-
堆和栈的区别
1、管理方式:
对于栈:是由编译器自动管理,无需我们手工控制;
对于堆:释放工作由程序员控制,容易产生memory leak。
2、申请大小:
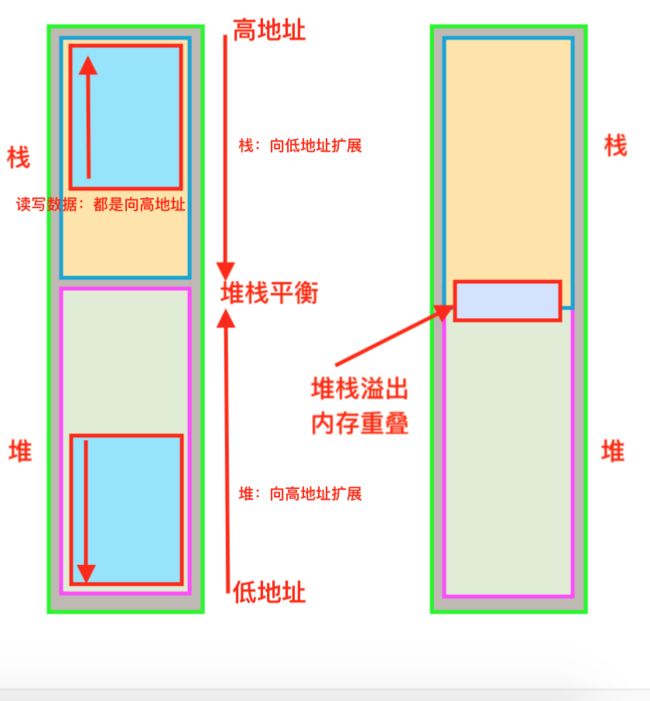
2.1 栈(stack):在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
2.2 堆(heap):堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.3 碎片问题:
对于堆:频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。
对于栈:则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出
3、分配方式:
堆:都是动态分配的,没有静态分配的堆。
栈:有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
4、分配效率:
堆:则是C/C++函数库提供的,它的机制是很复杂的。
栈:是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。
具体理解如下图:
-
哈希表(Hash table)
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hashtable(key,value):就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字即哈希值,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
哈希表: 的本质是一个数组,数组中每一个元素称为一个箱子(bin),箱子中存放的是键值对。数组长度即箱子数。
哈希表还有一个重要的属性: 负载因子(load factor),它用来衡量哈希表的 空/满 程度,一定程度上也可以体现查询的效率,计算公式为:
负载因子 = 总键值对数 / 箱子个数
负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。因此,一般来说,当负载因子大于某个常数(可能是 1,或者 0.75 等)时,哈希表将自动扩容。
哈希表在自动扩容时,一般会创建两倍于原来个数的箱子,因此即使 key 的哈希值不变,对箱子个数取余的结果也会发生改变,因此所有键值对的存放位置都有可能发生改变,这个过程也称为重哈希(rehash)。
哈希表的扩容并不总是能够有效解决负载因子过大的问题。假设所有 key 的哈希值都一样,那么即使扩容以后他们的位置也不会变化。虽然负载因子会降低,但实际存储在每个箱子中的链表长度并不发生改变,因此也就不能提高哈希表的查询性能。
基于以上总结,有哈希表的两个问题:
1、如果哈希表中本来箱子就比较多,扩容时需要重新哈希并移动数据,性能影响较大。
2、如果哈希函数设计不合理,哈希表在极端情况下会变成线性表,性能极低。
二:时间复杂度
时间复杂度是一个偏理论的概念,我们要描述它,首先需要了解它的描述方法,即:「大 O 表示法」。
其实大 O 表示法的意思挺简单的,就是表示:随着输入的值变化,程序运行所需要的时间与输入值的变化关系。如果不理解也没关系,我们看两行代码就很容易懂了。
/* --------------------- 复杂度 ---------------------
1、时间复杂度
执行指令的次数,执行代码的次数
2、空间复杂度
对内存的消耗,主要看堆空间的消耗
常量次数忽略不计,n无穷大
//1、O(n1) = 2n + 3 == 2n
//2、O(n2) = n + 1 == n
//3、O(n3) = 1
这里 2n 可以等于 n,即O(n1) == O(n2)
*/
我们先看第一个代码,这是一个函数,输入一个数组,输出这个数组里元数的和。
int count(int a[], int n) {
int result = 0;
for (int i = 0; i < n; ++i) {
result += a[i];
}
return result;
}
对于这个程序来说,如果它处理 N 个元素求和所花的时间是 T,那么它处理 N2 个元素的和所花的时间就是 T2。所以随着 N 变大,时间 T 的变大是与 N 呈「线性」关系的。
在时间复杂度中,我们用 O(N) 表示这种「线性」时间复杂度。
那是不是所有的函数都是「线性」关系的呢?我们再来看下面的程序。这是一个二分查找程序,从一个有序数组中寻找指定的值。
int binary_search(int A[], int key, int imin, int imax)
{
if (imax < imin) {
return KEY_NOT_FOUND;
} else {
int imid = midpoint(imin, imax);
if (A[imid] > key)
return binary_search(A, key, imin, imid - 1);
else if (A[imid] < key)
return binary_search(A, key, imid + 1, imax);
else
return imid;
}
}
对于这个程序来说,如果它处理 N 个元素求和所花的时间是 T,那么它处理 N 2 个元素的和所花的时间是多少呢?是 T 2 吗?
