Docker容器网络简析
参考:极客时间深入解析Kubernetes
Linux容器能看见的“网络栈”,实际上是被隔离在它的Network Namespace当中的。“网络栈”包括了网卡、回环设备,路由表和iptables规则。作为一个容器,也可以声明直接使用宿主机的网络栈(-net=host),即不开启Network Namespace。如果直接使用宿主机网络栈的化,虽然可以为容器提供良好的网络性能,但是会不可避免地引入共享网络资源的问题,比如端口冲突。大多数情况下,我们都希望容器进程能使用自己的Network Namespace,即拥有属于自己IP地址和端口。
单机模式下容器间的通信
可以把每一个容器都看作一台主机,它们有一套独立的“网络栈”。如果要实现多台主机之间的通信,就需用用网线把它们连接到一台交换机上。
Linux中,能够起到虚拟交换机作用的网络设备,就是网桥。它是一个工作在数据链路层的设备,主要功能是根据MAC地址学习来将数据包转发到网桥的不同端口。
Docker项目会默认在宿主机上创建一个名叫docker0的网桥,凡是连接在docker0网桥上的容器,都可以通过它进行通信。
docker容器通过一种名叫Veth Pair的虚拟设备“连接”到docker0网桥上。Veth Pair设备的特点:总是以两张虚拟网卡的形式成对出现。并且,从其中一个网卡发出的数据包,可以直接出现在与它对应的另一张网卡上,哪怕这两张网卡不在一个Network Namespace里。这使得Veth Pair常常被用作不同Network Namespace里的网线。
比如,现在我们启动一个叫做nginx-1的容器
[root@host1 ~]# docker run -d --name nginx-1 nginx
然后,我们进入这个容器,查看他的网络设备
# 在宿主机上
$ docker exec -it nginx-1 /bin/bash
# 在容器里
root@2b3c181aecf1:/# ifconfig
eth0: flags=4163 mtu 1500
inet 172.17.0.2 netmask 255.255.0.0 broadcast 0.0.0.0
inet6 fe80::42:acff:fe11:2 prefixlen 64 scopeid 0x20
ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet)
RX packets 364 bytes 8137175 (7.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 281 bytes 21161 (20.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
$ route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default 172.17.0.1 0.0.0.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
这个容器中有一张etho的网卡,它就是Veth Pair设备在容器的这一端。
通过查看路由表,可以看出所有对172.17.0.0/16网段的请求,也会交给eth0处理。
Veth Pair设备的另一端,在宿主机上可以通过宿主机的网络设备看到它,如下所示:
# 在宿主机上
$ ifconfig
...
docker0 Link encap:Ethernet HWaddr 02:42:d8:e4:df:c1
inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:d8ff:fee4:dfc1/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:309 errors:0 dropped:0 overruns:0 frame:0
TX packets:372 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:18944 (18.9 KB) TX bytes:8137789 (8.1 MB)
vethb4963f3 Link encap:Ethernet HWaddr 52:81:0b:24:3d:da
inet6 addr: fe80::5081:bff:fe24:3dda/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:288 errors:0 dropped:0 overruns:0 frame:0
TX packets:371 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:21608 (21.6 KB) TX bytes:8137719 (8.1 MB)
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242d8e4dfc1 no veth9c02e56
这时候,我们再在这台宿主机上启动一个Docker容器nginx-2:
$ docker run –d --name nginx-2 nginx
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242d8e4dfc1 no veth9c02e56
vethb4963f3
这时候,在nginx-1容器中访问nginx-2容器的IP地址(比如ping172.17.0.3)的时候,这个目的IP地址就会匹配到nginx-1中的第二条路由规则。这条规则的路由网关是0.0.0.0,这就意味着这是一条直连规则,即:凡是匹配到这条规则的IP包,应该经过本机的eth0网卡,通过二层网络直接发往目的主机。
要通过二层网络到达nginx-2容器,就需要有172.17.0.3这个IP地址的MAC地址。所以nginx-1容器的网络协议栈,就需要通过eth0网卡发送一个ARP广播,来通过IP地址查找对应二点MAC地址。(ARP是通过三层的IP地址找到对应二层MAC地址的协议)
eth0网卡是一个Veth Pair,它的一端在这个nginx-1容器的NetworkNamespace里,另一端位于宿主机上,并且被插在了docker0网桥上。一旦一张虚拟网卡被插在网桥上,它就会变为网桥的一个端口。这个端口的唯一作用就是接收流入的数据包,然后把这些数据包的处理操作全部交给对应的网桥。
所以在收到这些ARP请求后,docker0网桥就会扮演二层交换机的角色,把ARP广播转发到其他插在了docker0的虚拟网卡上。这样连接在docker0上的nginx-2容器的网络协议栈就会收到这个ARP请求,从而将172.17.0.3所对应MAC地址回复给nginx-1容器。
有了这个MAC地址,nginx-1容器的eth0网卡就可以将数据包发出去。
而根据Veth Pair设备的原理,这个数据包会立即出现在宿主机上的veth9c02e56。对于宿主机来说,docker0就是一个普通的网卡,所以对于docker0上流入的数据包,就会通过宿主机的网络协议栈进行处理。在宿主机上,docker0会为你设置如下所示的路由规则:
[root@host1 ~]# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
...
