下篇:
神经机器翻译概览:基准模型与改进(下)
介绍一下当前机器翻译领域很火的神经机器翻译(Neural Machine Translation ,简称NMT)领域的大致状况,最近的一些进展(内容主要来自Philipp Koehn的 Statistical Machine Translation 还未发布的草稿,想了解更详细内容,读原文)。
首先什么是机器翻译?
显而易见就是用机器来翻译,这里机器说的是计算机了。终极目标是抢走翻译们的饭... 噢,不对,是消除人们的交流沟通障碍,促进世界人民大团结!
那神经机器翻译又是什么鬼?
首先机器翻译是个大目标,达到目标有很多种方法。比如说神经机器翻译之前,很流行用统计方法来搭建机器翻译系统,这叫做统计机器翻译 (Statistical Machine Translation SMT)。
同样的如果用神经网络方法来达成机器翻译这个目标,那么就叫神经机器翻译。
为什么现在神经机器翻译很火呢?
第一,在自然语言处理中,机器翻译是一个高级问题,这意味着解决这个问题,还能顺带把方法用到很多其他问题上去。比如说现在广泛使用的注意力机制 (Attention Mechanism),最早就是先在机器翻译系统使用的。并且机器翻译非常实用,想想你看不懂论文时打开谷歌翻译时,就知道了。

第二,还有现在深度学习大火,神经网络也确实在机器翻译上取得很好的成绩,比起之前统计机器翻译中效果最好的模型(基于短语的统计机器翻译模型)都能强出很多。这也是为什么现在谷歌翻译基本上都已经换成神经机器翻译模型了。
好了,这就是背景知识了。那么先来讲讲现在使用最普遍的基准模型吧。
基准模型(seq2seq+attention)

现在最常用的基准模型如上图,主体部分主要由三部分组成,编码器(Encoder)、解码器(Decoder)、还有注意力机制(Attention)。
编码器:编码器其实很好理解,就把它当做一个总结器,输入一段源语言句子(比如说英文的I love you.),那么编码器就是把这句话的信息总结出来。可以理解为人读完一句话,然后总结成一个模糊的意思。
解码器:然后解码器根据编码器传过来的信息,来把这个信息用目标语言表示出来,也就是翻译出来。

注意力机制:如果单靠一次总结后直接解码翻译的话,效果并不好。所以可以再像人一样,边翻译同时再回看源语言每个词的信息,之后也能知道更准确的词和词的对应关系。上图就是英法翻译时,词对应情况。
之后输入输出部分就主要由词向量表和预测模块组成了。
整个翻译流程像这样,输入源语言(比如说汉语),转换成词向量,传入编码器编码总结,然后传给解码器,解码器通过注意力机制,一个词一个词,边参考源语言信息边翻译成目标语言(比如说英语),最后用到柱搜索 (Beam Search,感兴趣自己去搜搜看) 算法选出最好的备选翻译。
这就是目前神经机器学习的基准模型了。
基准模型学习资源(流行框架):
- TensorFlow NMT Tutorial
- PyTorch NMT Tutorial
基准模型改进
当然这个领域还在不停地发展,因此每年也会不断有很多提高基准模型的方法被发表出来,特别是在每年WMT(相当于机器翻译领域每年的华山论贱)大赛上都会有队伍将最有效地一些方法进行总结,然后实现到实际模型上来。
这些方法也都很有意思,之后就一一来介绍。
集成解码方法(Ensemble Decoding)
首先是比较容易理解的集成解码,实际上就是一句话人多力量大。
既然一个模型的准确率不行,那么就几个不同的模型一起用,因为每个模型可能都会有些差异,有不同的缺点,如果用多个模型的话,就能产生互补效应,获得更好的翻译效果。
但是集成也根据集成模型的不同分为以下几种。
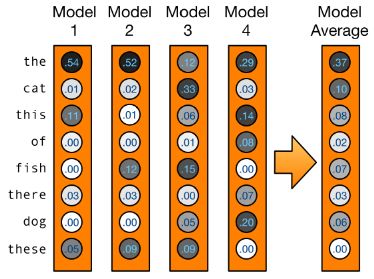
检查点(checkpoint)集成
检查点就相当于游戏中的存档点,将模型训练到一定程度,然后希望把当前模型的所有参数保持下来,以便之后使用。一般检查点会以epoch(整个数据集过一遍)、iteration(一次批训练更新权重)、或者句子数为单位,比如说epoch15模型就是训练完15个epoch的模型。
而检查点集成就是,用这些不同时间点保存下来的模型一起来预测。