如果头脑算不清楚,我们可以拿实际的数字来实验,二分查找每次(几乎)可以去掉一半的候选数字。所以假如 N = 1024,那么它最多要找多少次呢?答案是 10 次,因为 2^10 = 1024,每次去掉一半,10 次之后就只剩下唯一一个元素了。
好,这个时候,如果元素的个数翻一倍,变成 2048 个,那么它最多要找多少次呢?相信大家都能算出来吧?答案是 11 次,因为 2 ^ 11 = 2048。
所以在这个例子中,输入的元素个数虽然翻倍,但是程序运行所花的时间却只增加了 1,我们把这种时间复杂度要叫「对数」时间复杂度,用 O(logN) 来表示。
除了刚刚讲的「线性」时间复杂度和「对数」时间复杂度。我们还有以下这次常见的时间复度数。
「常数」时间复杂度,例如返回一个有序数组中的最小数,这个数因为始终在第一个位置,所以就不会受到数组大小的影响,无论数组多大,我们都可以在一个固定的时间返回结果。
「线性对数」时间复杂度,即 O(N*logN),这个复杂度比较常见,因为常见的高效的排序算法,都是这个时间复杂度,比如快速排序,堆排序,归并排序等。
别的时间复杂度还有很多,每个具体的问题,我们都可以通过具体的分析,得到这个问题的时间复杂度。
总结一下学习时间复杂度的知识对于我们的工作有什么用:
1、对于不同的数据规模,能够决策采用不同的解决方案。
2、了解什么情况下用暴力解法就能够解决问题,避免写复杂的代码。
3、在写代码之前,就能够预估程序的运行时间,从而可以知道是否能够满足产品需求。
4、在程序出现性能瓶颈时,能够有解决方案而不是抓瞎。
-
常见的数据结构
• 线性表(数组 链表 栈 队列)
• 树
• 图
逻辑结构
数据结构从逻辑上看,分为下面几种结构:
1、集合结构
这种结构注意看,里面有很多元素,但是这些元素之间是没有什么关系的 类似我们OC里面的NSSet、NSMutableSet
2、线性结构
线性结构有什么特点呢?他们是有顺序的.这种是不是见过,我们OC中的NSArray NSMutableArray都是线性结构的
3、树状结构
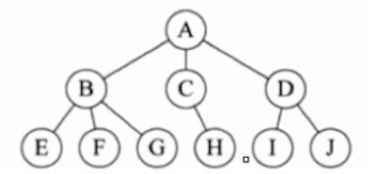
树状结构是一个或多个节点的有限集合。A为根节点,因为它最大! D是I&J的父节点.I和J他们是兄弟节点.
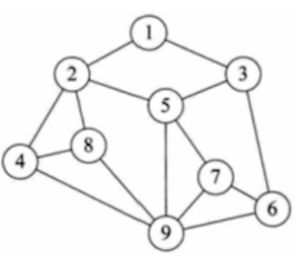
4、图形结构
图形结构简称"图",是一种相对复杂的数据结构.任意两个节点之间都可以关联.