这次流入的数据包的IP地址是172.17.0.3,所以它出现在宿主机之后,就会按照上述这条路由规则,再次交给docker0网桥转发出去。docker0继续扮演二层交换机的角色,此时docker0根据数据包的目的MAC地址,在它的CAM表(交换机通过MAC地址学习维护的端口和MAC地址的对应表)里查到对应的端口为vethb4963f3,然后把数据包发往这个端口。
这个端口正是nginx-2容器在docker0网桥插的一块虚拟网卡,也是一个Veth Pair设备。这样,数据包就进入到了nginx-2容器的network namespace里。
nginx-2发现自己的eth0网卡流入了数据包,这样,nginx-2的网络协议栈就会对请求进行处理,最后将响应返回到nginx-1.
整个流程如下图所示:

容器跨主通信
Flannel项目
Flannel项目是CoreOS主推的容器网络方案。Flannel支持三种后端实现,分别是:
- VXLAN;
- host-gw
- UDP
UDP模式(已弃用)
UDP模式,是Fannel最早支持的一种方式,也是性能最差的一种,目前已经被弃用。这种模式是最直接,也是最容易理解的容器跨主网络实现。
本例中,有两台宿主机
- 宿主机Node1上有一个容器container-1,它的IP地址是100.96.1.2,对应的docker0网桥的地址是:100.96.1.1/24
- 宿主机Node2上有一个容器container-2,它的IP地址是100.96.2.3,对应的docker0网桥地址是:100.96.2.1/24
现在的任务就是让container-1访问container-2
container-1容器中的进程发起的IP包,其源地址就是100.96.1.2,目的地址就是100.96.2.3。由于目的地址100.96.2.3并不在Node1的docker0网桥对应的网段,所以这个IP包会交给默认路由规则,通过容器的网关进入docker0网桥,这时候,这个IP包的下一个目的地址,就取决于宿主机的路由规则。此时,Flannel已经在宿主机上创建了一系列的路由规则,以Node1为例,如下:
# 在 Node 1 上
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.1.0
100.96.1.0/24 dev docker0 proto kernel scope link src 100.96.1.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.2
由于我们Ip包的目的地址是100.96.2.3,所以只能匹配到第二条路由规则,进入一个叫做flannel0的设备。
flannel0设备
lannel0设备是一个TUN设备(Tunnel设备)。
TUN设备是一种工作在三层(Network Layer)的虚拟网络设备。TUN设备的功能很简单,即:在操作系统内核和用户应用程序之间传递IP包。
以flannel0设备为例:当操作系统将一个IP包发送给flannel0设备之后,flannel0就会把这个IP包,交给创建这个设备的应用程序,也就是Flannel进程。这是一个从内核态(Linux操作系统)到用户态(Flannel进程)的流动方向。
反之,如果Flannel进程向flannel0设备发送了一个IP包,那么这个IP包就会出现在宿主机的网络栈中,这是一个用户态向内核态的流动方向。
所以,当IP包从容器经过docker0出现在宿主机,然后又根据路由表进入flannel0设备后,宿主机上的flanneld进程(Flannel项目在每个宿主机上的主进程),就会收到这个IP包。然后flanneld进程看到了这个IP包的目的地址,是100.96.2.3,就把它发送给了Node2宿主机。
子网
flanneld是通过子网,知道这个IP地址对应的容器,是运行在Node2上的。
由Flannel管理的容器网络里,一台宿主机上的所有容器,都属于该宿主机被分配的一个“子网”。在我们的例子中,Node1的子网是100.96.1.0/24,container-1的IP地址是100.96.1.2。Node2的子网是100.96.2.0/24,container-2的IP地址是100.96.2.3。
这些子网与宿主机的对应关系,保存在etcd中。如下所示:
$ etcdctl ls /coreos.com/network/subnets
/coreos.com/network/subnets/100.96.1.0-24
/coreos.com/network/subnets/100.96.2.0-24
