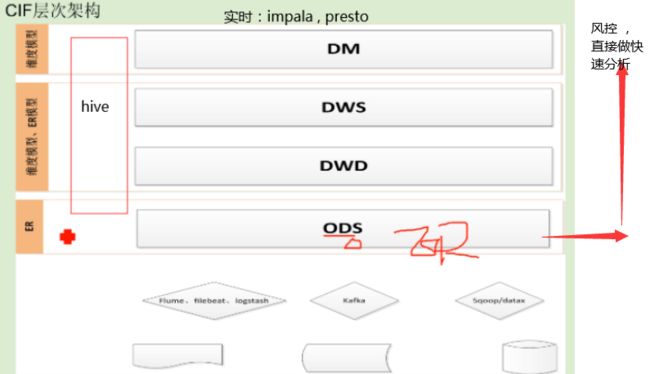
ODS:数据 来源 : 一部分是来自关系型数据库,符合ER模型 。一部分来自日志 ,清洗成二维表
DWD: 把所有的数据清理整合 ,规范化 。脏数据清理 ,命名不规范的。最后拿到的是干净的 ,一致性的数据 。
把公共维度抽取出来,如区域
DWS: 维度建模,通用的汇总层 ,为了避免重复计算。 DWS的表底层可能依赖DWD或ODS层的几十张表。所以从ETL性能出发要考虑DWS层表的数量和依赖 。
DM:指标库 ,集市是面向分析的
清洗过程: ODS清洗脏数据到DWD, DWD汇总到DWS,DWD到DM做指标。

维度 :
维度,顾名思义,看待事物的角度。比如时间日期 、区域、部门 、客户、应用程序等 维度 ,而省、市、县又叫维度的粒度,粒度可以是一组组合:比如我要看某个省某个市下某个县年龄在28岁以下的购买能力。
维度表一般为单一主键,在ER模型中,实体为客观存在的事物,会带有自己的
描述性属性,属性一般为文本性、描述性的,这些描述被称为维度
比如商品,单一主键:商品ID,属性包括产地、颜色、材质、尺寸、单价等,
但并非属性一定是文本,比如单价、尺寸,均为数值型描述性的,日常主要的维
度抽象包括:时间维度表、地理区域维度表等
维度设计:
代理键
缓慢渐变维
事实表设计:
明细事实表
聚合事实表
代理键:
维度表中必须有一个能够唯一标识一行记录的列,通过该列维护维度表与事实表之间的关系,一般维度表中业务主键符合条件可以当作维度主键。
当整合多个数据源的维度时,不同数据源的业务主键重复怎么办?
比如下图:
原有业务主键id,整合后发生重复。此时引入一个新的和业务无关的键(代理建),并且在整个维度表中是全局唯一的,而且通常情况下自增的方式来做的
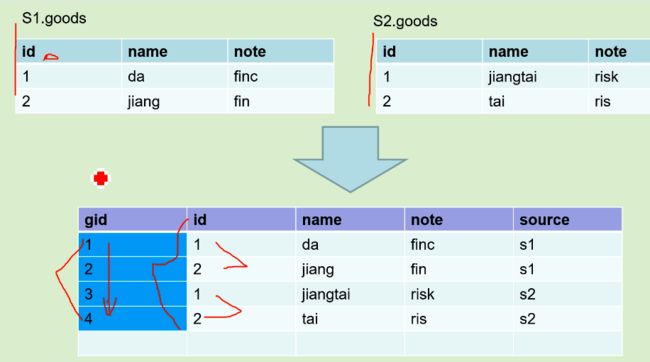

传统数据库有自增id默认功能,但hive中怎么生成自增的代理键?

表命名规则:
-i结尾: 流水型的纯增量的
-d结尾: 快照的
-a结尾: 全量没有任何分区
维度有分为:
1/ 稳定维度:
如时间,区域等,不发生变化或很少发生变化.针对这种维度,设计维度表时,仅需要完整的数据,不需要天的快照数据,因为当前数据状态即是历史数据状态.
2/ 缓慢渐变纬度
维度数据会随着时间发生变化,变化速度比较缓慢.由于数据仓库需要追溯历史变化,尤其是一些重要的数据,所以历史状态也需要采取一定的措施进行保存.
两种方法:
a. 每天保存等钱数据的全量快照数据,适合数据量较小的维度,使用简单.
b. 在维度表中添加官军属性值的历史字段,仅保留上一个的状态值. (复杂,不常用)
c. 拉链表
当维度数据发生变化时,将旧数据置为失效,将更改后的数据当作新的记录,插入到维度表中,并开始生效,这样就记录了数据在某种粒度上的变化历史.
比如: 员工的部门变化

因为是对维度表做拉链,所以同一维度实体必然存在多条记录,此时维度表的原子性主键就不存在了.如上表中的两条记录id都是1
那么拉链表怎么和事实表关联?
引入代理键:
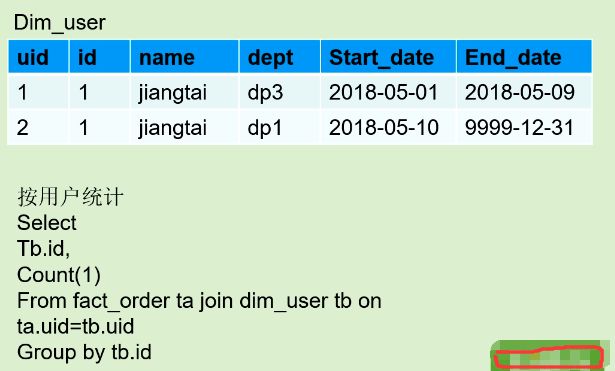
问题:事实表来源于业务事务表,代理键和业务本身没有关系,那么怎么在事实表中装载代理键?
D:\数据仓库\PART3\09 数据仓库维度建模\数据仓库维度建模2.mp4
小结:
代理键是维度建模中极力推荐的方式,它的应用能有效隔离源端变化带来的数仓结构不稳定问题,同时也能提高数据检索性能.
但,代理键维护代价非常高,尤其是数据装载过程中,对事实表带来较大的影响,如代理键的生成、事实表中关联键的装载、不支持非等值关联等问题,带来ETL过程更加复杂。
所以,谨慎使用代理键,同时对缓慢渐变维场景,可以考虑每天保留维表全量快照,但这样会带来存储成本,根据实际情况衡量。
案例:
中间的是主表,右边是财务关心的,左边是技术部关心的

事实表设计:
1/ 明细事实表,一般在dwd层
2/ 聚合事实表,一般在dws(轻度汇总)和DM
明细事实表:
事实表有粒度大小之分,一般在dwd层,该层事实表设计部进行聚合、汇总动作,只做数据规范化、数据降维动作,同时数据保持业务事务粒度,确保数据信息无丢失。
数据降纬:
为了提高模型易用性,将常规维度表中的常用的属性数据冗余到相应的事实表中,从而在使用时避免维表关联的方式,
如下图,中间就是事实表,如果要做区域商品购买力分析,把常住地等也放到事实表中,这就是降维的过程。以后在使用事实表时就不用再和维度表再做关联。
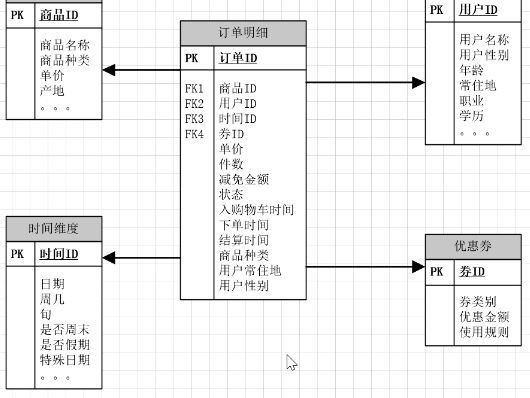
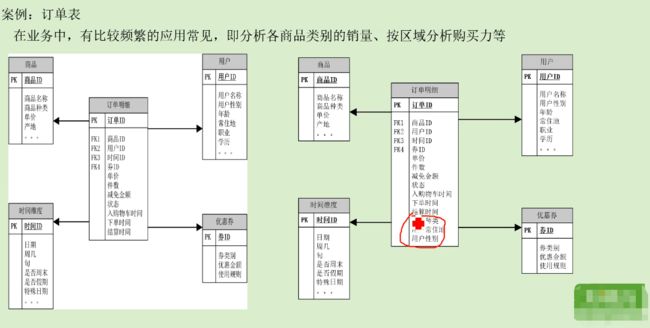
明细事实表设计:


案例:
出行,用户下单打车,该订单的整个流程包括用户下单、司机接单、司机做单、乘客支付,可能还伴随有评价、投诉等环节,这个场景的明细表怎么设计?
设计维度,要求业务侧记录这些事实:

采集成这么一张事实表:
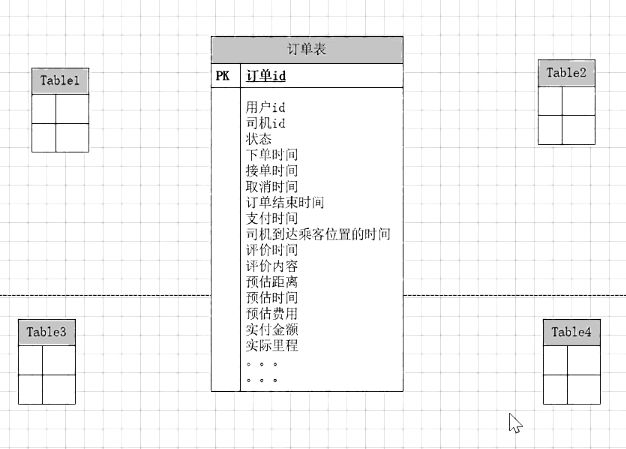
事实表的存储设计:

注意用拉链表要是缓慢变化,如果变化特别快,比如每天变一次,那12天就会产生12张拉链表,可能存储量比全量快照还大。
案例: D:\数据仓库\PART3\09 数据仓库维度建模\数据仓库维度建模7.mp4
信用卡场景,由于用户的信用额度、已用额度存在缓慢的变化,又需要跟踪变化的记录,设计相关事实表。
源数据包括用户id、卡id、已有额度、剩余额度、创建时间、更新时间

聚合事实表:

可累加事实:
在一定的粒度范围内,可累加的事实度量,比如:订单金额、订单数等
不可累加事实:
在更高粒度上不可累加的事实,比如通过率、转换率、下单用户。
明细表的不用考虑粒度,它就是最小粒度.


实例:
按照出行订单明细事实表,构建数据仓库上层模型。
解:
到订单粒度--->到用户粒度(粒度粗一些)--->司机粒度
所以从下面表中可以看到:
比如订单表有2000万个订单,可能到用户表就1500万个用户,到司机表就可能更少。所以有了聚合表后,衡量、选择从哪张表里去计算数据,就不用每天去遍历所有数据。
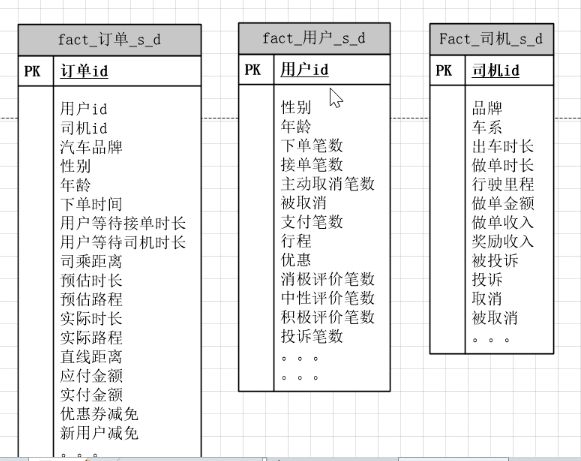
汇聚用户画像用到的表::

日报(时间纬度)
区域

数据集市的设计:
实际上数据仓库是包括数据集市的,而且物理上是统一、非隔离的。并不是说我们单独要建一个数据集市,是一个逻辑概念.