存储结构确认
数据结构从逻辑上可以分为上面几种,但是这些数据统统都是要存放到内存里面去的,那么内存中存放数据也有不一样的结构.
• 顺序存储结构:遍历快、查找快、效率高
这组存储单元内存地址是连续的.

• 链式存储结构:添加快、删除快、(要有双向地址,操作时传入节点即可)
这组存储单元内存地址可以是连续的,也可以是不连续的.它不要求逻辑上相邻的元素在物理位置上也相邻.
线性表
什么是线性表
线性表就是多个具有相同特性的数据元素(节点)组成的,有限而且有序的集合
当线性表的节点个数为0时,我们称之为空表
线性表第一个元素称为首节点,最后一个元素称为尾节点
比如某个线性表的元素a1 a2 a3 a4 ......a99 。那么a1...a98 都是a99的前驱,a98是a99的直接前驱
比如某个线性表的元素a1 a2 a3 a4 ......a99 。那么a2...a98 都是a1的后继,a2是a1的直接后继
· 线性表的顺序存储结构
用一组地址连续的存储单元依次存储线性表的数据元素
· 线性表的链式存储结构
用一组任意的存储单元存储线性表中的数据元素,它的存储单元可以是连续的,也可以是不连续的
链式存储的线性表,简称链表。
链表:由多个链表元素组成,这些元素称为节点。结点之间通过逻辑连接,形成链式存储结构。存储结点的内存单元,可以是连续的也可以是不连续的。逻辑连接与物理存储次序没有关系。
**链表分为两个域: **
值域:用于存放结点的值
链域:用于存放下一个结点的地址或位置
从内存角度出发: 链表可分为 静态链表、动态链表。
从链表存储方式的角度出发:链表可分为 单链表、双链表、以及循环链表。
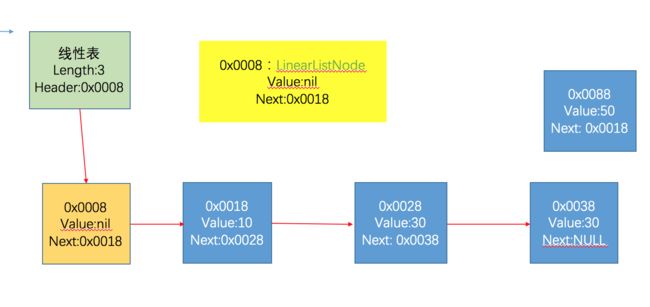
1、静态链表:
把线性表的元素存放在数组中,这些元素可能在物理上是连续存放的,也有可能不是连续的,它们之间通过逻辑关系来连接,数组单位存放链表结点,结点的链域指向下一个元素的位置,即下一个元素所在的数组单元的下标。显然静态链表需要数组来实现。
引出的问题:数组的长度定义的问题,无法预支。
2、动态链表:(实际当中用的最多)
改善了静态链表的缺点。它动态的为节点分配存储单元。当有节点插入时,系统动态的为结点分配空间。在结点删除时,应该及时释放相应的存储单元,以防止内存泄露。
3、单链表:
单链表是一种顺序存储的结构。
有一个头结点,没有值域,只有连域,专门存放第一个结点的地址。
有一个尾结点,有值域,也有链域,链域值始终为NULL。
所以,在单链表中为找第i个结点或数据元素,必须先找到第i - 1 结点或数据元素,而且必须知道头结点,否者整个链表无法访问。
4、循环链表:
循环链表,类似于单链表,也是一种链式存储结构,循环链表由单链表演化过来。单链表的最后一个结点的链域指向NULL,而循环链表的建立,不要专门的头结点,让最后一个结点的链域指向链表结点。
循环链表与单链表的区别
区别一:链表的建立。单链表需要创建一个头结点,专门存放第一个结点的地址。
单链表的链域指向NULL。而循环链表的建立,不要专门的头结点,让最后一个结点的链域指向链表的头结点。
区别二:链表表尾的判断。单链表判断结点是否为表尾结点,只需判断结点的链域值是否是NULL。
如果是,则为尾结点;否则不是。
而循环链表盘判断是否为尾结点,则是判断该节点的链域是不是指向链表的头结点。