/coreos.com/network/subnets/100.96.3.0-24
所以,flanneld进程在处理由flannel0传入的IP包时,就可以根据IP的地址,匹配到对应的子网,从Etcd中找到这个子网对应的宿主机的IP地址是10.168.0.3,如下所示:
$ etcdctl get /coreos.com/network/subnets/100.96.2.0-24
{"PublicIP":"10.168.0.3"}
flanneld在收到container-1发给container-2的IP包之后,就会把这个IP包封装在一个UDP包中,然后发送给Node2。这个UDP包的源地址,就是flanneld所在的Node1的地址,目的地址,就是Container-2所在的宿主机Node2的地址。
每台宿主机上的flanneld,都监听着一个8252端口,所以flanneld只要把这个UDP包发往Node2的8252端口即可。
这样,一个UDP包就从Node1到达了Node2。Node2上负责监听8252端口的也是flanneld,这时候Node2上的flanneld就可以从这个UDP包里解析出封装在里面的、container-1发来的原IP包。然后flanneld会直接把这个IP包发送给它所管理的TUN设备,即flannel0设备。
这是一个用户态向内核态的流动方向,所以Linux内核网络栈就会负责处理这个IP包,具体的处理方法,就是通过本机的路由表来寻找这个IP包的下一步流向。
Node2上的路由表,如下所示:
# 在 Node 2 上
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.2.0
100.96.2.0/24 dev docker0 proto kernel scope link src 100.96.2.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.3
这个IP包的目的地址是100.96.2.3,它和第三条路由规则匹配,所以,Linux内核会将这个IP包准发给docker0网桥。
接下来的流程,就和单机模式一致了,docker0网桥扮演二层交换机的角色,将数据包发送给正确的端口,进而通过Veth Pair设备进入到container-2的Network Namespace中。
container-2返回给container-1的数据包,则会经过与上述相反的路径回到container-1中。
其流程如下图所示:

Flannel UDP模式提供的是一个三层的Overlay网络,即:它首先对发出端的IP包进行UDP封装,然后在接收端进行解封拿到原始的IP包,进而把这个IP包发送给目标容器。
UDP模式的性能问题
相比于两台宿主机直接通信,Flannel UDP模式的容器通信多了一个额外的步骤,即flanneld的处理过程。这个过程,由于使用到了flannel0这个TUN设备,仅在发出IP包的过程,就需要三次用户态与内核态之间的数据拷贝,如下:

第一次:用户态的容器进程发出IP包经过docker0网桥进入内核态。
第二次:IP包根据路由表进入TUN设备,从而回到用户态的flanneld进程;
第三次:flanneld进行UDP封包之后重新进入内核态,将UDP包通过宿主机的eth0发出去。
VXLAN模式
VXLAN,即Virtural Extensible LAN(虚拟可扩展局域网),是Linux内核本身就支持的一种虚拟化技术。所以说,VXLAN可以完全在内核态实现上述封装和解封的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络。
VXLAN的覆盖网络设计思想:在现有的三层网络之上,“覆盖”一层虚拟的、由内核VXLAN模块负责维护的二层网络,使得连接在VXLAN二层网络上的主机(虚拟机或者容器)之间,可以像在同一个局域网里自由通信。
为了能够在二层网络上打通隧道,VXLAN会在宿主机上设置一个特殊的网络设备作为“隧道”两端,这个设备叫做VTEP,即VXLAN TUN End Point(虚拟隧道端点)。
VTEP设备的作用和flanneld进程非常相似,只不过,它进行封装和解封装的对象是二层数据帧;这个工作流程,全部是在内核中完成的。(VXLAN本身就是Linux内核中的一个模块)。
流程图如下:

每台宿主机上名叫flannel.1的设备,就是VXLAN所需的VTEP设备,它既有IP地址,也有MAC地址。
现在,container-1的IP地址是10.1.15.2,container-2的IP地址是10.1.16.3
