论文:https://arxiv.org/abs/1812.01866
代码:https://github.com/bingykang/Fewshot_Detection
1.研究背景
深度卷积神经网络最近在目标检测方面的成功很大程度上依赖于大量带有准确边界框标注的训练数据。当标记数据不足时,CNNs会严重过度拟合而不能泛化。计算机视觉系统需要从少量样本中进行检测的学习能力,因为一些对象类别天生就样本稀缺,或者很难获得它们的注释。
这种只有少量样本的检测称为few-shot目标检测问题。获得一个few-shot的检测模型对许多应用都是有用的。然而,目前任然缺乏有效的方法。最近,元学习为类似的问题提供了很多可行的解决方案。但是目前的一些模型都是用于few-shot分类,而目标检测在本质上要困难得多,因为它不仅涉及到类的预测,还涉及到目标的定位,因此现成的few-shot分类方法不能直接应用于few-shot检测问题。以匹配网络和原型网络为例,由于图像中可能存在无关类的分散注意力的对象或根本没有目标对象,如何构建匹配和定位的对象原型还不清楚。
2.本文解决方案
本文提出了一种新的检测模型,该模型通过充分利用一些基类的检测训练数据,并根据几个support examples快速调整检测预测网络来预测新的类,从而提供few-shot的学习能力。提出的模型首先从基类中学习元特征,这些基类可泛化为检测不同的对象类。然后利用一些support examples有效地识别出对检测新类有重要区别意义的元特征,并相应地将检测知识从基类转移到新类。
因此,本文的模型引入了一个新的检测框架(如图2所示),包含两个模块,即,元特征学习器和轻量级特征权重调整模块。给出一个query image和一些新类的support images,特征学习器从query image中提取元特征。权重调整模块学习捕获support images的全局特征,并将其嵌入到权重调整系数中,以调整query image的元特征。因此,query image的元特征能够有效地接收支持信息,并适应于新类的检测。然后自适应的元特征被送入检测预测模块中预测query的类和边界框。
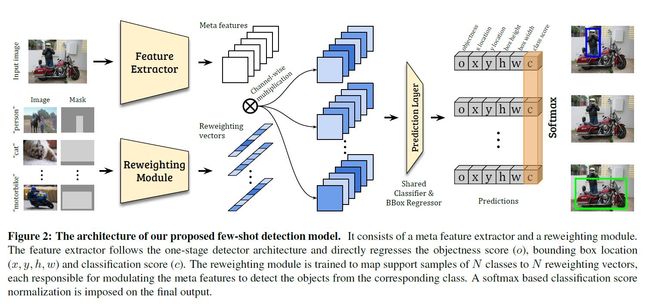
对元特征学习器和加权模块以及检测预测模块进行端到端的训练。为了保证few-shot的泛化能力,采用两阶段学习方案对整个few-shot检测模型进行训练:首先从基类中学习元特征和良好的权值调整模块;然后对检测模型进行微调以适应新的类。为了解决检测学习中的困难(例如,存在分散注意力的对象),它引入了一个新的损失函数。
3.方案具体实施
关于数据集
本文针对few-shot目标检测,设置了两种数据,即,基类和新类。基类包含丰富的带标签的样本,而新类只有少数带标签的样本。目标是通过利用基类的先验知识,使得模型能够在测试中检测新类的目标。
关于模型
该模型将元特征学习器D和权重调整模块M引入到一个one-stage检测框架中。通过检测预测模块P,将每个anchor的特征直接回归到检测相关输出,包括分类得分和目标边界框坐标(如图2所示)。模型采用YOLOv2的backbone(DarkNet-19)作为元特征提取器D,并遵循与YOLOv2相同的anchor设置。对于权重调整模块M,模型采用一个轻量级的CNN。
具体来说,让I表示一个输入的图像。其对应的元特征由D产生;F=D(I)。生成的元特征有m个特征映射。我们将表示要检测的目标类的support images及其相关的边界框注释分别表示为Ii和Mi(i表示不同的类,i = 1,…,N)。权重调整模块M以一个支持图像(Ii, Mi)为输入,将其嵌入到一个类特定的表示向量wi=M(Ii, Mi),它将负责调整元特征的权重,并突出更重要、更相关的特征,以检测来自类i的目标对象。具体来说,模型在获得类特定的权重系数wi后,通过以下方式应用它来获得新类i的特定特征Fi:
![]()
在获得类特定的特征Fi之后,我们将它们输入到预测模块P中,对每个预定义anchor的目标度评分o、bbox位置偏移量(x、y、h、w)和分类分数ci进行回归:
![]()
其中ci为one-vs-all分类得分,表示对应对象属于第i类的概率。
训练方法
训练分为两个阶段,第一阶段是基础训练阶段。在这个阶段,虽然每个基类都有丰富的标签,但是我们仍然会联合训练元特征学习器D,检测预测模块P和权重调整模块M。这是为了使它们以期望的方式进行协调:模型需要通过引用一个良好的重权向量来学习检测感兴趣的对象。第二阶段是少few-shot微调。在这个阶段,对模型进行基类和新类的联合训练。由于只有k个标记的边界框可用于新类,为了平衡来自基类和新类的样本,每个基类也只能包含k个box。训练过程与第一阶段相同,不同之处在于,模型收敛所需的迭代次数明显减少。
损失函数
损失函数为:
![]()
其中,
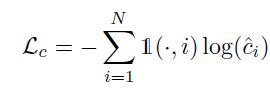
![]()
Lbbx和Lobj按照YOLOv2相同的计算方式。
4.实验过程和结果分析