多次运行 (Multi-run) 集成
多次运行集成有好几种情况。
可以是同一个模型,以不同的初始条件来运行,最后得到的多个模型;也可以是不同的模型,在用一个数据集上训练,最后得到的多个模型。
利用从右到左模型重排序解码
目前一般的解码器都是从左到右地一个词一个词地译出目标语言,所以一般RNN解码器都是单方向的,但编码器都是双方向以获得更多的信息。

为了让解码器也能利用双方向的信息,可以训练一个模型反过来翻译目标语言,从右到左输出结果,比如说“我爱你”翻译成英文,按这样的顺序来译“you -> love -> I.”。
之后用从右到左的模型输出的结果,来筛选从左到右模型输出的结果,就可以获得更好的翻译。
当然上面这些集成方法也可以都用上,一起集成输出结果当然更好,但同时也会导致运算成本过高的问题,毕竟一个模型训练下来就要很久了,更何况几个了。
处理大词汇量
对于NMT,其中一个最大的难题就是如何处理庞大的词汇量。
因为神经网络方法一般处理词汇是建立词向量表,之后通过查表将句子转换成词向量。也就是对于词向量表,每个不同的词就对应一个不同的向量。对于有些语言,因为形态学(Morphology)比较复杂,所以一个词可能会有很多很多种变形,即使意思并没差太多,这样的语言词汇量却会非常大。

对于编码器端,会导致词向量表非常大,同时因为可能某些形态的词在整个数据集中只出现很少的次数,所以会导致稀疏问题,某些词向量根本没得到充足的训练。
而对于解码器端,因为输出时会用softmax来进行概率输出,从目标语言词汇中挑选出合适的词。这会导致过大的计算量,也是一个大问题。
目前大家能想到的解决这个问题的方法是,使用**子词 (sub-word) **而不是词(Word)来进行翻译,比如说英文里面 unhappy = un + happy.
对于人来说,因为语言本能,这些都可以自然而然在脑中解构。但对于计算机就不行,得我们告诉它怎么做。
字节对编码 (Byte Pair Encoding, BPE) 法
现在使用比较广泛的一个方法是BPE法,因为爱丁堡大学的Nematus系统用这个取得了很好的效果。
原理的话出乎意料,和语言学没有关系,也并不是很难。主要步骤如下。
- 将训练数据中所有词都表示成字节,把这些字节加入符号表,最开始大概是a, b, c...还有各种符号;
- 然后统计符号对的出现频率,比如说th, zt...;
- 挑出其中频率最高的符号对,加入符号表,训练数据集中所有该符号对融合,比如说t和h全变成了th。这个叫做一次融合,之后重复2,3过程,直到指定的融合次数。
比如说爱丁堡大学在WMT16比赛中就用了89500次融合。完成这个BPE学习之后,用它来处理训练数据集,之后直接在bpe之间翻译,这样可以大大降低了词汇量。
使用单语言数据
机器翻译里面训练数据之所以难收集,主要是因为它用的是并列数据 (parallel data),也就是源语言和目标语言之间,一句话一句话得对应起来。因此准备数据的过程特别麻烦,所以对于深度学习这种数据越多越好的模型,有时候可能数据也并不够。
但同时另一方面,单独的语言数据我们又不缺,随便在网上抓一抓就很多很多。因此如何利用这些单语言数据就成了一个热门研究方向。
这里列举几个比较成功的方法。主要分为增加训练数据和训练语言模型来辅助翻译。
回译
回译的要点是,既然训练数据不足,那么就合成数据。但是怎么样合成呢?

这里假设我们有大量的目标语言单语言数据,那么为什么不建立一个反向的翻译系统,将这些目标语言翻译成源语言,之后再用获得的并行数据来训练所需要的系统呢。
这也是为什么这个技巧的名字叫做"回译 (Back Translation)"。
加入语言模型
首先什么是语言模型?一句话,训练一个模型,然后这个模型判断你说不说的是人话,这就是语言模型,很简单吧。
比方说我用脸打出来的“过以风格黑哦豆腐干会双方各黑分两个覅”就不是人话,你估计也不可能再在其他地方看到这样的句子了;而“我吃饭了”,这样正常的、有意义的、随处可见的话就是人话了。
而加入语言模型主要就是判断解码器翻译出来的是不是人话,从而帮助解码器获得更好的翻译效果。
至于如何学习怎么判断说的是不是人话,也就是训练语言模型,只要读书破万卷就可以了,把单语言数据丢给语言模型让自己训练就好了。
往返训练

最后是往返训练,就是把回译的技巧用来同时训练两个模型。比如上图一个模型是从 f->e(法译英),而另一个是反过来的英译法。
往返训练的流程是这样子的,假设我们有f单语言数据,那么先用正向模型翻译成e',之后用这个e‘和f来训练反向模型。当要用e的单语言数据,只要反过来操作就好了。
这样子两个好基友互相训练♂♂,最终就能都成为好模型。