与UDP模式类似,当container-1发出请求之后,这个目的地址是10.1.16.3的IP包会首先出现在docker0网桥,然后被路由到本机flannel.1设备进行处理。也就是到了“隧道”的入口。
为了能够将“原始IP包”封装并发送到正确的宿主机,VXLAN就需要找到这条隧道的出口,即目的宿主机的VTEP设备。这个设备的信息,是由每台宿主机上的flanneld进程负责维护的。
比如,Node2启动并加入Flannel网络,在Node1以及其他节点上,flanneld就会添加一条如下所示的路由规则:
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
10.1.16.0 10.1.16.0 255.255.255.0 UG 0 0 0 flannel.1
即:凡是发往10.1.16.0/24网段的IP包,都需要经过flannel.1设备发出,并且,它最后发往的网关地址是:10.1.16.0
10.1.16.0对应的就是Node2上的VTEP设备的IP地址。
源VTEP设备收到原始数据包之后,就要想办法把原始数据包加上一个MAC地址,封装成一个二层数据帧,然后发送给目的VTEP设备。我们已经知道了目的VTEP设备的IP地址,要根据这个三层IP地址查询对应的二层MAC地址,这正是ARP表的功能。
有了目的VTEP设备的MAC地址,Linux内核就可以开始二层封包工作了。这个二层帧的格式,如下:
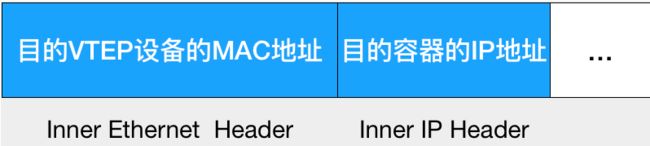
上述封包过程只是加一个二层头,不会改变原始IP包的内容。
上面提到的这些VTEP设备的MAC地址,对于宿主机网络来说没有什么实际意义。所以上面封装出来的数据帧,并不能在我们的宿主机二层网络里传输。我们把它称为内部数据帧。
接下来,Linux内核还需要把内部数据帧进一步封装成为宿主机网络里的一个普通数据帧,让它“载着”内部数据帧,通过宿主机的eth0网卡进行传输。我们把这次封装出来的数据帧称为外部数据帧。
为了实现这个“搭便车”的机制,Linux内核会在内部数据帧前面,加上一个特殊的VXLAN头,用来表示这个乘客实际上是一个VXLAN要使用的数据帧。
这个VXLAN头里有一个重要的标识叫做VNI,它是VTEP设备识别某个数据帧是不是应该归自己处理的重要标识。在Flannel中,VNI的默认值是1,这就是宿主机上的VTEP设备都叫做flannel.1的原因,这里的1就是VNI的值。
然后Linux内核会把这个数据帧封装成一个UDP包发出去。
一个flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址。其实,flannel.1设备扮演的就是一个网桥的角色,在二层网络之间进行UDP包的转发。在Linux内核里面,网桥设备转发的依据,来自一个叫做FDB(Forwarding Database)的转发数据库。这个flannel.1网桥对应的FDB信息,也是flanneld进程负责维护的。它的内容可以通过bridge fdb命令查看到,如下所示:
# 在 Node 1 上,使用“目的 VTEP 设备”的 MAC 地址进行查询
$ bridge fdb show flannel.1 | grep 5e:f8:4f:00:e3:37
5e:f8:4f:00:e3:37 dev flannel.1 dst 10.168.0.3 self permanent
这条规则的含义是:发往目的VTEP设备(MAC地址是5e:f8:4f:00:e3:37)的二层数据帧,应该是通过flannel.1设备,发往10.168.0.3的主机,这个主机就是Node2,UDP包的目的地就找到了。
接下来的流程,就是一个正常的,宿主机网络上的封包工作。
UDP包是一个四层数据包,Linux内核会在它前面加一个IP头,组成一个IP包。并且,在这个IP头里,回填上通过FDB查询出来的目的主机的IP地址。然后Linux内核再在这个IP包前面加上二层数据帧头,并把Node2的MAC地址填进去。

接下来,Node1的flannel.1设备就可以把这个数据帧从Node1的eth0网卡发出去,然后经过宿主机网络来到Node2的eth0网卡。
这时候,Node2的内核网络栈会发现这个数据帧里有VXLAN Header,并且VNI为1.所以linux内核会对它进行拆包,拿到里面的内部数据帧,然后根据VNI的值,把它交给Node2上的flannel.1设备。
flannel.1会进一步拆包,取出原始数据包。然后之后的流程就和单机模式类似了。