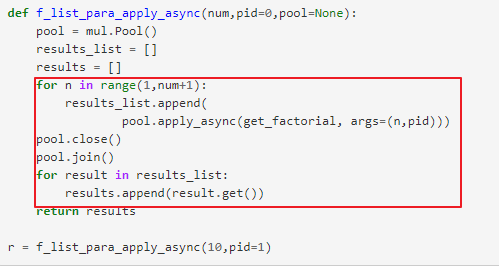
15、multiprocessing多进程,讲得非常清楚~~:https://morvanzhou.github.io/tutorials/python-basic/multiprocessing/5-pool/
http://cloga.info/python/2014/01/12/multiprocessingintro
多进程函数多参数的情况:

16、正则同时包含两个关键字:
