/*
Hadoop是Apache旗下主流的大数据计算和存储框架之一,在近年来应用的越来越广泛。常规意义上的Hadoop集群都是搭建在商业服务器上的,利用大规模柜式服务器的强劲硬件资源进行大数据分布式计算。同时Hadoop是由Java编写的,运行在JVM之上。而Java是跨平台的,可以“run everywhere”,这就给在ARM平台上搭建Hadoop集群带来了希望。事实上,已经有多家大厂和个人爱好者做出了此类尝试,Cubieboard制作出了一个相当漂亮的8节点Hadoop集群(http://cubieboard.org/2013/08/01/hadoophigh-availability-distributed-object-oriented-platform-on-cubieboard/)。由于实际项目需求,我在64位ARM平台上搭建出了一个三节点的Hadoop集群。比算力当然比不过商业服务器,只作为一次有趣的尝试。
*/
0. 硬件资源和软件版本介绍
此案例中选用的嵌入式开发板型号是Firefly-RK3399,官网的产品介绍可点击http://www.t-firefly.com/product/rk3399.html。
硬件资源:
– Firefly-RK3399×3,6 核,2GHz主频,4GB DDR3 RAM,120G eMMC
– 散热风扇×3,用来超频后的散热
– HDMI 线×1,显示屏x1
– 4口路由器,修改设置当成交换机用,用来给3块开发板联网
– 网线×3
软件版本:
– 操作系统:Ubuntu16.04
– Java 环境:jdk for ARM 8u172
– Hadoop 2.7.6
1. 准备工作
1.1 配置本地hosts
规定集群一共有三台设备,一台主机和两台从机。主节点的主机名改成Master,两个从节点分别改成Slave1和Slave2。IP地址从192.168.1.50依次往后排到192.168.1.52(IP地址可以自定义)。若再增加一个从机,则继续添加slave节点。注意在每个设备上都要进行以下操作。
#进入hosts文件
sudo gedit /etc/hosts
#将以下内容添加到文本中:
192.168.1.50 Master
192.168.1.51 Slave1
192.168.1.52 Slave2
1.2 更改本机IP地址
在主机上执行以下操作,这里的网关和dns都是192.168.1.1,因为我最终连入互联网的那个路由器是192.168.1.1。若实际情况不同可作出相应修改。
#修改配置文件
sudo gedit /etc/network/interfaces
#在文本末尾添加以下内容:
auto eth0
iface eth0 inet static
address 192.168.1.50
netmask 255.255.255.0
gateway 192.168.1.1
dns-nameservers 192.168.1.1
#重启网络,使配置生效
sudo /etc/init.d/networkin restart
然后在各个从机上也按规定更改为对应的ip地址
使用ping指令在Master主机中进行测试,使用类似指令在Slave上测试,确保两两之间一定可以ping通。
ping -c4 Slave1
ping -c4 Slave2
1.3 更改主机名
为更直观的区分每个节点,修改每个设备的主机名。进入以下文件中
sudo gedit /etc/hostname
把原来的主机名删除
然后添加各自的主机名
Master 或者Slave1或者Slave2
2. 设置ssh免密码登录
因为Hadoop各个节点之间的管理通信使用的是ssh,所以要求主节点必须能够ssh免密登录到所有从节点。下面配置root用户下的ssh免密登录,所有操作都是在root权限下。
2.1 修改sshd_config配置
gedit/etc/ssh/sshd_config
#在文件中添加:
RSAAuthentication yes
PubkeyAuthentication yes
#然后把PermitRootLogin prohibit改成
PermitRootLogin yes
#重启ssh服务:
sudo /etc/init.d/ssh restart
2.2 生成key
ssh-keygen -t rsa
一直回车,/root就会生成.ssh文件夹。
2.3 合并公钥到authorized_keys文件
cd /root/.ssh
cat id_rsa.pub >> authorized_keys
这时就能在本机免密码登录。
ssh localhost
2.4 在从机上进行1、2、3步实现本机免密码登录
2.5 拷贝key
#把Master的authorized_keys、known_hosts、id_rsa.pub通过ssh复制到Slave1和Slave2的/root/.ssh目录。
scp authorized_keys known_hosts id_rsa.pub root@Slave1:/root/.ssh
scp authorized_keys known_hosts id_rsa.pub root@Slave2:/root/.ssh
2.6 完成之后在主机上重启ssh服务后即可免密码登录
service ssh restart
2.7 检证免密登陆
ssh Slave1
ssh Slave2
至此,免密登录的工作已经完成
3. 安装Hadoop
3.1 将安装包下载到Master上,/usr/local/目录下,解压
tar -zxvf hadoop-2.7.6.tar.gz
3.2 将解压出来的文件夹改名为hadoop
mv hadoop-2.7.6 hadoop
3.3 在/usr/local/hadoop目录下创建数据存放的文件夹tmp
mkdir tmp
3.4 配置core-site.xml
此文件是Hadoop的核心文件
gedit/usr/local/hadoop/etc/hadoop/core-site.xml