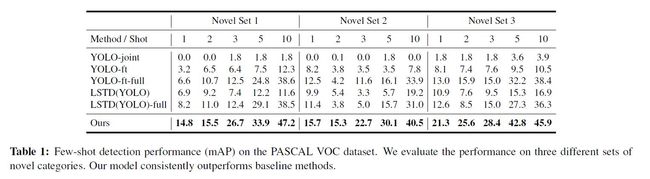
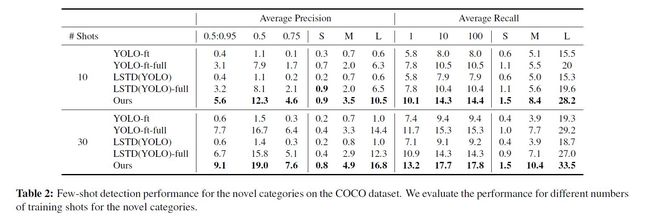
实验在Pascal VOC和COCO上分别进行了实验,实验对比了5个不同的baseline模型,结果分别如表1、表2所示:
比较结果分析
1) 本文模型表现都要好于其他模型
2) 本文所提出的二阶段的训练方式要优于一阶段的方式
3) 本文模型在各种不同的类别划分下表现都要优于其他模型
速度分析
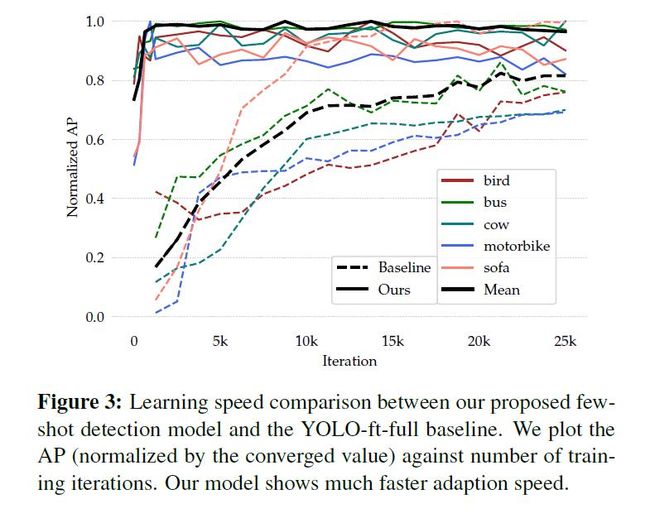
如图3所示,本文模型在微调阶段的收敛速度明显好于其他模型
元特征权值分析
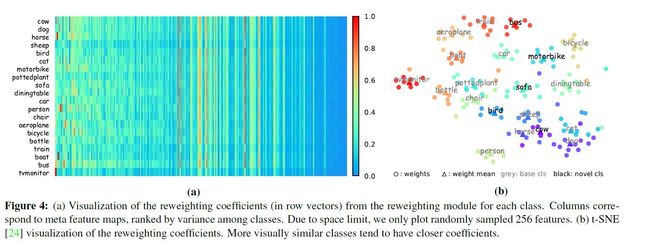
图4(a)所示,各个元特征在不同类目标中的权值不同,但其中有大约一半的特征在各个类中权重差不多,即,这些特征对于检测分类的重要性是极小的。
图4(b)所示,将各个目标的加权向量可视化,可以发现,同类目标的向量权值是十分接近的,而不同类目标,若是外形相似,其向量权值也比较接近,也就是说各个元特征在这些目标中的重要性很接近。
第一阶段过程分析
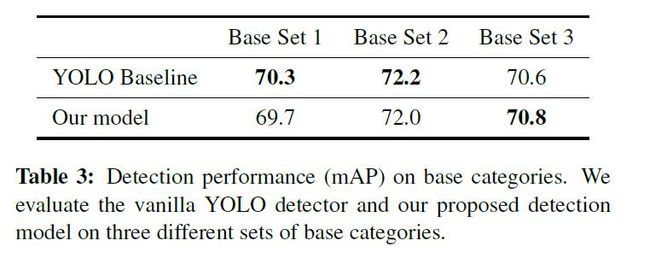
比较第一阶段训练后得到的模型在基类上的映射。结果如表3所示。尽管本文的检测器是为few-shot场景设计的,但它也具有强大的表示能力,以达到与在大量样本上训练的原始YOLOv2检测器相当的性能。
消融实验
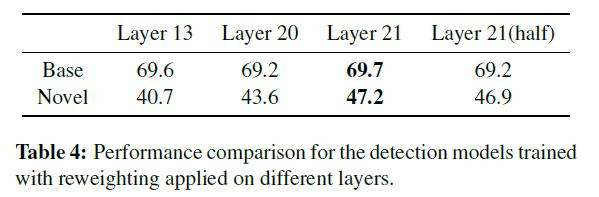
作者分别进行了3个实验,首先是在特征图的不同层上进行加权,结果如表4所示,在越深的层上进行加权效果越好。
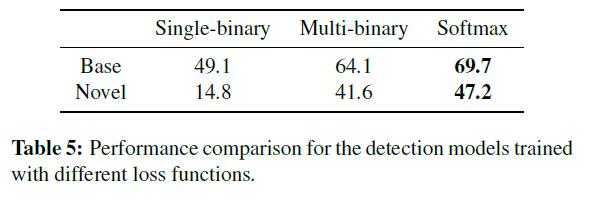
其次,采用不同的损失函数,结果如表5所示,在3种损失函数中,softmax的效果最好。
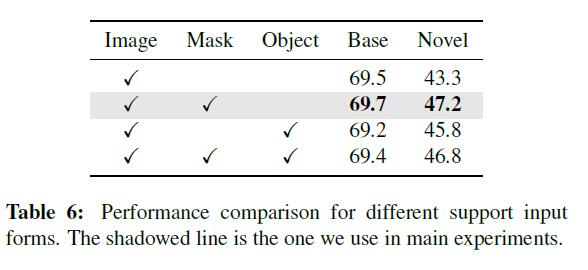
最后,support images选择不同输入形式,结果如表6所示,本文提出的对目标用mask进行标注的方式效果最好。
5.总结
这项工作是第一个探索实际和具有挑战性的few-shot目标检测问题。通过实例介绍了一种快速调整基本特征的贡献来检测新类的新模型。在实际基准数据集上的实验清楚地证明了它的有效性。该工作还比较了模型的学习速度,分析了预测的权重向量和每个设计组件的贡献,对所提出的模型提供了深入的理解。