3.5 配置hdfs-site.xml
此配置文件设置hdfs的一些属性。dfs.namenode.secondary.http-address是主节点的IP地址和端口号;dfs.replication是备份系数,指每个block在hadoop集群中有几份,系数越高,冗余性越好,但是占用存储也越多,默认为3,可以设置为和从节点数相同;dfs.namenode.name.dir和dfs.datanode.data.dir规定了主节点保存整个文件系统的文件目录树的目录。dfs.socket.timeout是hdfs的读写超时时间限制。
gedit/usr/local/hadoop/etc/hadoop/hdfs-site.xml

3.6 配置mapred-site.xml
这是规定MapReduce计算属性的文件。mapreduce.framework.name规定采用yarn资源管理器进行分布式计算时的资源调度;下面两个属性与历史任务查看有关。
gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml

3.7 配置yarn-site.xml
gedit/usr/local/hadoop/etc/hadoop/yarn-site.xml

此文件规定了yarn调度器的一些参数。yarn.resourcemanager.hostname写主节点(namenode)的主机名;yarn.nodemanager.resource.memory-mb是分布式集群分配给yarn的最大内存空间,单位是MB,此参数要按照集群的具体情况设置,本集群三个设备内存均是4GB,酌情分配2/3左右,此值必须大于1024,否则影响进程。
3.8 配置Hadoop环境属性
修改/usr/local/hadoop/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,不设置的话,启动不了:
export JAVA_HOME=/usr/local/java
3.9 配置slaves
gedit /usr/local/hadoop/etc/hadoop/slaves
删除默认的localhost,增加从节点:
Slave1
Slave2
注意:若再增加一个从机,再继续添加slave主机名
3.10 配置环境变量:
gedit~/.bashrc
添加:
#HADOOP
exportHADOOP_HOME=/usr/local/Hadoop
exportPATH=$PATH: /usr/local/hadoop/bin:/usr/local/hadoop/sbin
使配置生效:
source~/.bashrc
3.11 传送Hadoop至其它节点
(从机不需下载安装包,由主机传送过去即可,环境变量从机要配置)
将配置好的Hadoop复制到各个节点对应位置上,通过scp传送:
scp -r/usr/local/hadoop root@Slave1:/usr/local/
scp -r/usr/local/hadoop root@Slave2:/usr/local/
3.12 启动Hadoop
在Master服务器启动hadoop,从节点会自动启动。
进入/usr/local/hadoop目录,初始化,输入命令:
(格式化只能在搭hadoop的时候在主机初始化一次,后来添加的从节点只能在slave上自己启动,不能进行格式化):
bin/hdfsnamenode -format
(1)在主机上全部启动:
sbin/start-all.sh
(2)添加从节点的时候在从机上自己启动:
/usr/local/hadoop/sbin/hadoop-daemon.shstart datanode
/usr/local/hadoop/sbin/yarn-daemon.shstart nodemanager
3.13 验证Hadoop
1.jps运行成功结果:

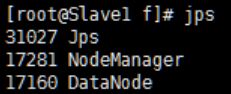
2.测试Web访问:
http://Master:50070/
致谢
安装过程中参考了
https://yq.aliyun.com/ziliao/60550
https://blog.csdn.net/laohuang1122/article/details/9953083
等多篇文章,以及来自项目组小伙伴的指导,感谢他们的付出!
Hear me roar!